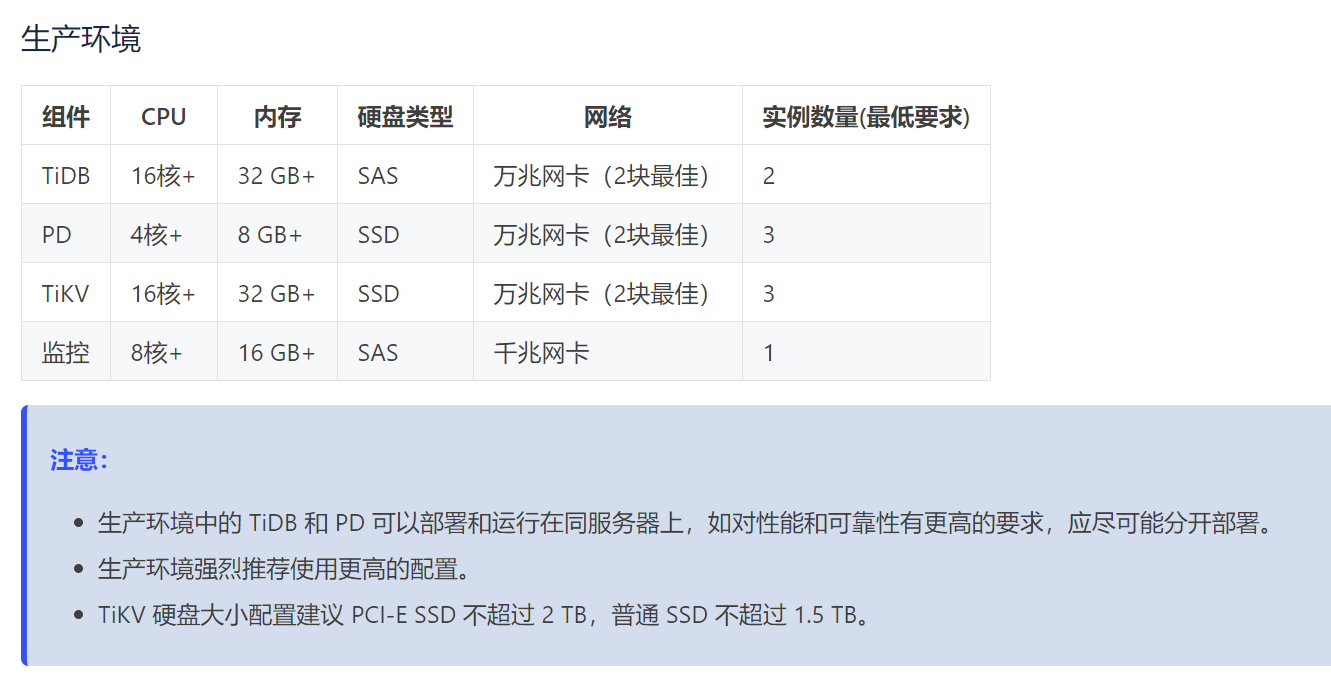
TiKV 硬盘大小配置建议 PCI-E SSD 不超过 2 TB,普通 SSD 不超过 1.5 TB;
tikv实例配置32G内存,单实例占用总内存的一半比较好, 也就是说服务器的内存最好可以配置到64G.
1 个赞
好像没有这个配置:
tidb@ip:~/tidb-ansible$ ./resources/bin/tikv-ctl --host=10.2.10.131:20160 modify-tikv-config -m storage -n block-cache.high-pri-pool-ratio -v 10
DebugClient::modify_tikv_config: RpcFailure(RpcStatus { status: InvalidArgument, details: Some("bad argument: block-cache.high-pri-pool-ratio") })
默认没有开启 high-pri-pool,这个可能会影响 data block 的 cache 命中率,建议不要调得太高,具体数值看 workload。
这个参数似乎不支持通过 tikv-ctl 修改。![]()
high_pri_pool_ratio 这个参数先改成 0.1 看下效果,不支持 tikv-ctl 修改。在 TiKV 配置文件的 block-cache 项下面加一下,注意语法格式,在配置文件里应该是要这么写:high-pri-pool-ratio。
大兄弟 你是用了tidb 做大数据存储了么 整体给感觉怎么样
一眼难尽啊,你什么场景啊?
这个不是HTAP么 所以想把大数据存储什么的 搞到这个上来 做个技术预研 看看你们这些大佬怎么搞的 好使不好使?感觉好像不能满足大数据场景哦
能做大数据计算么 能支持个什么场景 而且你们这个HTAP ap性能好像不是是很全面 完全依赖内存跑spark么
建议阅读一下相关博客信息了解下。https://pingcap.com/blog-cn/10x-improving-analytical-processing-ability-of-tidb-with-tiflash/
UUID是随机的吗?如果是随机的,不建议此字段做为主键(最好也不要用于索引),否则会导致频率的split
如果非要用UUID,建议UUID改为向上增长的
单表600多亿感觉应该做数据归档了吧
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。