【TiDB 版本】 4.0.13
目前我们的TiDB 使用 TiDB Operator 部署在阿里云 k8s 集群,TiKV 4节点部署在4台本地SSD服务器,TiDB 4节点部署在两台普通云服务器,每台服务器运行两个TiDB实例,单实例限制内存6.5G。
使用过程中发现 TiDB 内存占用随时间持续增长,直到突破 6.5G 被docker自动杀死重启,若不限制内存则会造成系统内存耗尽假死。
我们有尝试分析heap,发现内存占用最大的是 http2Client 调用的 bytes.makeSlice,因我们团队不熟悉go语言,找了些资料暂时还不理解。
附件为完整的 profile,若需其他信息补充请随时告知, 多谢
【附件】
profile.zip (3.1 MB)
2 个赞
请查看业务代码是否TiDB的客户端连接是否及时释放。
1 个赞
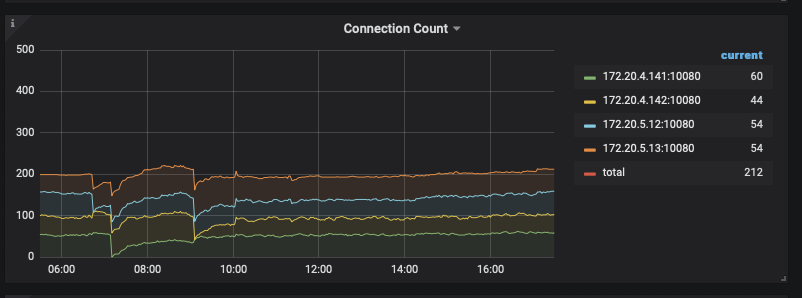
我们也怀疑过这个问题,这个但从监控来看, 连接数并没有明显的波动
图中几个明显的锯齿是由 TiDB 重启导致的。
连接的服务全部使用 java, 连接池以 Ali Druid 为主, 其他不同连接池也有,但涉及服务较多,尚未一一统计
1 个赞
抱歉, 昨天写了一半被拉去开会搞到半夜。
当时指的是重启时吗? 一方面我们的日志收集有点儿问题,只收集了 slowlog,所以 tidb 日志重启后就没有了。
二一个这是内存持续增长直到最后超出限制,所以压倒骆驼的最后一根稻草可能不是真正的原因。
本来我想把完整日志传上来, 但后来看里面还是有不少敏感信息,发公开场合不太好,我尝试贴部分怀疑的日志,如需完整日志不知是否有不公开方式来进行?
[2021/08/11 16:09:08.190 +08:00] [WARN] [client_batch.go:638] ["wait response is cancelled"] [to=diiing-tikv-0.diiing-tikv-peer.tidb.svc:20160] [cause="context canceled"]
[2021/08/11 16:09:08.190 +08:00] [WARN] [client_batch.go:638] ["wait response is cancelled"] [to=diiing-tikv-3.diiing-tikv-peer.tidb.svc:20160] [cause="context canceled"]
[2021/08/11 16:09:13.487 +08:00] [INFO] [coprocessor.go:1034] ["[TIME_COP_WAIT] resp_time:307.495003ms txnStartTS:426945898889084938 region_id:1645916 store_addr:diiing-tikv-2.diiing-tikv-peer.tidb.svc:20160 kv_wait_ms:289"] [conn=52853]
[2021/08/11 16:09:13.514 +08:00] [INFO] [coprocessor.go:1034] ["[TIME_COP_WAIT] resp_time:325.388035ms txnStartTS:426945898889084938 region_id:1649540 store_addr:diiing-tikv-2.diiing-tikv-peer.tidb.svc:20160 kv_wait_ms:308"] [conn=52853]
这几个看起来是因超时而取消了请求。
回一下 @xfworld, 慢查询是我们尝试的首要目标, 但目前接入这个TiDB 的服务较多, 业务较杂, 难以完全解决, 我们目前每天超过1秒的慢查询有约2000条, 超过5秒的有约50条, 同时为了避免异常SQL导致问题我们设置了 MAX_EXECUTION_TIME 为15秒, 但这个内存问题依旧没有改善
1 个赞
看这个时间点 你们是否有备份 我所知的4.0.13的dumpling是有bug的。会导致这种现象
1 个赞
目前我们没有使用 dumpling 进行备份, 另外发生时间点是随机的,内存满了就会重启。
内存突增大部分发生在7-9点, 这倒也是我们业务高峰, 但我们分析了很久也没发现异常SQL。其他时间也在缓慢逐渐上升。
1 个赞
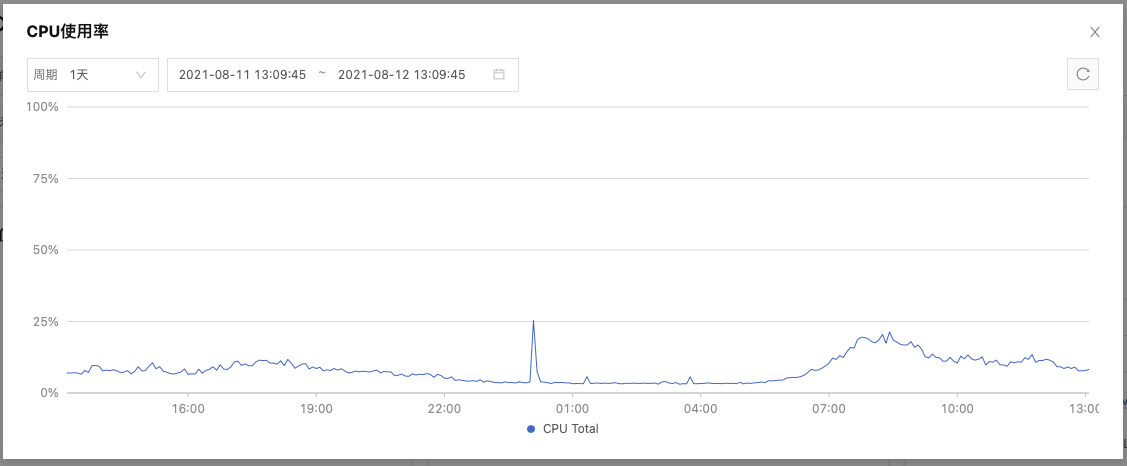
非常感谢您对此问题的持续关注, 服务器层面CPU起来是正常的波动,这是tidb节点CPU监控图:
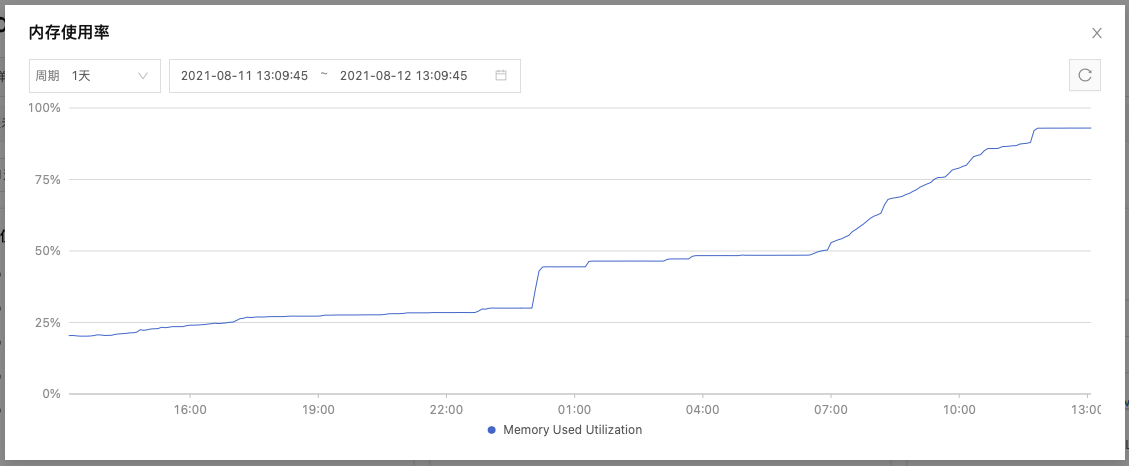
其他节点波动类似, 但内存监控图是这样的:
这个问题应该是从我们切换到 tidb 就一直存在, 最开始的版本是4.0.4,到现在差不多一年了。
在此期间我们尝试了很多办法,内存限制也从一开始的2G到4G再到现在专用节点,重启频率低了,但问题一直存在,很是难受…
1 个赞
一开始使用的是默认值未做变更, 后来有尝试变更, 现在
| # VARIABLE_NAME |
VARIABLE_VALUE |
| tikv_gc_leader_uuid |
5eccaf919100004 |
| tikv_gc_leader_desc |
host:diiing-tidb-2, pid:1, start at 2021-08-11 09:05:35.814607793 +0800 CST m=+0.138338731 |
| tikv_gc_leader_lease |
20210812-13:51:35 +0800 |
| tikv_gc_enable |
true |
| tikv_gc_run_interval |
15m |
| tikv_gc_life_time |
1h |
| tikv_gc_last_run_time |
20210812-13:48:35 +0800 |
| tikv_gc_safe_point |
20210812-12:48:35 +0800 |
| tikv_gc_auto_concurrency |
true |
| tikv_gc_mode |
distributed |
2 个赞
看profile的分析 我这边还是倾向你们的http请求有未主动释放。我这边建议你调大内存试一下
1 个赞
Kongdom
(Kongdom)
15
有查看系统进程么?未终止的进程应该进入不到慢语句中……
show full processlist 或者查询INFORMATION_SCHEMA.CLUSTER_PROCESSLIST
1 个赞
qizheng
(qizheng)
16
上面 profile 抓取的时间看起来是日常的,有没有抓取上涨期间的进行对比。
每天慢查询数量还是比较多,可以查一下 statements_summary 表,根据 SQL DIGEST 统计,看哪类 SQL 的 MAX_MEM、AVG_MEM 占用比较高。
如果有发现内存占用较大的 SQL,可以看看执行计划,哪些算子消耗内存,尝试调小 memory quota 设置,让超出的内存交换到 tmp-storage-path 路径下(需要预留足够的空间),另外建议升级到 v4.0.14 版本。
1 个赞
我现在也怀疑是不是 http 连接有泄漏的情况, 可关键是这 http2client 是哪里的我们搞不太清楚。
访问 tidb 方面我们应用只连接 4000 端口, k8s 健康检测也是 tcpSocket 4000, 只有 prometheus 会连接 10080 获取监控数据
1 个赞
可能是由于并发多时导致的内存不能及时回收,并且内存比较小,造成了内存到达100% 这边都是16G到32GTIDB节点,你可以尝试调大试一下
1 个赞
我们目前配置的内存限制为 256M
mem-quota-query = 268435456
oom-action = "cancel"
我再提供一个刚重启一小时左右的 profile, 目前内存占用约300M
profile2.zip (588.0 KB)
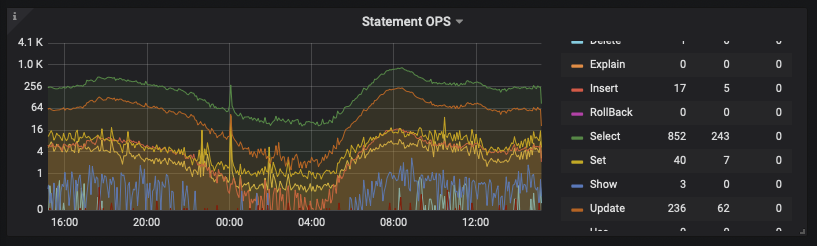
慢查询我们一直在优化, 现在的比半年前已经减少了超过一半, 但 tidb 这个内存问题没有明显缓解,目前我们系统select峰值 ops 800 多, 日常200-400, 慢查询占总量应该还是比较低的
关于 SQL DIGEST 我再研究下。
@Kongdom 我有多次尝试分别连各节点show full processlist 没发现异常,不过您提供这个CLUSTER_PROCESSLIST 是个好东西, 我再观察下
1 个赞
Polar
(Hacker T Pc Mw G Jh)
20
前段时间也遇到这个问题。tidb节点内存持续升高,直到卡死。
上次和tidb人员一起分析下来应该是sql的问题,因为在v4.0.*版本中,order by、group by、limit等操作,全部是在tidb节点完成的,如果出现数据量大的表并且比较复杂的语句,tidb节点内存会暴增。
tidb社区人员推荐升级到v5.0.*版本,使用mmp引擎让部分计算下推到tiflash,从而降低tidb节点内存的占用。但是实测下来效果并不明显,还是有些问题。比如 加limit后,不走tiflash,查询效率降低很多
1 个赞