1)上传中:screencapture-tidb-test-grafana-tidb-test-tikv-details-2021-12-03-11_27_18.png…
2)store-pool-size = 2 只能通过配置文件查看么
3)region_id=4717299 的日志信息 region.log (11.0 KB)
node的吞吐和延迟监控暂权限。
1)上传中:screencapture-tidb-test-grafana-tidb-test-tikv-details-2021-12-03-11_27_18.png…
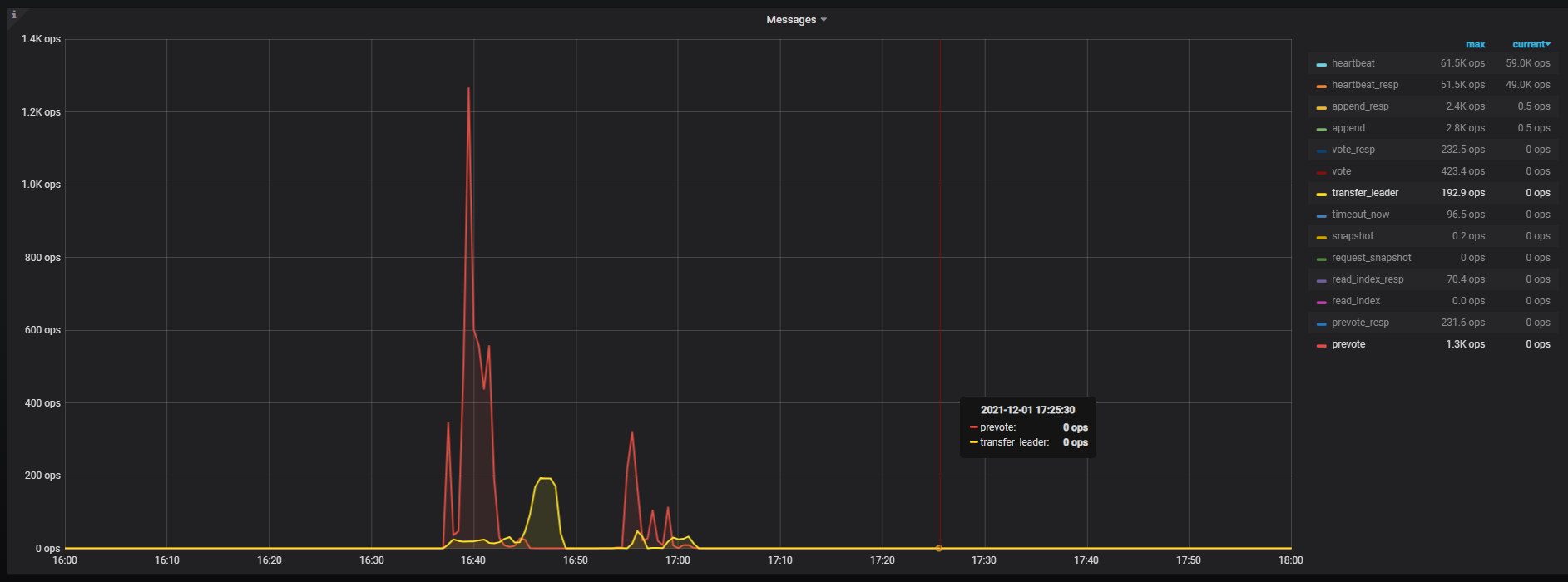
通过这个监控我们可以看到,整个集群中导致 leader 切换的主要原因是 prevote,这个表示是由 raft 选举产生了新的 leader。
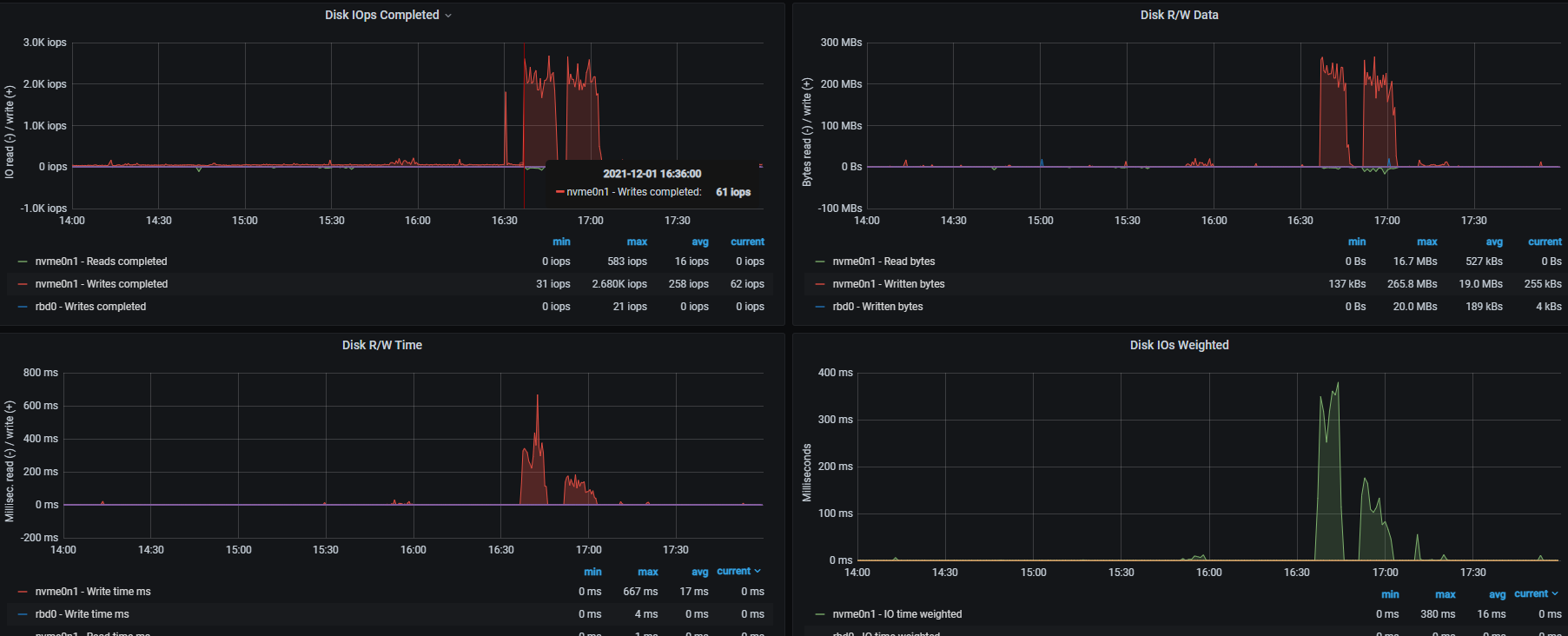
这个监控页面显示,在 16:35 ~ 16:45 左右,以及 16:50 ~ 17:02 左右,Disk R/W Time 和 Disk IOps Completed 出现了升高~
参数理论上可以通过下面的方式来查看:
show config where `type`='tikv' and name like '%store-pool-size%';
这个 pdf 应该是上传的有些问题,辛苦重新上传下吧,我们再看下 raftstore cpu 的问题谢谢 ~
看现象像是倒数据的那个表是个热点表 倒数据期间leader切换了 到数据和更新数据的表有几个region呢 是否触发了region分裂 期间region有没有增加
node exporter 信息screencapture-brainpp-cn-grafana-d-4VYPbJlmk-machine-node-exporter-full-2021-12-06-15_53_13.pdf (11.9 MB)
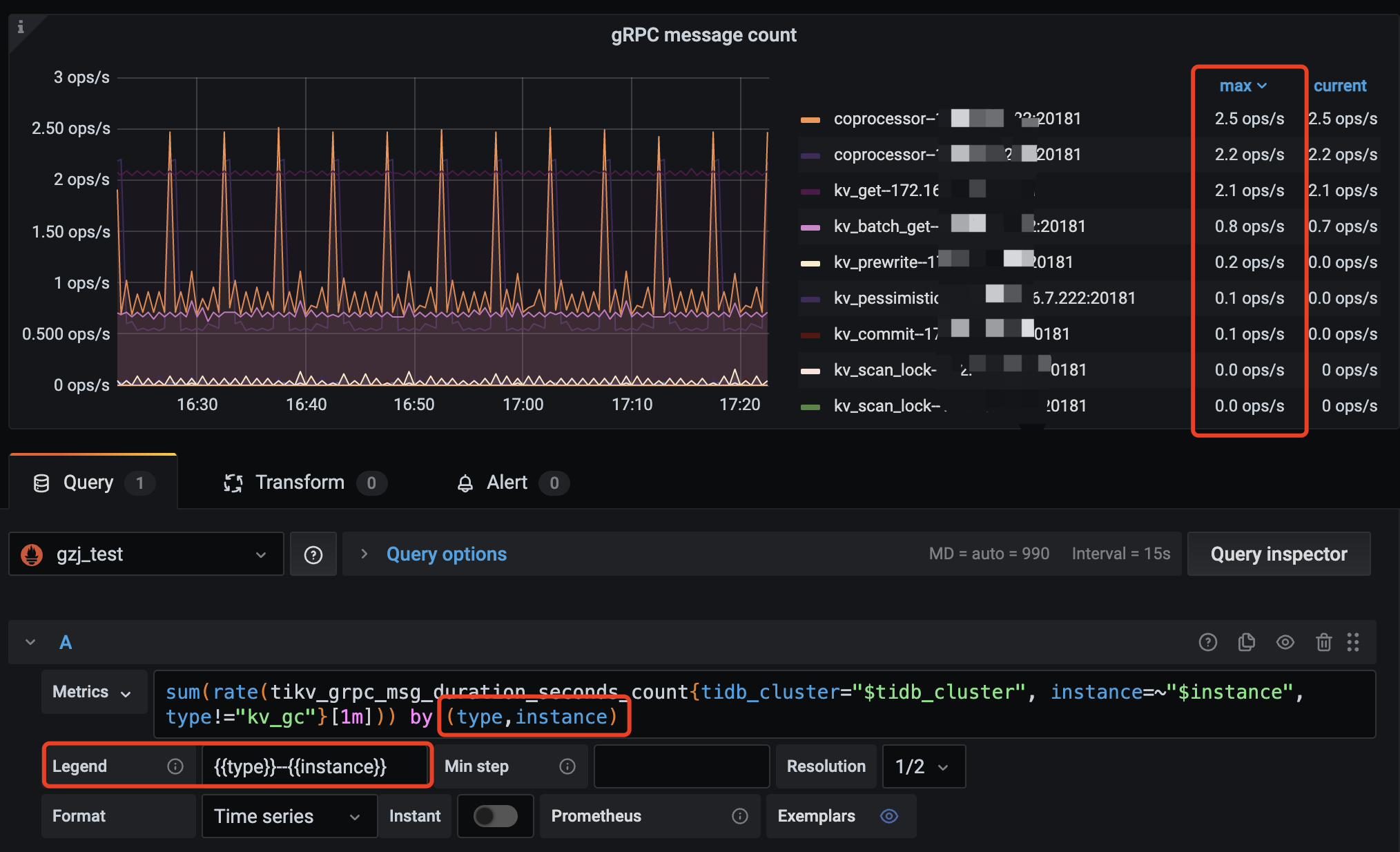
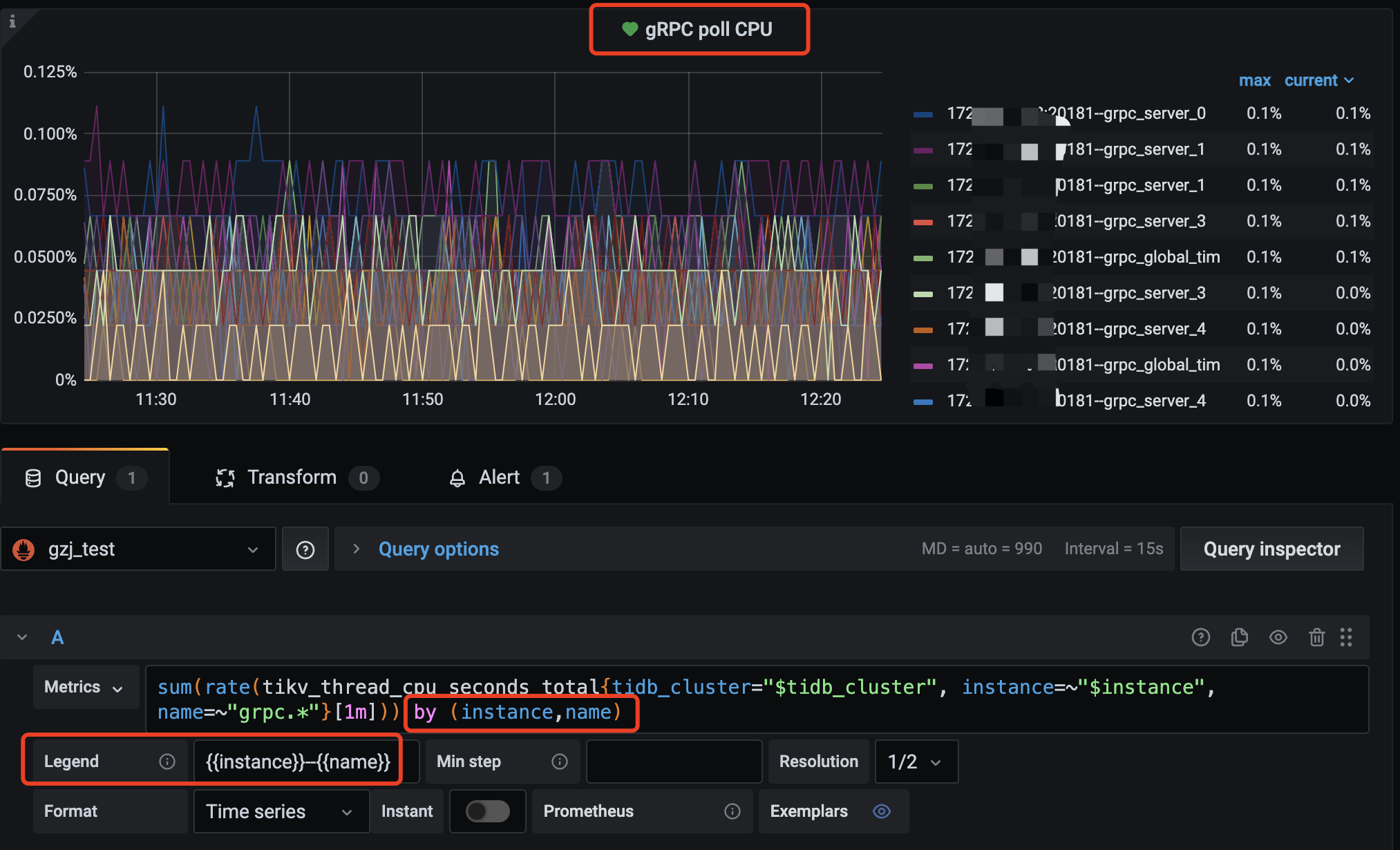
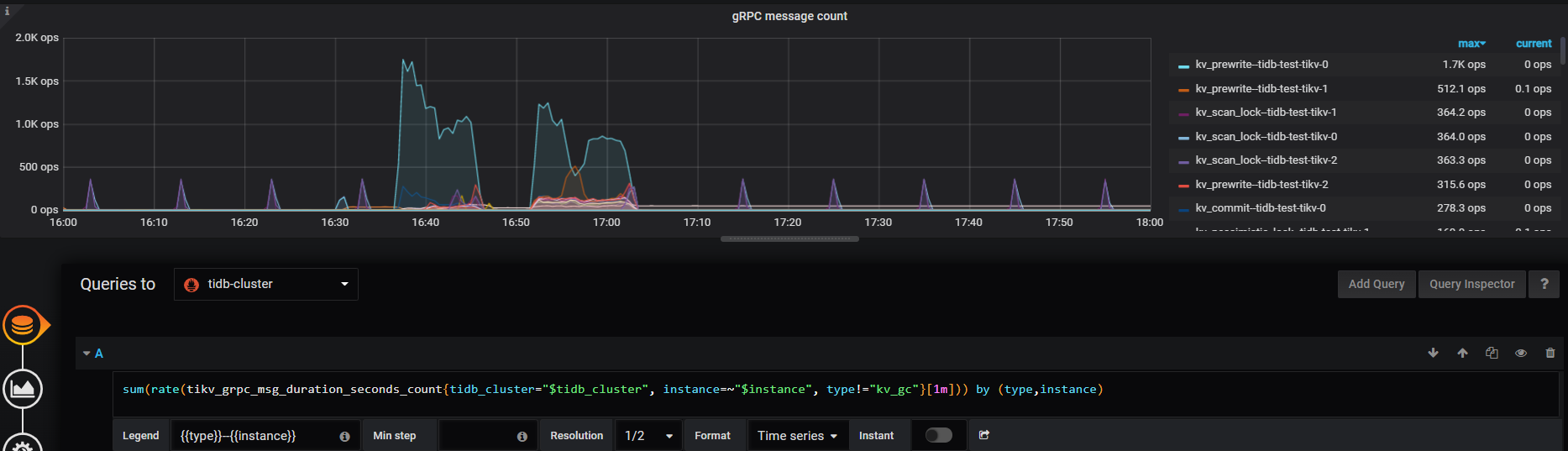
1、tikv-details → grpc 修改下下面的公式,按照 max 来排序看下各个 tikv 的情况:
2、这个监控是出现 leader drop 的 tikv-0 所在的宿主机的 node-exporter 监控吗?
3、tikv-details → server → channel full 监控
根据当前提供的监控以及日志信息,初步判断造成该问题的原因为:tikv0 因为热点,写入的量非常大,网络发送的速度跟不上新消息写入的速度,导致 replicate raft message channel 出现 full 。tikv0 和其他 tikv 节点心跳信息通讯异常。此时整个集群的写入速度也非常慢,并且宿主机磁盘性能可能出现了抖动,心跳信息通过 raftstore 发送,磁盘抖动,也可能导致出现掉 leader 现象。
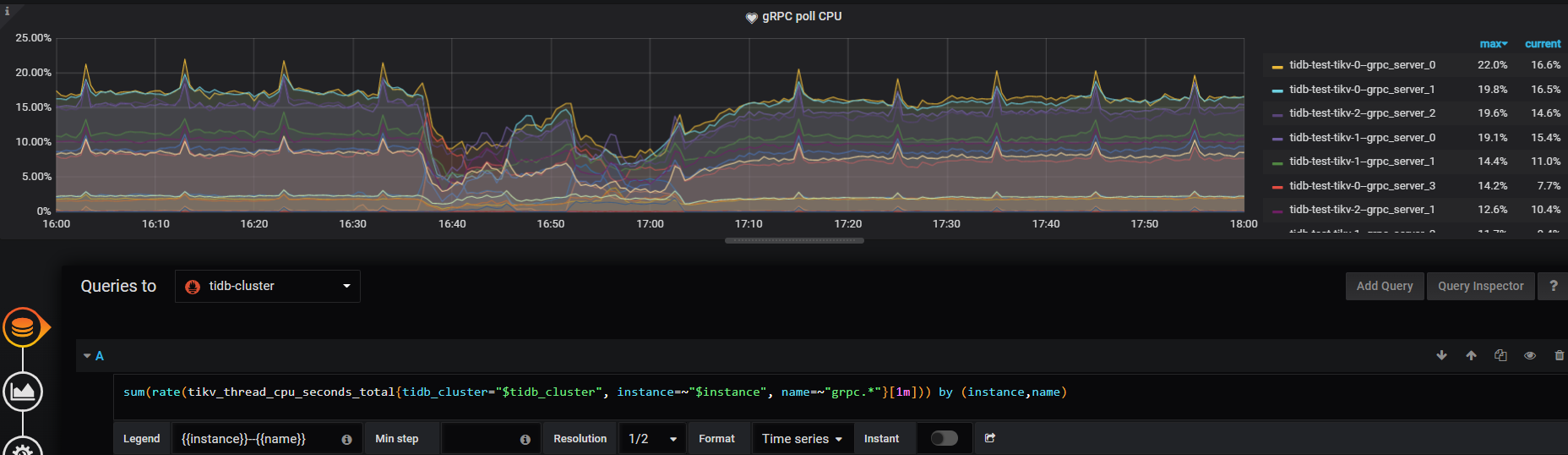
综上,网络发送的速度跟不上可以通过下述监控,来判断下,是否有某一个 grpc 线程被打满:
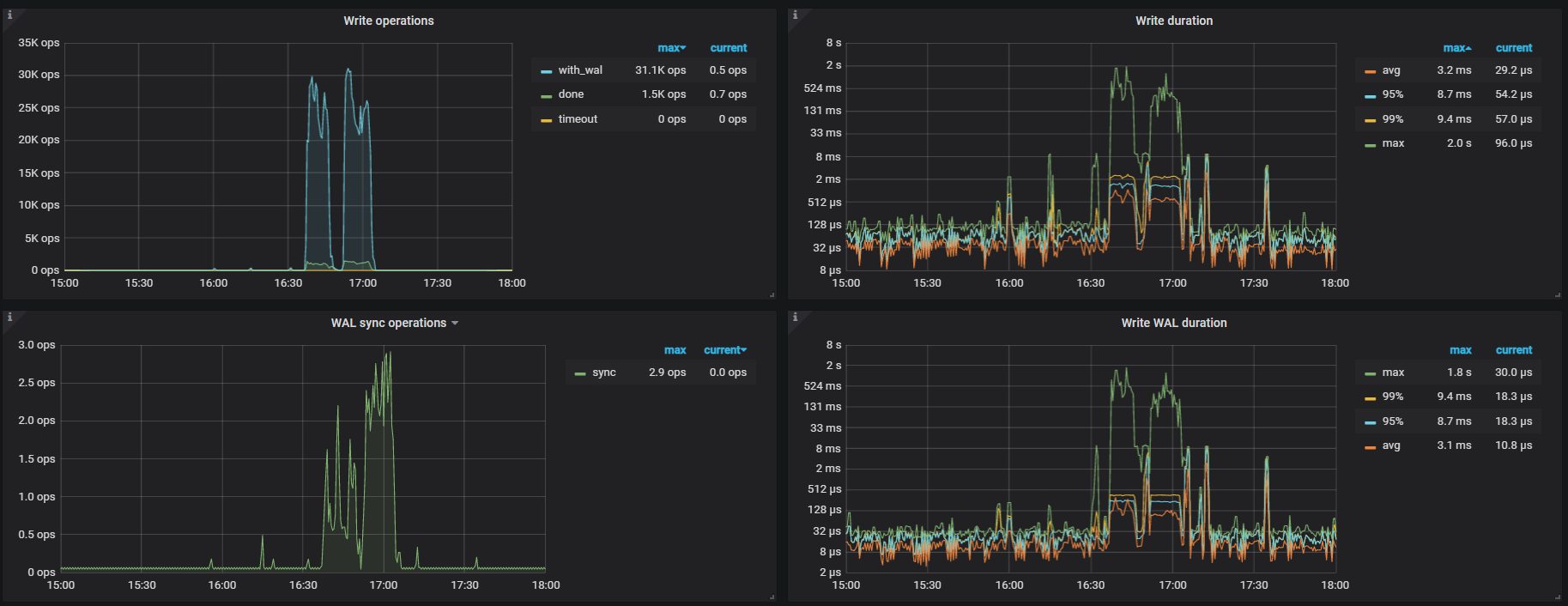
集群写入速度慢,或磁盘长尾情况,可以通过 raft io,raft propose 以及 rockskv – write duration / wal sync duration 来进一步判断~
基于上面的原因,建议做下面的操作:
1、打散数据写入热点,打散热点的方式在本站中有非常多的实践贴,可自行搜索
2、开启静默 region,从当前的监控可见 raft massage 中,心跳消息的数量远大于 append 数据写入的消息。开启方式见:https://docs.pingcap.com/zh/tidb/v5.0/tikv-configuration-file#hibernate-regions
建议做此调整后,观察下集群情况 ~
出现full,是通过哪个监控metric看到的
如果想了解 tikv 写入更详细的信息,可以参考下述帖子:
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。