【概述】
集群扩缩容做机器替换后,leader、region分布不均
【现象】
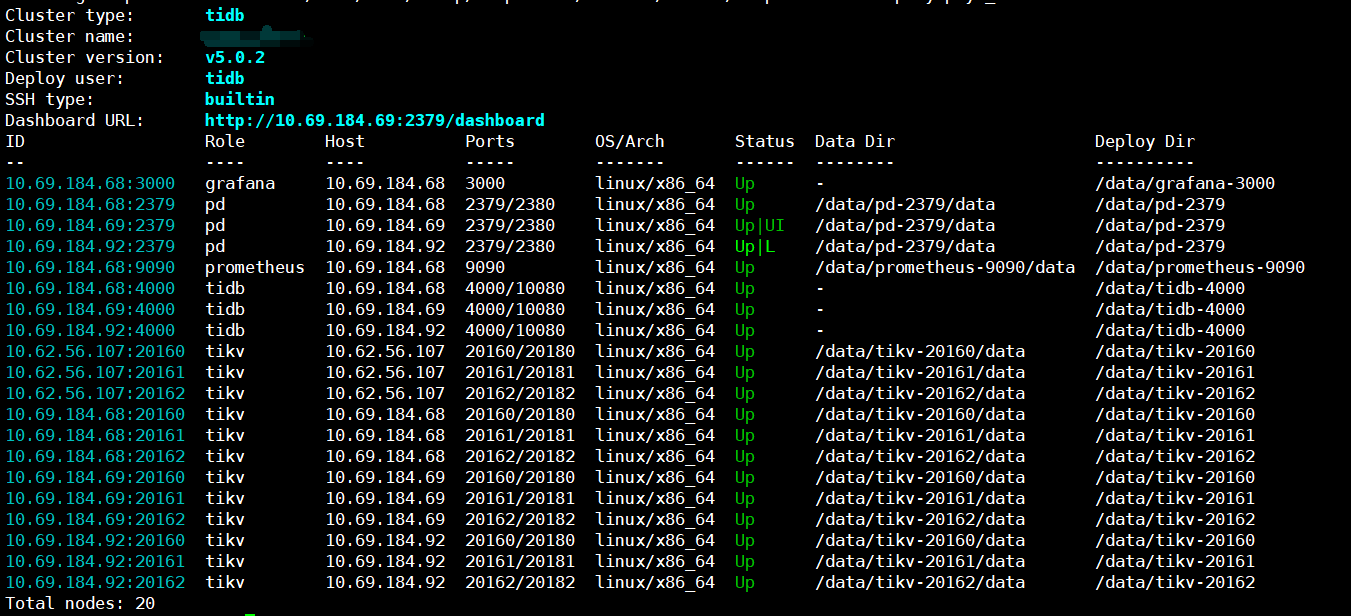
对一4节点12store实例的集群(每台机器3tikv实例)做扩缩容机器替换后(10.16.129.81替换为10.69.184.92),旧机器长时间处于pending offline状态,关停旧机器后leader迁走,但region个数依然无变动,强制缩容后store状态依然为offline。
【业务影响】无
【TiDB 版本】5.0.2
【概述】
集群扩缩容做机器替换后,leader、region分布不均
【现象】
对一4节点12store实例的集群(每台机器3tikv实例)做扩缩容机器替换后(10.16.129.81替换为10.69.184.92),旧机器长时间处于pending offline状态,关停旧机器后leader迁走,但region个数依然无变动,强制缩容后store状态依然为offline。
【业务影响】无
【TiDB 版本】5.0.2
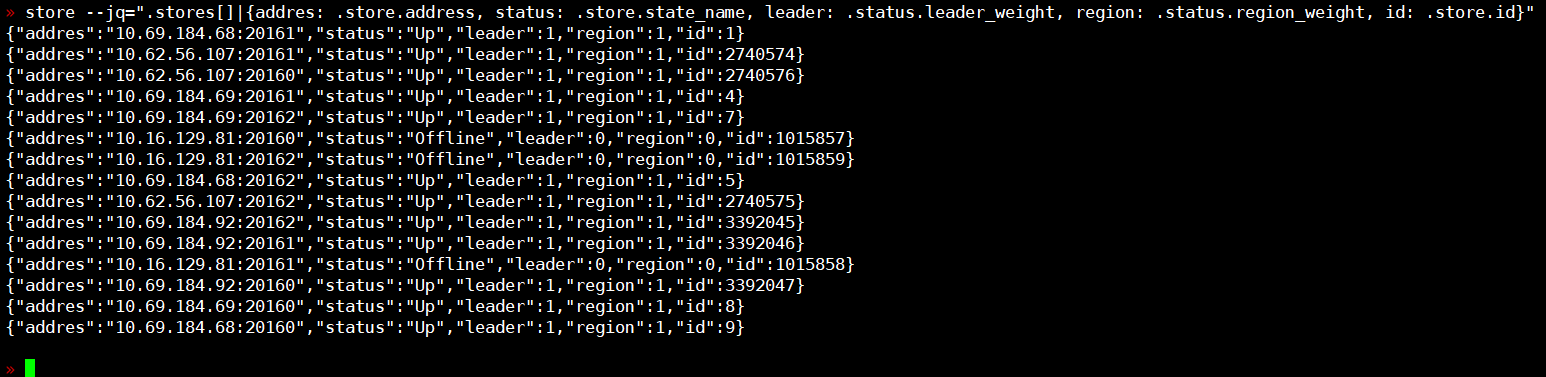
机器替换时间已经是1周之前了,期间由于只是数据不均衡随意没怎么操作,现在有时间了决定处理一下,试了好多办法,包括修改leader/region weight,store delete,重启pd+重启tikv。最后还是不均衡的状态~~
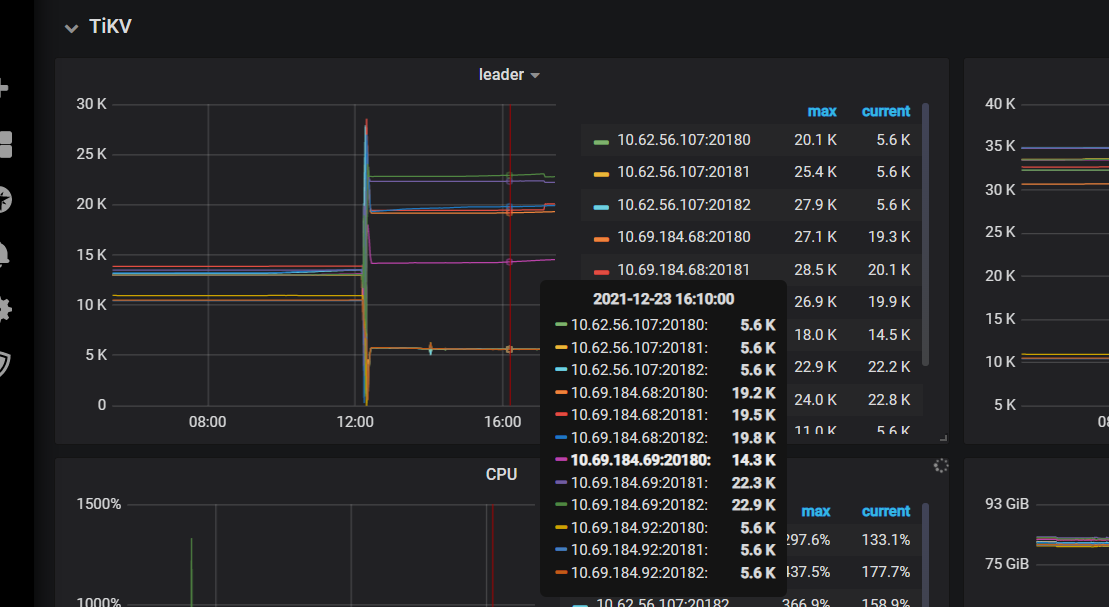
下图为最近24h监控截图,突刺为重启restart tikv引发。
tikv 为 offline 状态的节点,还有哪些 region 没有迁移完成?一共还有多大的数据需要待迁移的?
参考这个来查询一下
https://docs.pingcap.com/zh/tidb/v5.0/pd-control#region-store-store_id
https://docs.pingcap.com/zh/tidb/v5.0/tikv-control#查看-region-的大小
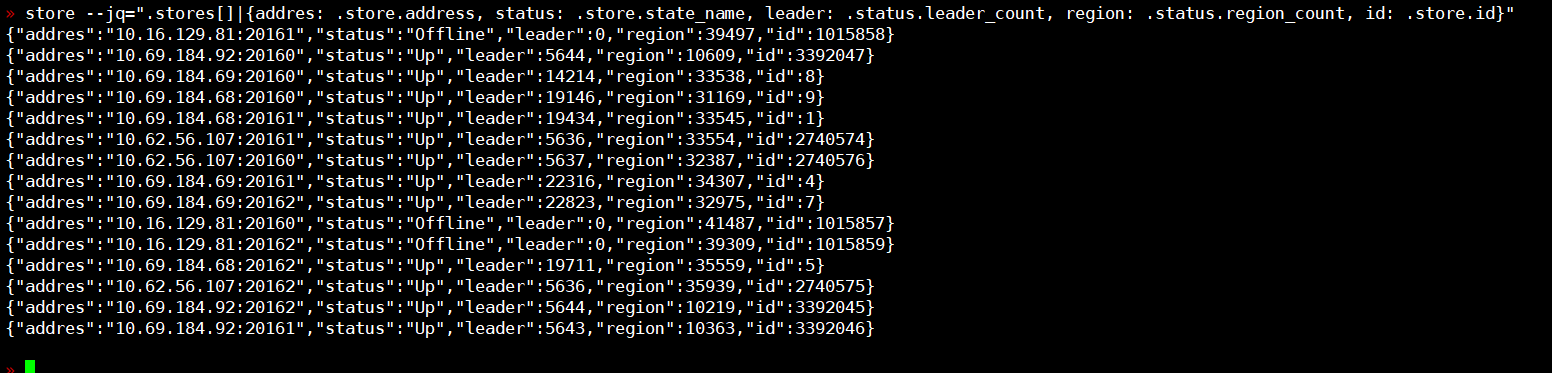
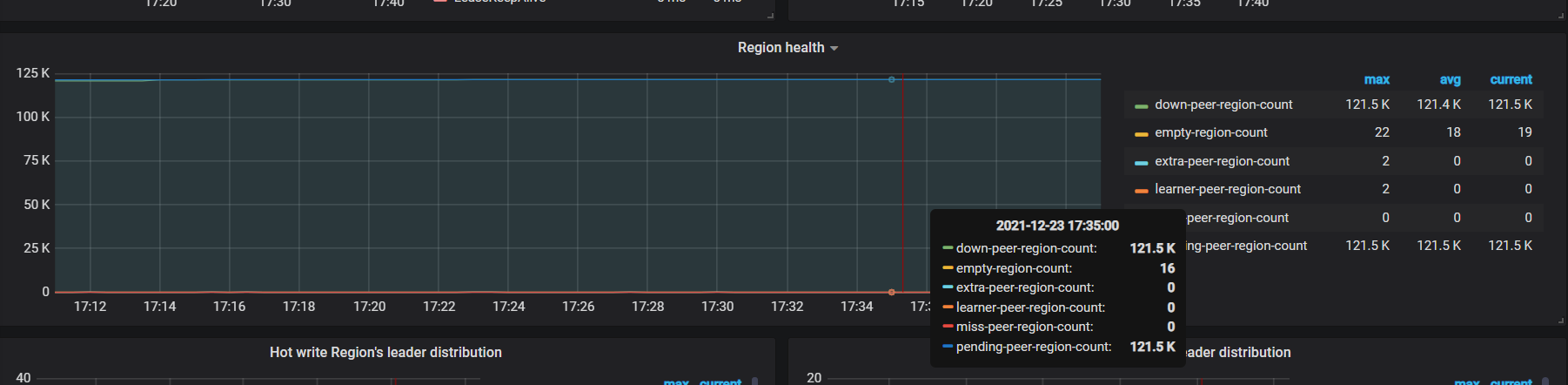
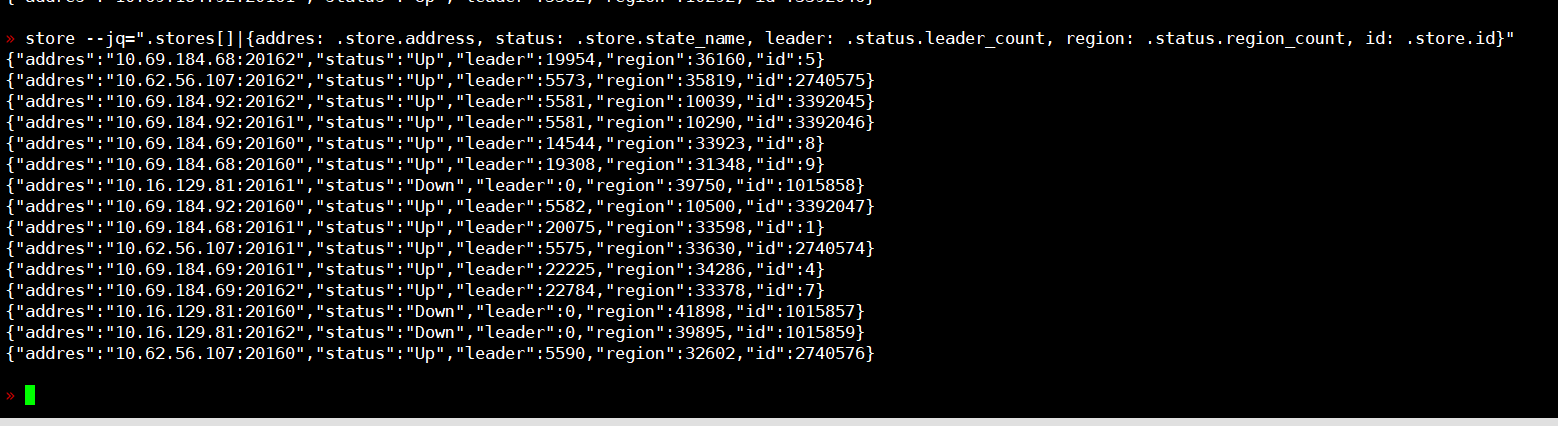
未迁移的region数目和上述第2副图里的region_count一样,迁移前后数据没有大的变化甚至还多了2k左右。
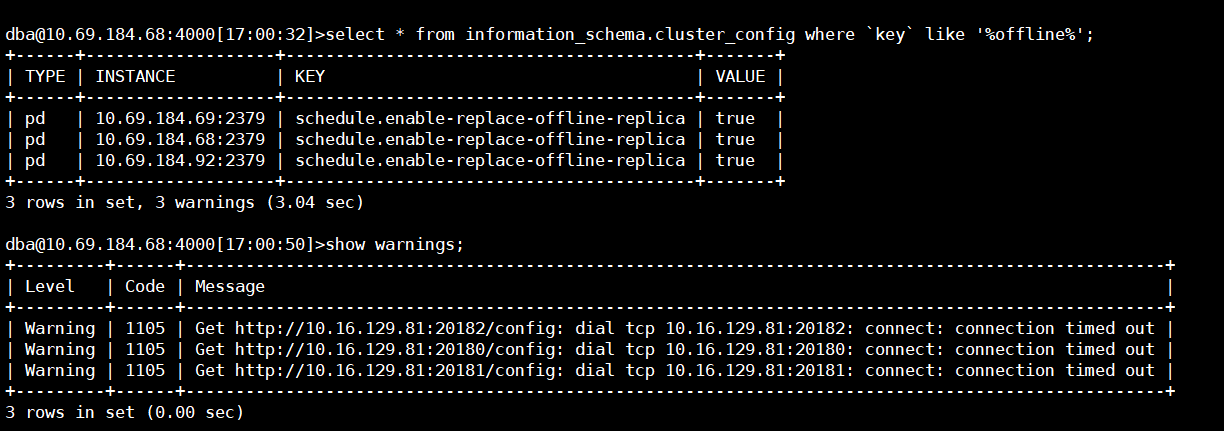
region 的迁移 scheduler 是不是被关闭了?
查下这个参数
disable-replace-offline-replica
然后如果是开启的,那么可以调大 replica-schedule-limit (默认 64), 在观察下
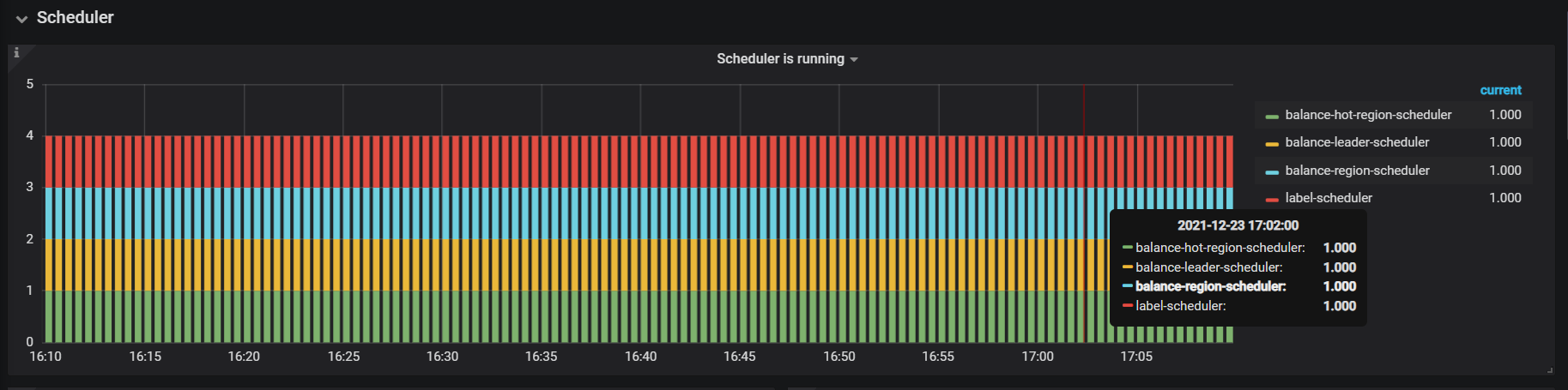
通过 grafana 去查看 schedule 的操作信息
PD 面板 -> Operator -> Schedule operator
https://docs.pingcap.com/zh/tidb/stable/grafana-pd-dashboard/#scheduler
这里可以看到每个 scheduler 操作的状态和耗时
https://docs.pingcap.com/zh/tidb/stable/grafana-pd-dashboard/#operator
有没有做 label 的设定? 这个会影响到 region 的调度
旧机器长时间处于pending offline状态,关停旧机器后leader迁走
这部分的操作是怎么处理的?能描述下过程么?
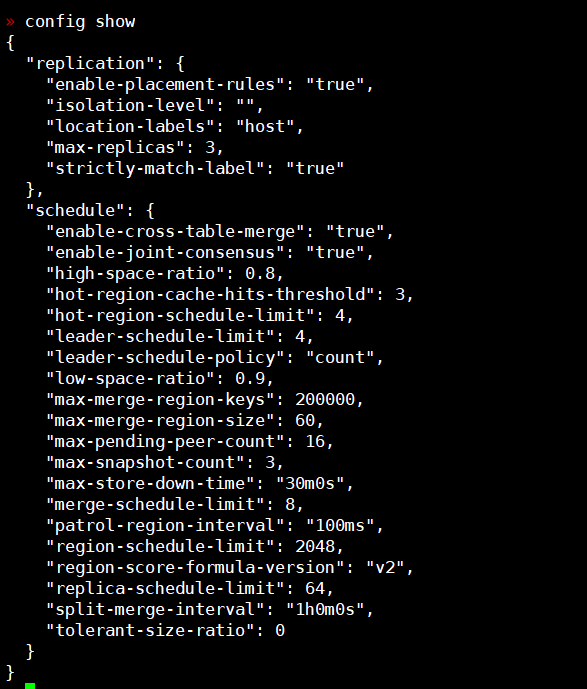
目前所有机器都有host label,取值格式统一为host_10_69_184_68这种,zone label有的设置了有的未设置,label策略如之前的图所示是这样的:
“replication”: {
“enable-placement-rules”: “true”,
“isolation-level”: “”,
“location-labels”: “host”,
“max-replicas”: 3,
“strictly-match-label”: “true”
},
最初location-labels为”zone,host”,后来升级版本时修改为host,当时没注意数据分布的问题。
因为集群有4台机器常驻,正常scale-in后一直处于pending-offline,新机器leader只是从其他节点分了一些,旧机器的leader个数依然保持和其他所有节点一样都是10-13k左右(新机器9k左右),新机器分到的region和leader个数一模一样。
这样僵持了几天后,我先把旧机器上的实例直接stop,这样机器上leader就全转走了,但是region个数等了1天发现还是没转,于是我尝试了重启pd节点和transfer pd leader无效,最后今天早上我直接强制scale-in了旧机器的实例并shutdown了旧机器。在pdctl里看状态依然一直是offline,pd的日志没看到大规模region peer转移的现象
有几个问题:
1 .旧机器节点上有几个实例? 如果是 3个 实例,stop 以后就没办法迁移了(如果你是 3副本,如果刚好3副本都落在哪个旧机器的节点上)
2. 缩容以后需要等待节点迁移 region,shutdown 以后 肯定是 offline了,也没办法完全迁移
3. 重启 PD 节点和 转移 PD leader 是个什么操作? ![]()
操作建议:
启动旧的实例,等待迁移的调度,查阅相关的Region 是否有迁移的行为
目前旧的实例被强制scale-in,目录清掉了… 或许可以扩容试试,但肯定会出现store address的冲突
或许重建pd会有用,但是集群比较重要还不能这么做![]() 我尝试下扩容一台机器试试。目前这状态也不敢升级什么的。
我尝试下扩容一台机器试试。目前这状态也不敢升级什么的。
如果你判断对业务没影响的话,我理解从 pd 中把这些 offline节点信息给清理掉就可以了
pd-ctl store delete xx
参考:
https://docs.pingcap.com/zh/tidb/stable/pd-control/#store-delete--label--weight--remove-tombstone--limit--store_id---jqquery-string
![]() 这个我前几天试过,store delete显示success,但是删完还是offline。
这个我前几天试过,store delete显示success,但是删完还是offline。
我刚才尝试把下掉机器上的store的状态改为Up(之前发现这个版本的pd api已经不支持修改tombstone了,只能修改为up和offline),发现store state有些异动变为了Down,有进展我再来回复。
看起来这种地摊儿操作无效,执行store delete状态继续变回offline,期间leader和region也没发生什么迁移。