h5n1
(H5n1)
1
【版本】 tidb v5.2.3 ,DM v2.0.6
【部署】5台主机,5tikv+3pd+4tidb混合部署 sas磁盘,前端使用harpxoy
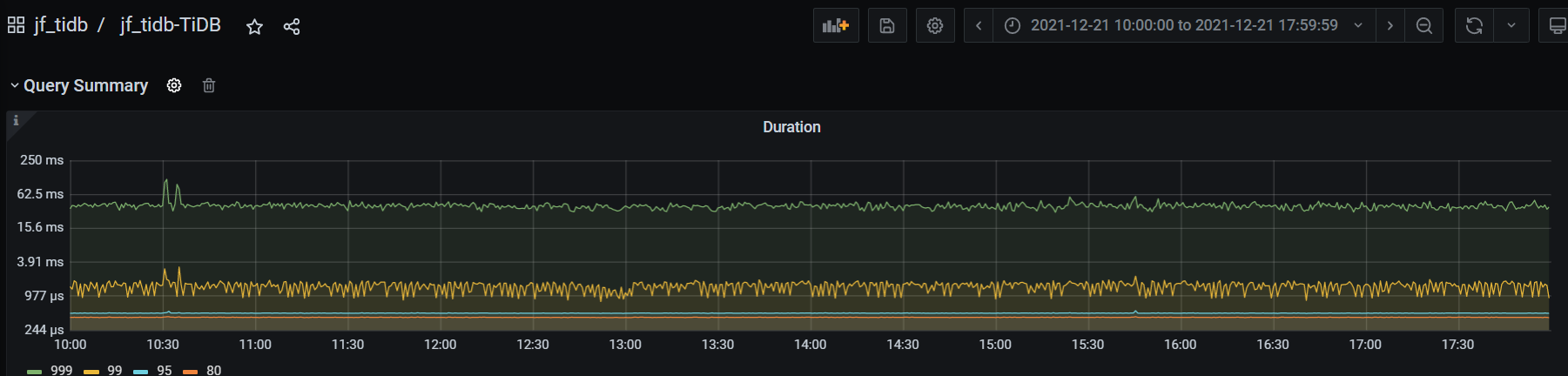
【问题】 该集群使用DM同步上游2个MySQL数据,目标库指定为为187:4000,仅有insert操作,查询很少。14:30-14:45 出现P80/P95/P99 duration增高情况,检查发现187:4000出现duration增高
期间几乎没有慢SQL,tidb kv request有增高,但不是持续性的,中间有5分钟左右正常。
tikv 侧CPU、 IO 、 各种duration、 message数量、 rocksdb-kv的写入、网络 等 都是降低的 ,raftdb的total kyes有持续性的增高
也看所有主机的ping延迟监控没有出现增高的情况
监控附件如下:
jf_tidb-Overview_2021-12-19T08_18_16.388Z.json (1.5 MB)
jf_tidb-TiDB_2021-12-19T08_04_38.561Z.json (3.3 MB)
jf_tidb-TiKV-Details_2021-12-19T08_01_38.759Z.json (10.3 MB)
tydm-DM-task_2021-12-19T08_06_39.631Z.json (306.9 KB)
Tidb-Cluster-Node_exporter_2021-12-19T08_36_01.938Z.json (138.3 KB)
tikv-187.log (2.9 MB) tidb_187-4000.log (392.8 KB)
2 个赞
h5n1
(H5n1)
3
不像是写入性能的问题,按照文档排查结果
1、 wal无写入增高和timeout,反而是下降趋势
2. WAL write duration下降
3.WAL sync 无增高,raftdb的有降低
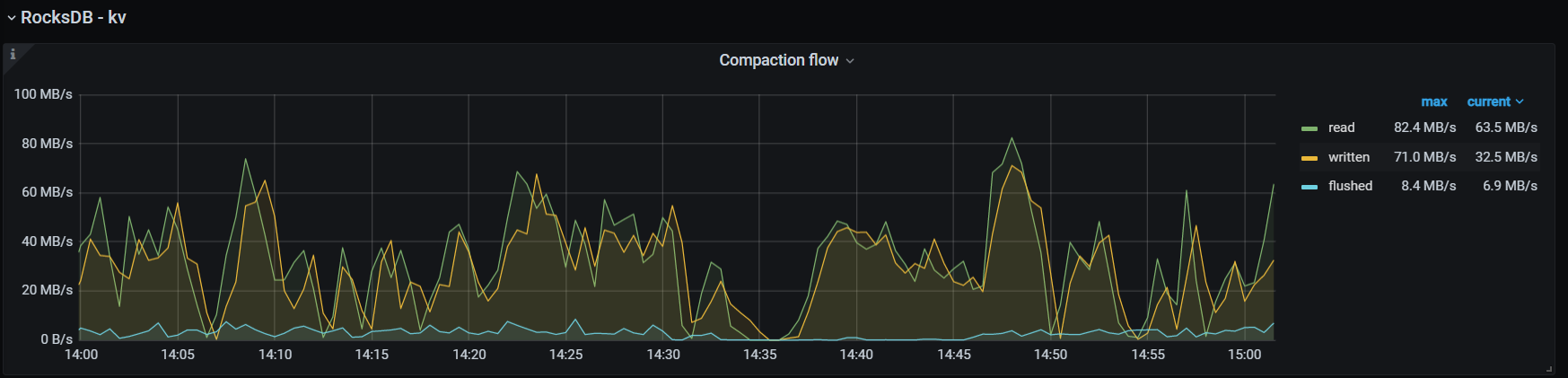
- write duration降低,见第2段截图
- 无write stall
- rocksdb-kv compaction无明显增高,raftdb的compaction将为0无任何compaction
7.仅raftdb的 Total keys指标在问题期间可以看到明显的升高,不知道什么操作能再写入量降低的情况下,而keys数量直线上升
1 个赞
sultan8252
(Sultan.Su@PingCAP)
6
你这个 集群磁盘是 Sas 的 但凡有 analyze table 、ADD Index 、LSMTREE compaction 都会有这样的现象。。
你要看可以看 是不是 上游有 DDL 操作 ,或者看 analyze 的历史 是否在时间段
本质上这类问题都需要你的 tikv 的 磁盘带宽来支撑。根治办法还是更换符合生产环境要求的磁盘设备
h5n1
(H5n1)
7
上游是周期性的监控数据,数量比较平稳,也没有DDL。从上午9点到下午17点间持续有analyze ,但延迟增高仅在14:30-14:45,且在此期间raftdb的total kyes从100K增长到500K左右,然后恢复正常。就算是磁盘性能差(12块raid10+2G raid缓存)那延迟应该是很长时间的持续性,而且不会导致raftdb keys的突增突降吧
另外看了20号的,同样有持续性的analyze,但没有出现tidb duration增高的情况
21号的
h5n1
(H5n1)
9
感谢!
1-2:这时间段的慢SQL已经在发帖时贴上了,业务没什么影响,都是监控数据库没有什么查询。
3:999duration虽然快了但其他的都增长了有3倍以上 ,且仅问题时间段有增长,999降低我感觉是因为qps降低后量少导致的并不能说明其本身变快了。DM监控快照在发帖时已导出,14:00-15:00期间DM的量还是比较平稳的。
我始终比较疑惑的是为什么问题时间段内raftdb的total keys增长了5倍,而后又突然下降,在这期间rocksdb、raftdb写入量都是下降的,total keys正常后duration也恢复正常了
1 个赞
h5n1
(H5n1)
关闭
10
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。