1、上面的日志是单节点的日志,另一个集群的日志和这个也差不多
2、没发现什么网络问题,如果有网络问题,这个集群上还有别的组件使用就会有问题了,这张截图是多节点的,单节点也是有这个问题
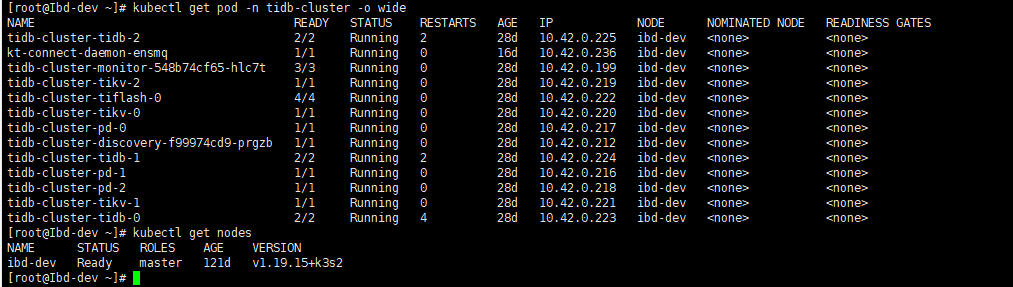
- 从以下日志看到,磁盘 slow
2022-01-17T07:29:29.467722352+08:00 stdout F [2022/01/16 23:29:29.467 +00:00] [WARN] [etcdutil.go:118] [“kv gets too slow”] [request-key=/pd/7023195418782655206/dc-location] [cost=1.424672652s] []
2022-01-17T07:29:31.567618746+08:00 stdout F [2022/01/16 23:29:31.567 +00:00] [WARN] [wal.go:712] [“slow fdatasync”] [took=2.167612539s] [expected-duration=1s]
2022-01-17T07:29:31.567649609+08:00 stdout F [2022/01/16 23:29:31.567 +00:00] [WARN] [raft.go:363] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=79f26393d1544e6c] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=1.482447134s] - 请问您的机器配置是如何的? helm 分配的 pod 资源是什么? pv 分配的是 nvme 吗?
- 麻烦检查下监控里磁盘使用情况,比如 TiKV-details 下面的 CPU/Memory/IOUtils/MBps 等,多谢。

- 方便给一下配置文件吗?
- 这个集群部署在单节点 1bd-dev 上的,磁盘是什么类型? cpu , 内存 是多少?
- 监控是单节点的无法展示吗? describe 或者 logs 看下 monitor pod 有什么报错吗?
heml部署文件
values.yaml (35.6 KB)
grafana报错日志,其他无报错
grafana.txt (10.5 KB)
单节点,总内存600G,存储67T,cpu总核数66核,磁盘是服务器专用的机械盘
做集群最重要的就是要把网络搞好
你好老师,问了研发,建议还是使用 operator 部署
1.“redirect but server is not leader” 一般发生在发送给 PD leader 的请求,接收后发现已经 step down 为 follower,出现这个问题的原因可能有发送请求时,有切换 leader 的动作,但日志中暂时没有发现 transfer leader 相关日志,但是有大量的 warning 报磁盘慢或者卡住导致 leader lease 过期,考虑到这边使用的磁盘类型为机械盘,建议调整为 SSD 磁盘;
2.helm install tidb-cluster 这种 Helm chart 管理 TiDB 集群的方式过于老旧,新版中已不建议这种部署方式,建议调整为TidbCluster CR + TidbMonitor CR 方式,参考:https://docs.pingcap.com/zh/tidb-in-kubernetes/stable/get-started#第-3-步部署-tidb-集群和监控
我一直是operator部署的
好的,我重新部署一遍

可以看下日志中是否有报错,同时也检查下配置文件中各参数和实际的值是否相同

helm install tidb-cluster 这种 Helm chart 管理的方式应该只有 1.0 的时候有文档 https://docs.pingcap.com/zh/tidb-in-kubernetes/v1.0/deploy-on-general-kubernetes#部署-tidb-集群 目前不推荐这样部署。建议使用 TidbCluster CR + TidbMonitor CR 部署。
可以参考
【SOP 系列 15】如何在 Kubernetes 上部署 TiDB-Operator (上)
【SOP 系列 15】如何在 Kubernetes 上部署 TiDB-Operator (下)
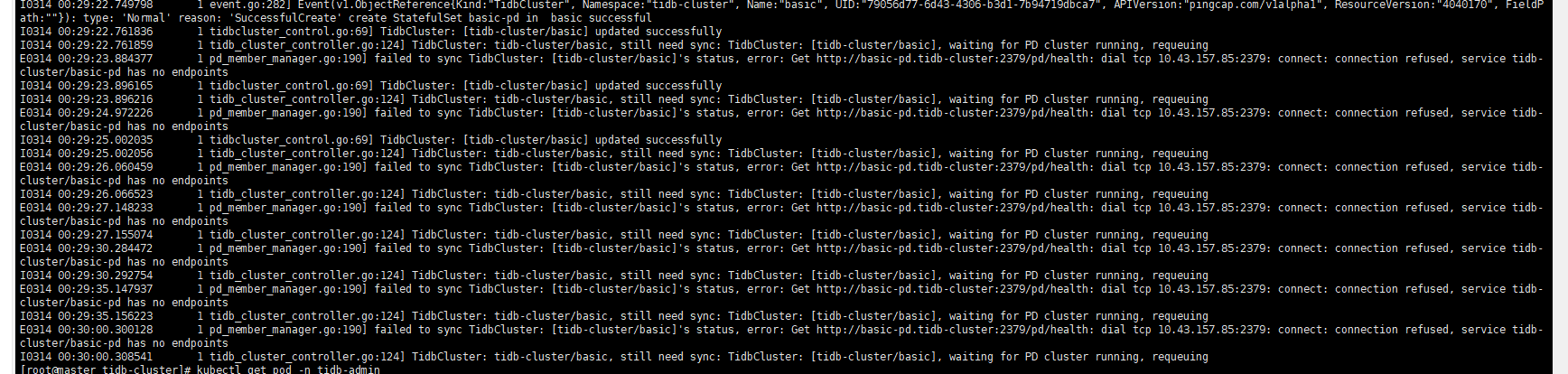
我看安装文档tidb-operator不也是通过helm install tidb-operator 这种方式吗?然后接下来部署tidb-cluster是kubectl apply -f tidb-cluster.yaml,我apply完了只起了一个pod。tidb-operator是1.3.1,tidb-cluster是5.4
tidb-operator1.3安装文档

大佬,你发给我的链接没问题,我们这里用的也是flannel,现在是tidb-operator是可以正常装好的,我再去apply tidb-cluster就只有一个pod出现,剩下的tidb、tikv等都没有起来,目前是碰到这个问题
1,建议检查网络状态。
2,检查pd节点资源使用情况,磁盘,cpu,内存。
是的,现在是在另一个帖子