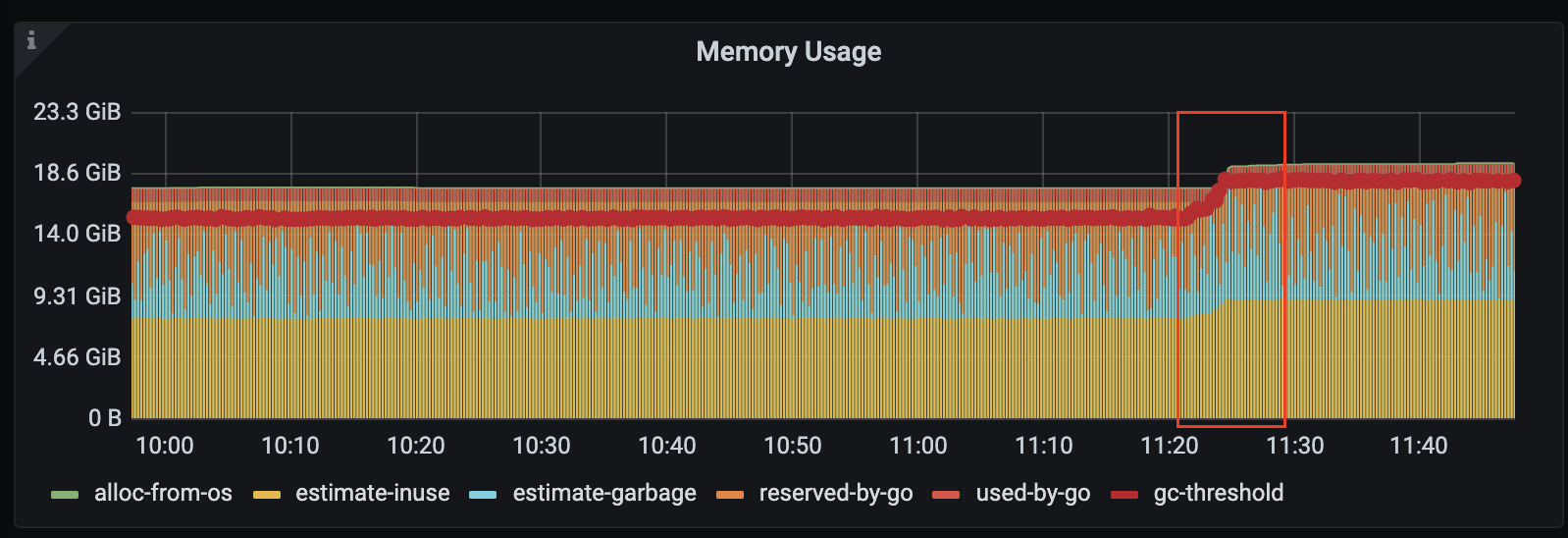
想请问tidb-runtime 里面的Memory Usage 跟Estimated live Objects 两张图表的关系
如下图所见在正常情况运作下两张图表以正相关慢慢的增加都没有减少,这样下去感觉会oom
想请问各位大神要从什么方线进行排查
版本是最新的V5.3.0版
想请问tidb-runtime 里面的Memory Usage 跟Estimated live Objects 两张图表的关系
如下图所见在正常情况运作下两张图表以正相关慢慢的增加都没有减少,这样下去感觉会oom
想请问各位大神要从什么方线进行排查
版本是最新的V5.3.0版
這邊附上監控
tidb-test-Overview_2021-12-21T06_02_10.966Z.json (6.1 MB
) tidb-test-TiDB-Runtime_2021-12-21T05_57_47.141Z.json (2.4 MB)
tidb-test-TiDB-Summary_2021-12-21T05_56_24.484Z.json (892.2 KB)
当时升版从5.2.2升级到5.3.0 有重起服务
Hi ,麻烦提供一下相同时间短的 TiKV-details 监控哈
这边输出一下 档案感觉会很大
目的还是想看一下 TiKV 侧的 Cop 计算请求是不是增加的,然后判断是不是随着 region 数据增加,导致 cop 请求 scan key 量越来越多,导致在 tibd server 缓存数据增加,导致内存使用逐步增加。
tidb-test-TiKV-Details_2021-12-23T08_33_38.886Z.json.zip (3.6 MB)
档案太大 我压缩下
region 这边有尽量控制在差不多的数量,有怀疑是不是有使用较多内存的select语法造成的,前端有些语法一句会使用到6.7百M 内存
看 TiKV 监控应该没有增长,可以先按照你怀疑的部分排查一下,我们可以再看看。
https://github.com/pingcap/tidb/blob/master/metrics/grafana/tidb_runtime.json#L145-L150
可以看一下这个,从 metric 的语法介绍看,应该是待 gc 过去的缓存太多了。你们的业务逻辑是缓存有大量的聚合计算么 ?
我们绝大部分语法都有聚合,因为analyze的关系有将tidb_gc_life_time由10m改成2hour
因为我们也遇到[“analyze failed”] [error="[tikv:9006]GC life time is shorter
这个问题 所以有把GC时间拉长
如果是这个,建议把看一下 SQL,能不能通过调整执行并发,加快处理速度。
@eddiechiang 刚才确认了一下,这个情况是预期的,但是不会影响到正常使用。go gc 的内存是会定期被清理的,如果有聚合计算的请求会将这部分内存直接用上,不需要再系统申请新的。oom 场景下是因为 gc 内存被消耗净,然后系统申请不到足够的内存导致 oom,这种情况如果发生就需要优化 SQL 或者扩展一下内存,保证计算资源可用。
查看log跟这篇有点相似
请问这个参数开启了吗。?enable-streaming = true
mysql> select @@tidb_enable_streaming;
±------------------------+
| @@tidb_enable_streaming |
±------------------------+
| 0 |
±------------------------+
1 row in set (0.00 sec)
查看是关闭的
5.3版已经废弃了