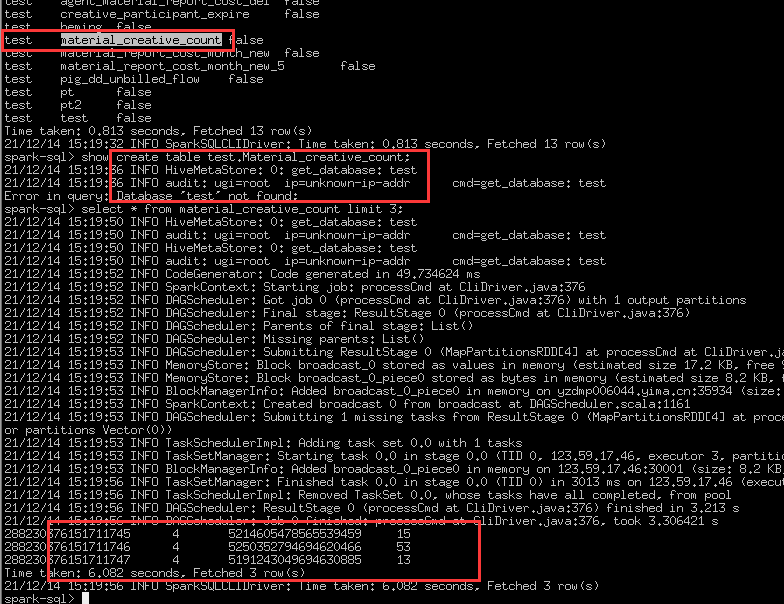
spark-sql> show tables;
21/12/14 15:25:52 INFO HiveMetaStore: 0: get_database: yixintui_operate
21/12/14 15:25:52 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: yixintui_operate
21/12/14 15:25:52 INFO HiveMetaStore: 0: get_database: default
21/12/14 15:25:52 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default
21/12/14 15:25:52 INFO HiveMetaStore: 0: get_database: default
21/12/14 15:25:52 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_database: default
21/12/14 15:25:52 INFO HiveMetaStore: 0: get_tables: db=default pat=*
21/12/14 15:25:52 INFO audit: ugi=root ip=unknown-ip-addr cmd=get_tables: db=default pat=*
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 1
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 18
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 3
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 4
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 16
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 26
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 14
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 17
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 22
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 15
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 27
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 25
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 5
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 6
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 12
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 8
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 30
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 2
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 24
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 9
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 19
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 21
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 29
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 13
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 28
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 10
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 20
21/12/14 15:25:53 INFO ContextCleaner: Cleaned accumulator 31
21/12/14 15:25:54 INFO BlockManagerInfo: Removed broadcast_0_piece0 on yzdmp006044.yima.cn:35934 in memory (size: 8.2 KB, free: 997.8 MB)
21/12/14 15:25:54 INFO BlockManagerInfo: Removed broadcast_0_piece0 on 123.59.17.46:30001 in memory (size: 8.2 KB, free: 5.2 GB)
21/12/14 15:25:54 INFO ContextCleaner: Cleaned accumulator 7
21/12/14 15:25:54 INFO ContextCleaner: Cleaned accumulator 11
21/12/14 15:25:54 INFO ContextCleaner: Cleaned accumulator 23
21/12/14 15:25:55 ERROR SparkSQLDriver: Failed in [show tables]
java.lang.IllegalArgumentException: Multiple entries with same key: material_creative_count=table_id: 29944
columns {
column_id: 1
tp: 8
collation: 63
columnLen: 20
decimal: 0
flag: 4099
default_val: “\000”
pk_handle: true
}
columns {
column_id: 2
tp: 3
collation: 63
columnLen: 11
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
columns {
column_id: 3
tp: 15
collation: 46
columnLen: 100
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
columns {
column_id: 4
tp: 3
collation: 63
columnLen: 11
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
and material_creative_count=table_id: 29909
columns {
column_id: 1
tp: 8
collation: 63
columnLen: 20
decimal: 0
flag: 4099
default_val: “\000”
pk_handle: true
}
columns {
column_id: 2
tp: 3
collation: 63
columnLen: 11
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
columns {
column_id: 3
tp: 15
collation: 46
columnLen: 100
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
columns {
column_id: 4
tp: 3
collation: 63
columnLen: 11
decimal: 0
flag: 0
default_val: “\000”
pk_handle: false
}
at com.pingcap.com.google.common.collect.RegularImmutableMap.createHashTable(RegularImmutableMap.java:104)
at com.pingcap.com.google.common.collect.RegularImmutableMap.create(RegularImmutableMap.java:74)
at com.pingcap.com.google.common.collect.ImmutableMap$Builder.build(ImmutableMap.java:338)
at com.pingcap.tikv.catalog.Catalog$CatalogCache.loadTables(Catalog.java:189)
at com.pingcap.tikv.catalog.Catalog$CatalogCache.listTables(Catalog.java:162)
at com.pingcap.tikv.catalog.Catalog.listTables(Catalog.java:80)
at com.pingcap.tispark.MetaManager.getTables(MetaManager.scala:30)
at org.apache.spark.sql.catalyst.catalog.TiDirectExternalCatalog.listTables(TiDirectExternalCatalog.scala:57)
at org.apache.spark.sql.catalyst.catalog.TiDirectExternalCatalog.listTables(TiDirectExternalCatalog.scala:53)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listTables(SessionCatalog.scala:765)
at org.apache.spark.sql.catalyst.catalog.TiCompositeSessionCatalog.listTables(TiCompositeSessionCatalog.scala:158)
at org.apache.spark.sql.catalyst.catalog.TiCompositeSessionCatalog.listTables(TiCompositeSessionCatalog.scala:143)
at org.apache.spark.sql.execution.command.TiShowTablesCommand$$anonfun$2.apply(tables.scala:41)
at org.apache.spark.sql.execution.command.TiShowTablesCommand$$anonfun$2.apply(tables.scala:41)
at scala.Option.fold(Option.scala:158)
at org.apache.spark.sql.execution.command.TiShowTablesCommand.run(tables.scala:41)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:194)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:371)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:274)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
at com.pingcap.com.google.common.collect.RegularImmutableMap.createHashTable(RegularImmutableMap.java:104)
at com.pingcap.com.google.common.collect.RegularImmutableMap.create(RegularImmutableMap.java:74)
at com.pingcap.com.google.common.collect.ImmutableMap$Builder.build(ImmutableMap.java:338)
at com.pingcap.tikv.catalog.Catalog$CatalogCache.loadTables(Catalog.java:189)
at com.pingcap.tikv.catalog.Catalog$CatalogCache.listTables(Catalog.java:162)
at com.pingcap.tikv.catalog.Catalog.listTables(Catalog.java:80)
at com.pingcap.tispark.MetaManager.getTables(MetaManager.scala:30)
at org.apache.spark.sql.catalyst.catalog.TiDirectExternalCatalog.listTables(TiDirectExternalCatalog.scala:57)
at org.apache.spark.sql.catalyst.catalog.TiDirectExternalCatalog.listTables(TiDirectExternalCatalog.scala:53)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listTables(SessionCatalog.scala:765)
at org.apache.spark.sql.catalyst.catalog.TiCompositeSessionCatalog.listTables(TiCompositeSessionCatalog.scala:158)
at org.apache.spark.sql.catalyst.catalog.TiCompositeSessionCatalog.listTables(TiCompositeSessionCatalog.scala:143)
at org.apache.spark.sql.execution.command.TiShowTablesCommand$$anonfun$2.apply(tables.scala:41)
at org.apache.spark.sql.execution.command.TiShowTablesCommand$$anonfun$2.apply(tables.scala:41)
at scala.Option.fold(Option.scala:158)
at org.apache.spark.sql.execution.command.TiShowTablesCommand.run(tables.scala:41)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:194)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3364)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3363)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:194)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:79)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:642)
at org.apache.spark.sql.SQLContext.sql(SQLContext.scala:694)
at org.apache.spark.sql.hive.thriftserver.SparkSQLDriver.run(SparkSQLDriver.scala:62)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.processCmd(SparkSQLCLIDriver.scala:371)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:274)
at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
手动删还删不掉 。
mysql> delete from information_schema.tables where TIDB_TABLE_ID =29909;
ERROR 1142 (42000): DELETE command denied to user ‘root’@‘127.0.0.1’ for table ‘tables’
rename table Material_creative_count to Material_creative_count_29909;
rename table Material_creative_count to Material_creative_count_29944;
rename table Material_creative_count to Material_creative_count_37467;
直到 TiDB 报 Material_creative_count 不存在的错误。
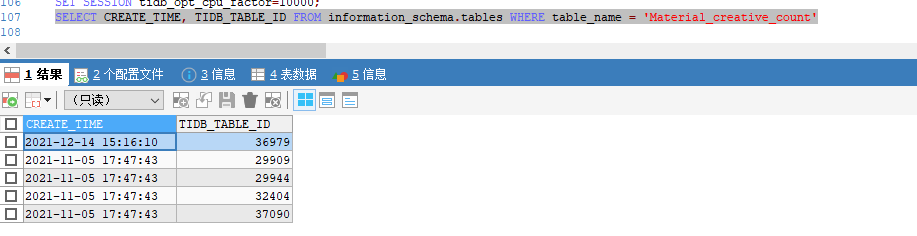
然后看哪些表是空的 drop 掉即可,假设非空的表是 Material_creative_count_29944,最后
rename table Material_creative_count_29944 to Material_creative_count;