没这个权利呀
如果 Kubernetes 集群节点个数少于 3 个,将会导致有一个 PD Pod 处于 Pending 状态,而 TiKV 和 TiDB Pod 也都不会被创建。Kubernetes 集群节点个数少于 3 个时,为了使 TiDB 集群能启动起来,可以将默认部署的 PD Pod 个数减小到 1 个。
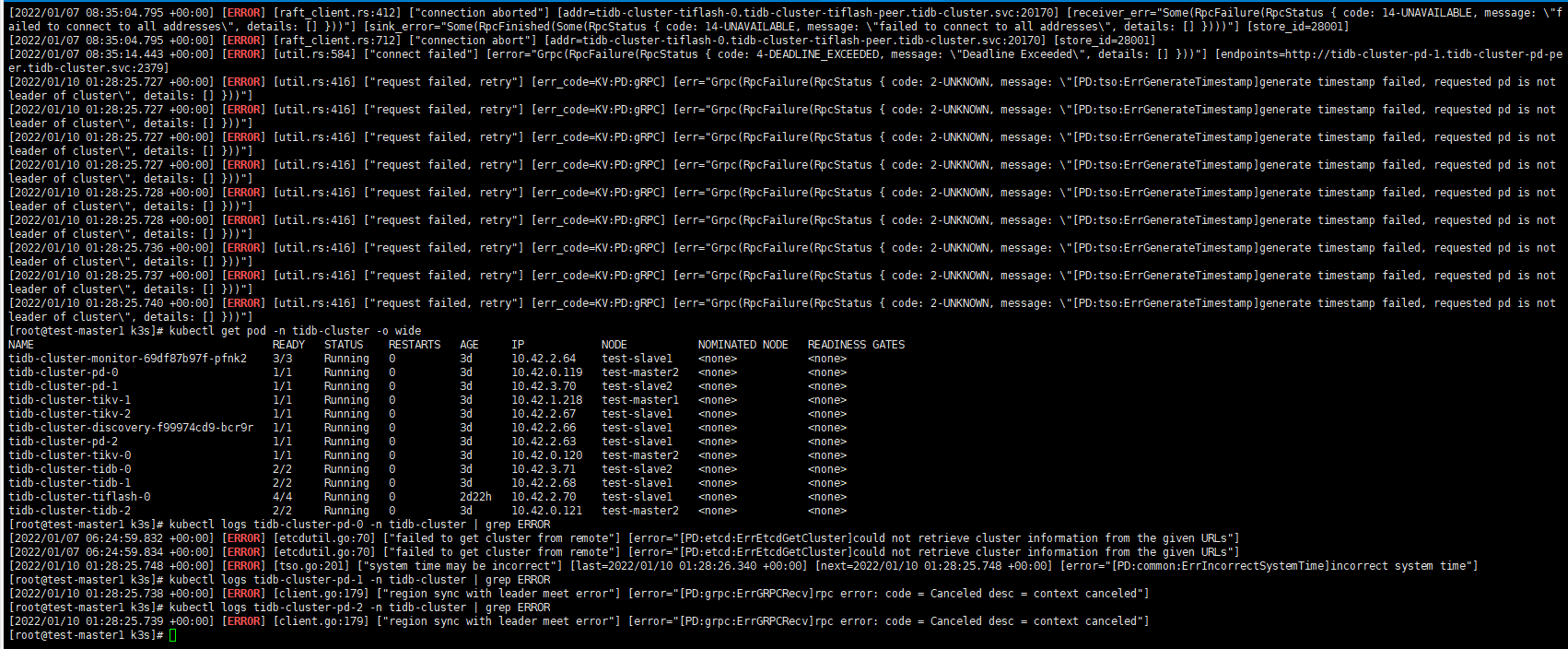
看下你的pd节点上是否有etcd端口?

master节点。不是docker内部
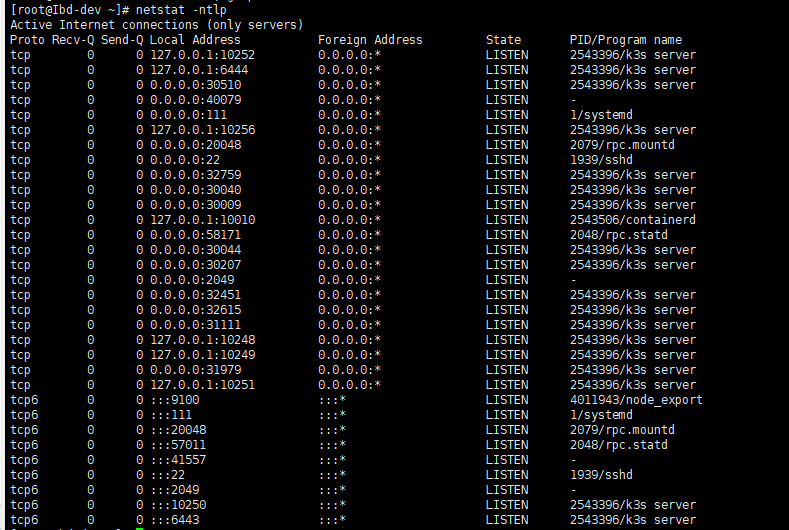
这只能查一下这个k8s集群网络是否有问题,看下日志。
不查啦,不知道啥问题,正常用就好了,感谢


尝试扩容一下pd试试
刚部署的,内存占用不高

网络如果是通畅的,选举就会正常,目前没leader,说明选举就失败了
选举失败,就俩问题:
- 节点数不够,无法满足 Raft 对于选举的要求
- 网络不通
当然,这些是我的判断
基础环境导致的问题很复杂,这个只能靠你自己慢慢排查
如果能帮到你,会继续尝试的
刚刚把pd缩成一个pod后不报leader的错,但是有会报load from etcd meet error,有把数据持久化到etcd的配置关掉吗?官方文档没详细的说明
不能关掉,关掉如果重启,配置就全掉了…


- 集群什么时候开始报错的? 初次安装就报错吗?
- 如果不是初次安装,问题发生时,有做过什么改变? 比如 dns 配置的改变之类的。
1、通过helm包安装的,出现问题的时候是开发人员说在同步一个数据任务卡住了,就开始报错,然后我尝试过重新安装,安装好了还是报一样的错