【 TiDB 使用环境】
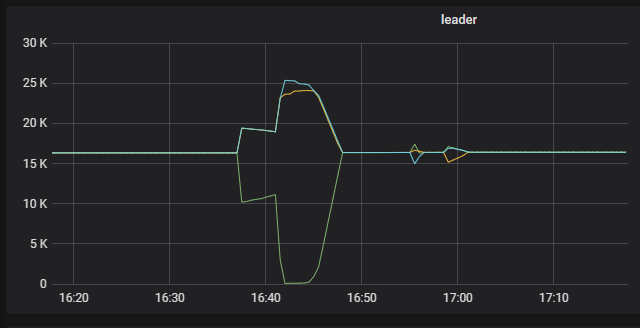
【概述】:生产环境tikv pod正常,grafana监控发现tikv-0 region全部迁移出去又迁移回来
【背景】:无任何操作
【现象】:业务正常
【问题】:无
【业务影响】:无
【TiDB 版本】:5.0.1
【TiDB Operator 版本】:v1.1.4
【K8s 版本】:1.12.4
【附件】:
1 个赞
可能是网络的问题,某个时间段这个tikv发生了离线,然后又加入到集群,期间leader发生调度,可以看看对应tikv的日志。
通常情况下当一个正常运行的 TiKV 节点上的 leader 大量迁移的可能原因如下:
- pd 的调度中有该 tikv 的 evict-leader 调度
- tikv 节点因异常无法提供服务:如 OOM,网络通信,磁盘卡顿或服务器故障等等,具体可以通过 tikv.log,网络通讯监控等信息进行确认
- tikv 节点遇到非预期报错,出现 panic
你上面的情况,建议检查下网络通讯情况 ~
tikv OOM了吧,检查一下内存的监控。

没有OOM,tikv.log这期间有大量日志,约23w行,再具体一些如何查看定位问题呢
如果方便的话,可以上传下:
1、对应的 tikv.log 日志
2、grafana tikv-details --> error 下的 metrics
3、pod 使用的 pv 磁盘监控相关信息

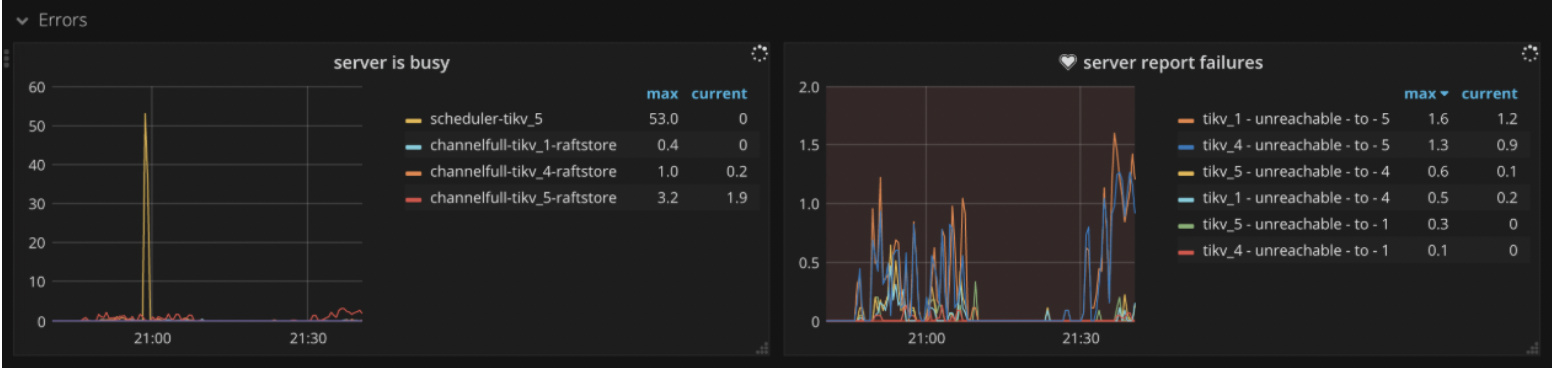

辛苦收集日志,这些日志的日期和时间在选择上,有些问题。如果出现问题的时间是 12 月 1 日 16:30 ~ 16:50,那么有些日志的时间没有覆盖该时间范围 ~
另外,辛苦导出下问题时间段的 tikv-details,tidb,pd 的 grafana 监控,导出方式参考 :
之前日志已覆盖出现问题的时间,时间段比较大,重新整理集中在问题时间段上。上传tidb-test-tikv-1.log (96.4 MB)
tidb-test-PD_2021-12-02T06_54_04.192Z.json (183.0 KB)
tidb-test-TiDB_2021-12-02T07_07_46.890Z.json (3.3 MB)
tidb-test-TiKV-Details_2021-12-02T07_09_11.529Z.json (8.4 MB)
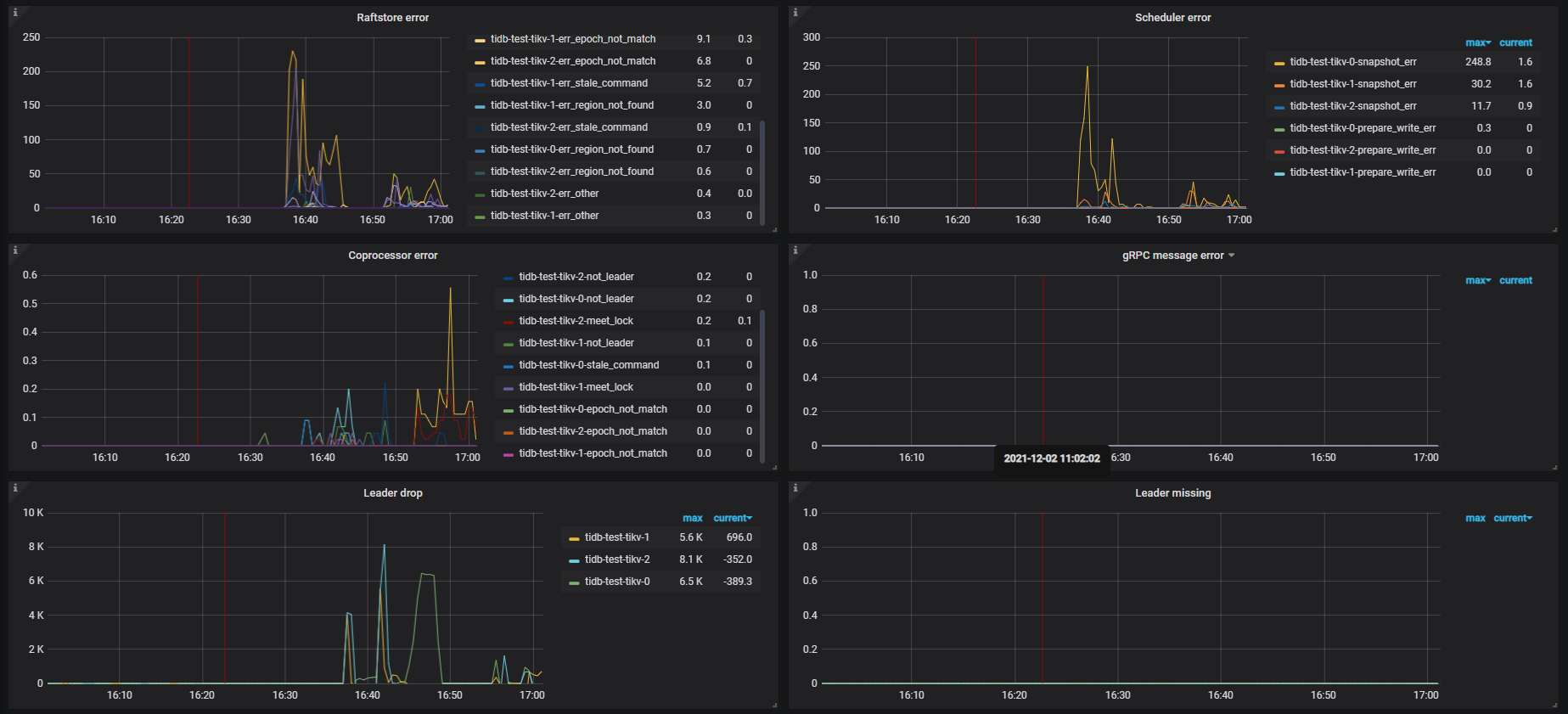
tikv-details 的监控信息显示不完整,很多 metrics 都没有显示,可能是导出时,没有等数据加载完成。
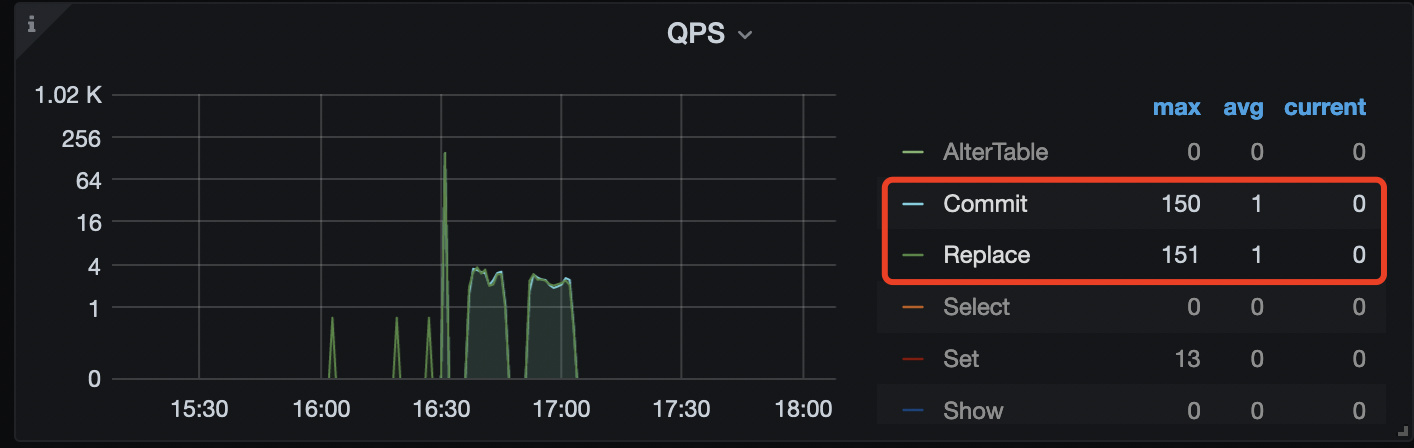
通过有限的监控项推测,可能是在 16:00 ~ 17:05 期间进行的 replace 行为的写入,于此同时 gc 开始工作
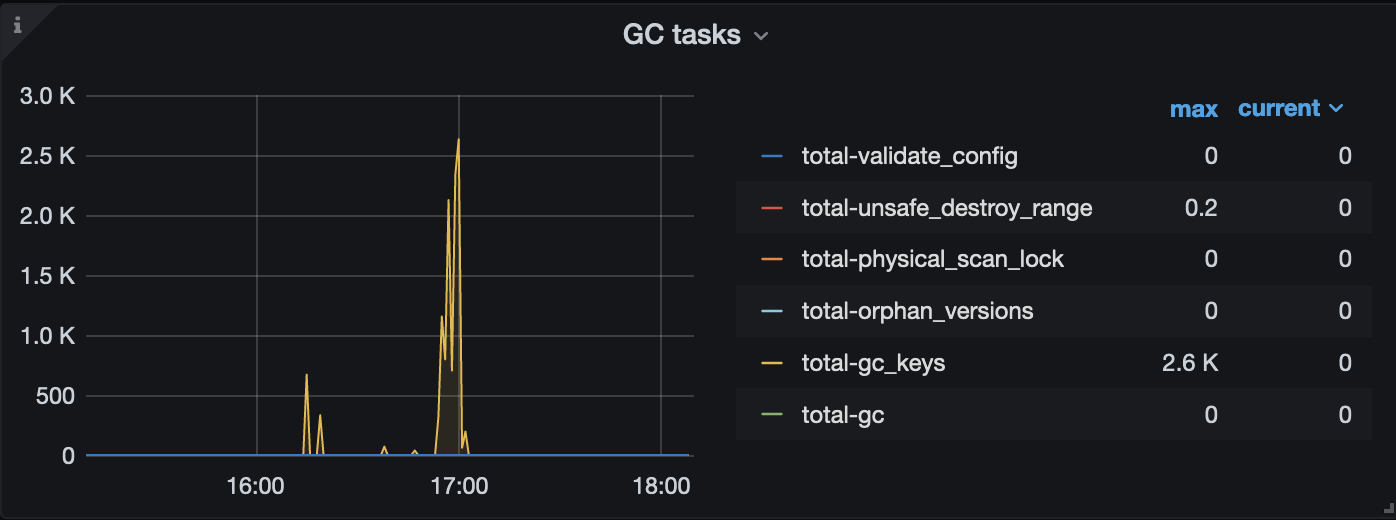
此时,rocksdb-kv 因为达到了 compaction 的阈值,开始进行 compaction 操作,整个集群的 read 、write 以及 compaction flow 较高:

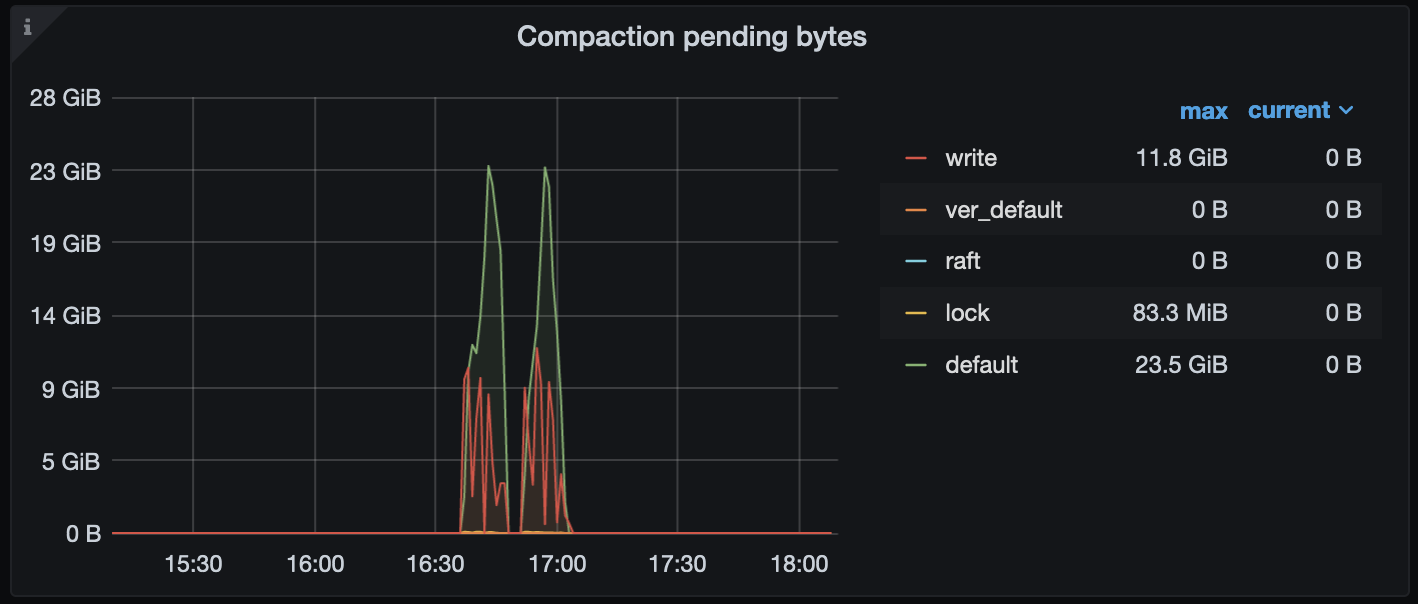
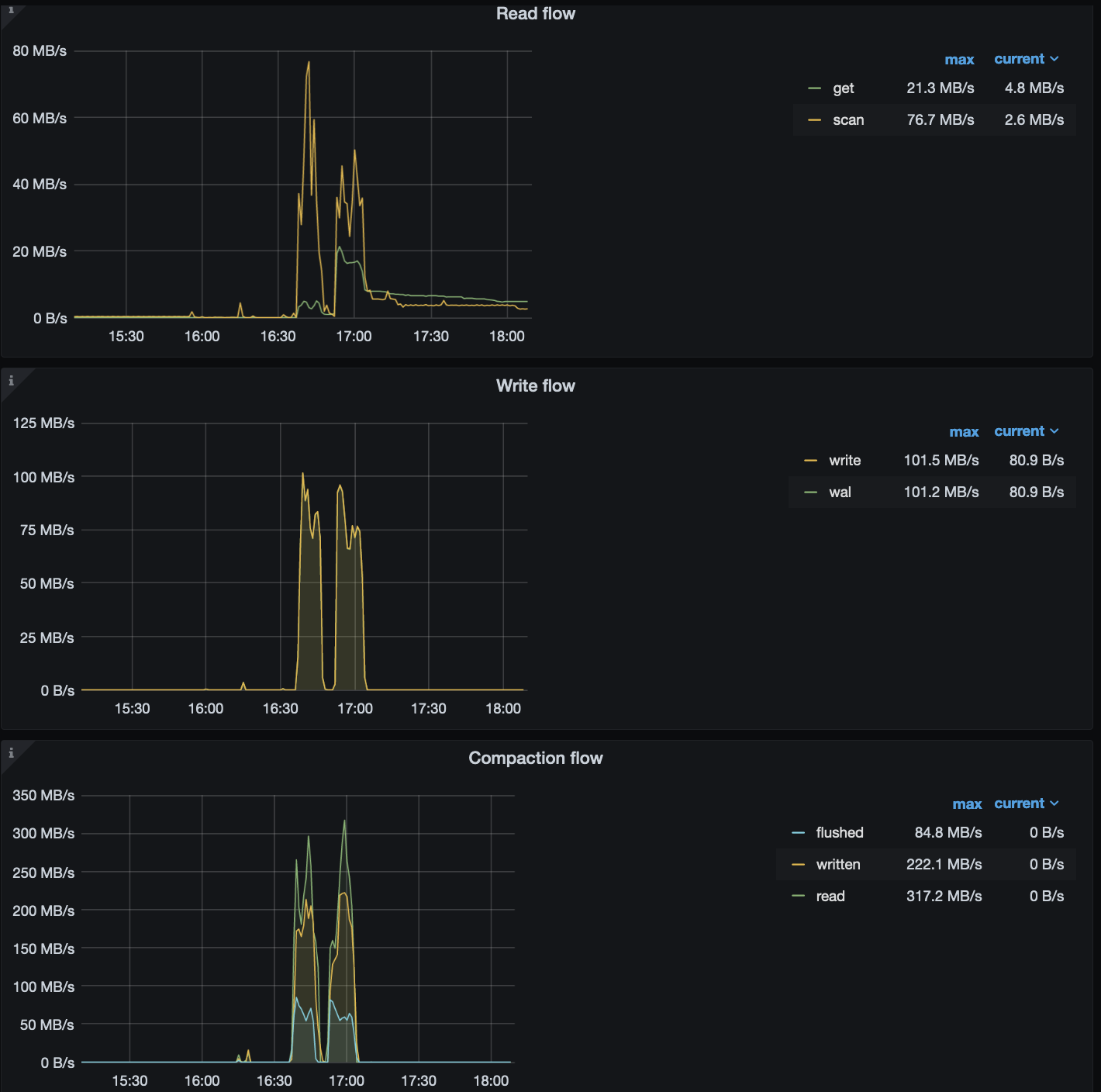
可能是磁盘流量大导致磁盘压力过大,进而出现了 leader drop 的现象。所以,建议检查下下述信息:
1、tikv1 和 tikv4 是在同一台宿主机吗?
2、使用的磁盘类型,以及检查宿主机或 pod 的磁盘监控, 包括磁盘 write latency,磁盘带宽等是否比较高或接近极限,以及服务器的负载情况
3、修改 tikv-details → rocksdb kv → compaction flow / compaction pending bytes 监控项公式,by instance,看下各个 tikv 的 compaction 流量情况。以 compaction pending 为例 参考公式如下:
metrics : sum(tikv_engine_pending_compaction_bytes{tidb_cluster="$tidb_cluster", instance=~"$instance", db="$db"}) by (cf,instance)
legend:{{cf}}--{{instance}}
监控迁移的起始时间是16:37
qps截图kv_prewrite最高
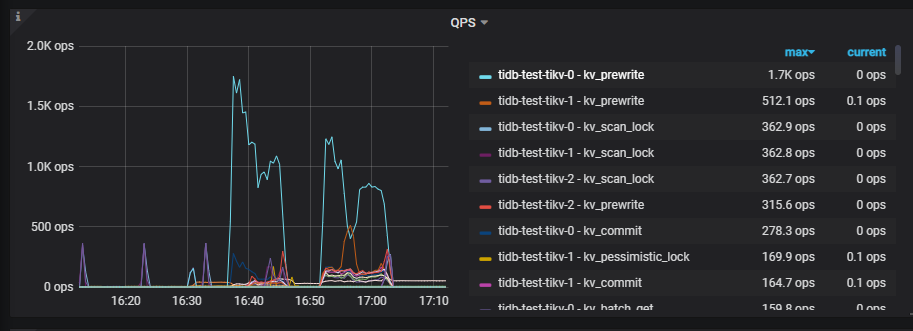
gc时间在近17:100:左右貌似和gc无直接关系
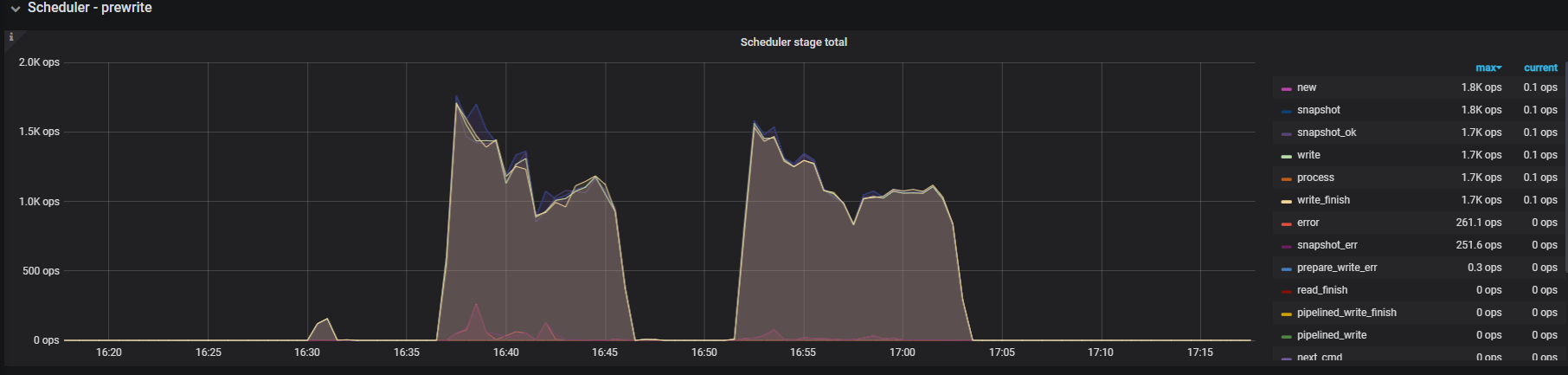
监控还需要什么信息,可以直接截图,grafana导出时页面卡死很长时间
tikv1 和 tikv4 是在同一台宿主机吗?只有0 1 2没有tikv4 不在同一台物理机上,nvme+100G网络带宽
下面获取值为空,麻烦给个具体监控项:sweat_smile:
sum(tikv_engine_compaction_flow_byte{tidb_cluster=“$tidb_cluster”, instance=~“$instance”, db=“$db”} / tikv_engine_pending_compaction_bytes {tidb_cluster=“$tidb_cluster”, instance=~“$instance”, db=“$db”}) by (cf,instance)
两个图直观截图如下:

磁盘nvme,xfs文件系统 通过mount bind方式产生pv,通过监控没发现吞吐很大
与业务沟通,17.04前后20分钟,都在导入新数据。导入的量级应该只有700w ,用 replace 导入的,新数据有400w ,剩下300w是更新。
1、看下监控信息
- tikv-details → thread cpu
- tikv-details → server → channel full
- tikv-details → cluster → Uptime
- TiKV-Details → Raft message → Messages 重点看下下面两个 metrics 的值
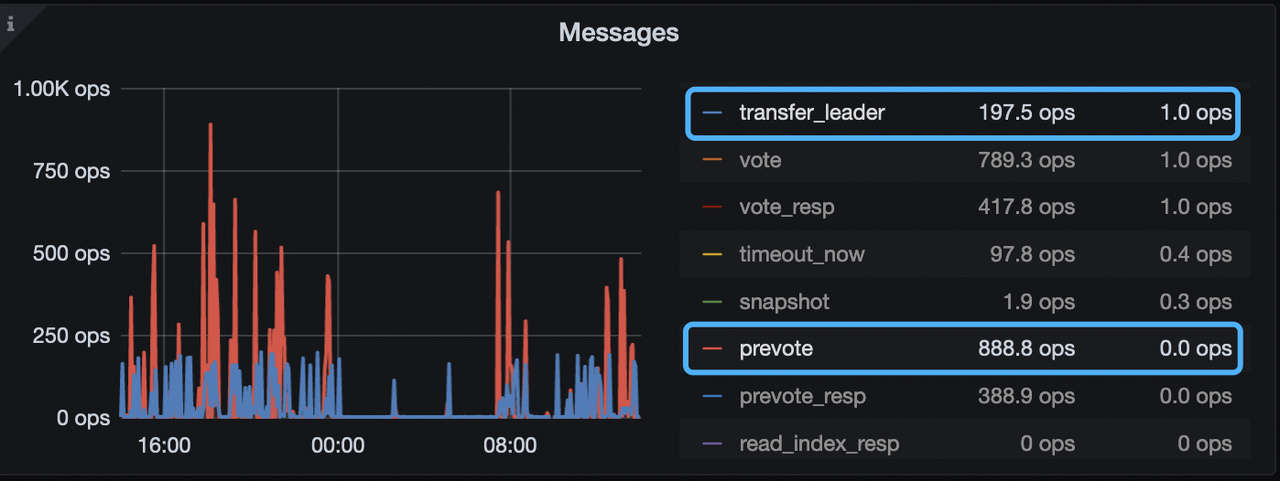
2、确认下参数配置
- 确认 tikv 的参数
store-pool-size当前值
3、其他
- 宿主机的磁盘的吞吐,以及写延时的监控方便的话,请上传下
- 在 3 个 tikv 节点上过滤下 region_id=4717299 的日志信息
另外,如果使用上面的方式导出监控困难的话,可以使用下面的方式导出一个 pdf 文件:
23、grafana 导出 pdf 监控
-
chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
-
鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
-
使用这个 full-page-screen-capture 插件进行截屏保存