Artisan
(Artisan)
1
Hello大家好,继上次机器替换出现store leader/region无法均衡的问题后,近日(今天凌晨)又出现了一个集群节点宕机重启后,其上的region无法自动均衡为0的问题,这次现场都还在,我个人也没做太多操作,线索和记忆比较清晰,因此分享出来求助一哈。
【集群版本】: v4.0.13
【问题现象】:
今日凌晨集群有一台节点宕机,涉事集群节点数较多(40多台),因此接到告警后继续睡觉,想着机器重启后服务应该会自动拉起来,就算自动拉不起来等上班手动拉起来即可。
上班之后查看节点状况(依旧是一个节点3tikv实例的部署模式),发现只有1个store实例能使用ps -ef看到,但所有3个实例都在疯狂刷日志,使用systemctl status查看服务都处于activting状态。
观察到集群的leader/region分布处于以下状况:
1、所有leader已正常迁走
2、故障3store的region_count相比故障之前基本没变化
3、故障3store在pdctl中显示为down状态
【个人操作】:
以下为针对此次故障的顺序操作记录:
1、使用tiup stop掉了故障3实例(印象中实际查看节点进程和log应该是没store掉)
2、在pdctl中执行了store delete(故障3store id分别为9,10,11),pdctl显示的store状态和tiup显示的store状态都变为offline
3、经过一段时间后,故障3store上的region_count分别为11、2、5
4、发现剩余的这些region-peer无法再减少,于是手动执行了tiup scale-in(未加force),无报错成功scale-in,store状态全部变为pending offline
5、经过一段时间后,查看故障3store上的region_count依然分别为11、2、5
6、于是决定手动添加remove-peer的operator,得到500的http报错:[500] “failed to add operator, maybe already have one”
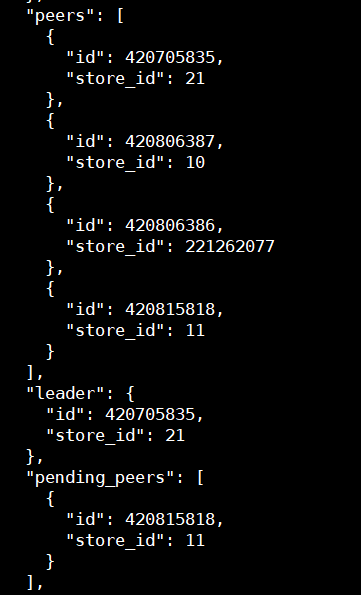
7、operator show region查看region相关的operator:
8、在经过一段时间无操作,查看9-11三个store上的region_count变为了10,2,4
9、查看具体region的peer分布发现基本都是4peer状态,其中2个位于故障store上,如下图所示:
10、目前3store实例的状态都已经变为inactive,3store的region_count依然有微小变动,再次截图为:
11、再次到故障节点systemctl start 3个tikv service,居然毫秒级别的起来了,估计是因为store是没多少数据的offline状态。再次观察各个store的region_count发现在缓慢减少,经过一段时间后(比较长,目测减少的速度为1min1-2个peer),故障3store上的region终于全部变为0了。
12、查看tiup的实例状态变为tombstone,可以prune了。
【总结】
原为求助帖:dizzy_face:,因为要写的操作太多所以中途做了一些操作(如上所示的11-12步),现在节点已经正常下掉了。
还是希望官方技术支持关注下,因为宕机后有可能实例再也起不来(或者人工force scale-in了),此类情况下就无法做第11步的操作,那么这些pending的peer就会永远无法自动or手动删除。
2 个赞
Artisan
(Artisan)
2
补充一个现象,在第11步把故障实例起来后,operator show region结果显示的remove pending相关的operator迅速消失了,应该是实例启动后operator不再卡顿了。
能总结到的一点就是:节点宕机或者做迁移时,原机器需要尽可能保持现状,如果正常scale-in不生效/失败,只能使用pdctl操作尝试delete store,等待region消失,如果region正常减少至0那就好,如果不行只能等region减少后尝试启动旧实例(之前启动会hang住),如果region都不减少,那就只能考虑整集群迁移了。
2 个赞
能够提供一下 TiDB 集群拓扑 ?让我再理解一下 ?从线上上看是 1 TiKV node 故障,希望快速将这个 Node 下面的 3 个 TiKV 实例数据快速再其他节点恢复 ? 那一共是多少个 TiKV node ?理论上 >=3 的 TiKV node,如果 1 个 TiKV node 并不会影响到读写,因为 raft 算法的多数派可用的设计。所以可以直接停掉故障节点,只要 Leader transfer 成功(这个很快,秒级别完成),就不会影响到正常业务使用,然后快速 scale in 新的 TiKV node,来保证 3 副本可用状态就好。
2 个赞
Artisan
(Artisan)
4
42台机器构成的集群,每台固定3个tikv实例,其中15台会额外部署tidb实例,3台会额外部署pd实例。
所以是15tidb,3pd,126tikv的结构。
1个节点宕机不会影响可用性,节点故障时Leader transfer确实很快,但由于故障机器所有tikv实例长时间hang住无法启动(保持down状态至少8小时以上),导致region raft副本的正常均衡遇到的的本文中描述的问题,故障实例上的所有region副本未发生迁移。
tiup stop掉故障实例并在pdctl中执行store delete后,故障机器上的region peer极大减少,但仍有少数几个一直无法清零,如上述个人操作1-10所描述的。scale-in也不会报错显示正常缩容,此时再次把故障机器上的实例拉起来后剩余的几个region peer缓慢清理,如上述11-12步所描述。
Artisan
(Artisan)
5
换句话说,就是机器故障之后我们的第一反应肯定是先把机器起来然后等实例起来后副本自动均衡和恢复,如果起不来就缩容or强制缩容掉故障机器以期待raft group可以自动探知实例不可用补全副本。
但最近半年已有3个集群遇到了类似的问题,集群扩容后新节点数据未按预期均衡、或者机器宕机重启后由于实例状态异常导致缩容后实例状态一直无法变为tombstone进行prune,强制缩容又会导致一些region状态不是正常的3副本。
感觉随着集群数的增长和单个集群数据量的增长,此类问题会慢慢浮现。
托马斯滑板鞋
(托马斯滑板鞋)
8
一台主机3tikv,那你可能需要5副本来避免单节点故障了(单主机故障);或者给tikv打label
Artisan
(Artisan)
9
这是什么原理,host label设置之后,单台机器上的tikv实例一般不会有2个region peer存在,本例中异常状态下倒是可能导致这种异常场景,起来的那个tikv实例上会多一些pending的peer。
但我想这里的主要问题是region peer无法正常保持3副本,多数副本可用性一直是可以保证的,多一些副本数应该没什么效果吧。
我们添加实例时会自动打上下滑线连接的ip作host label.
system
(system)
关闭
11
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。