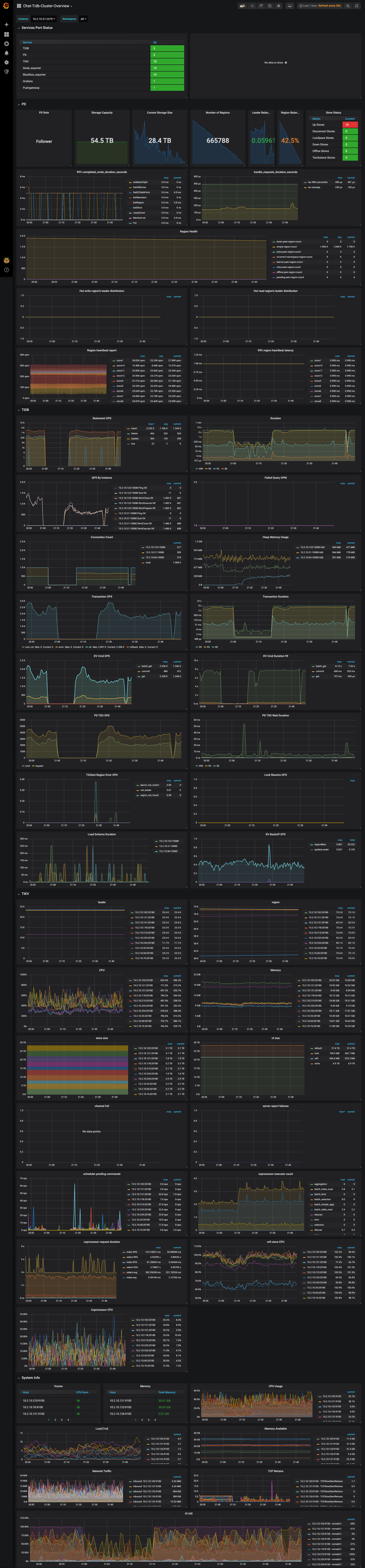
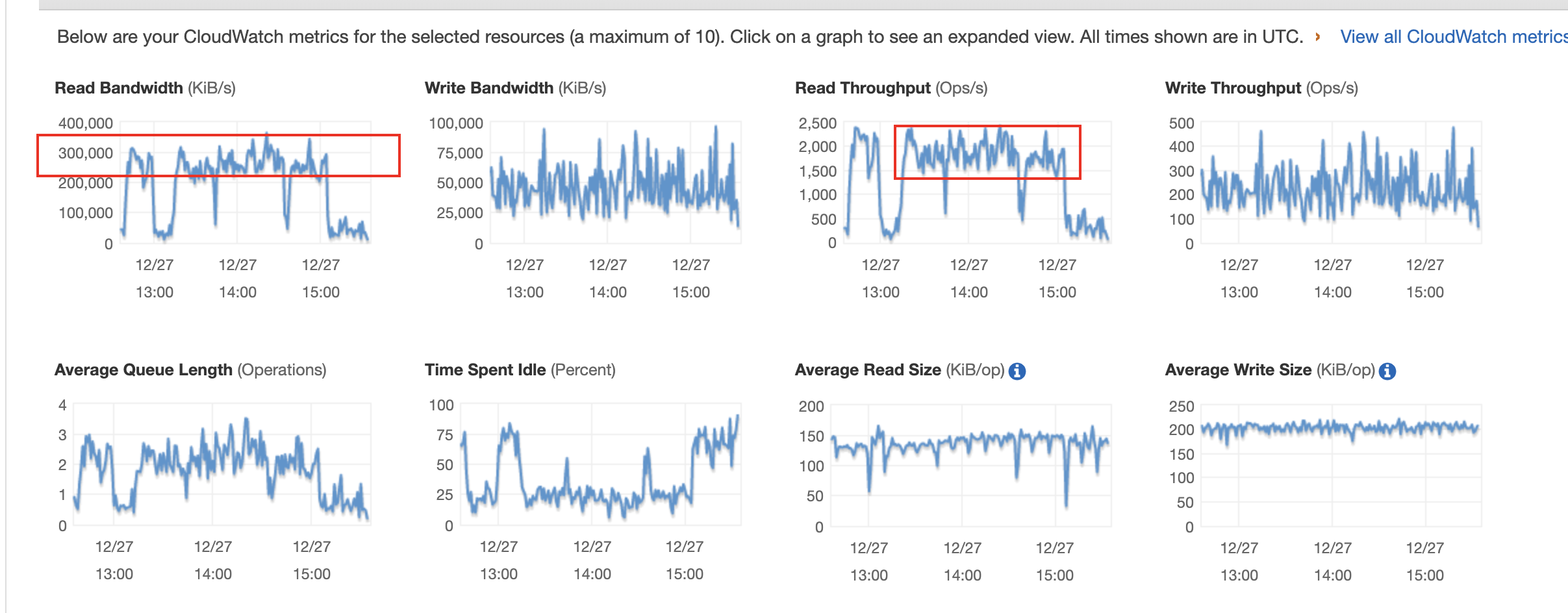
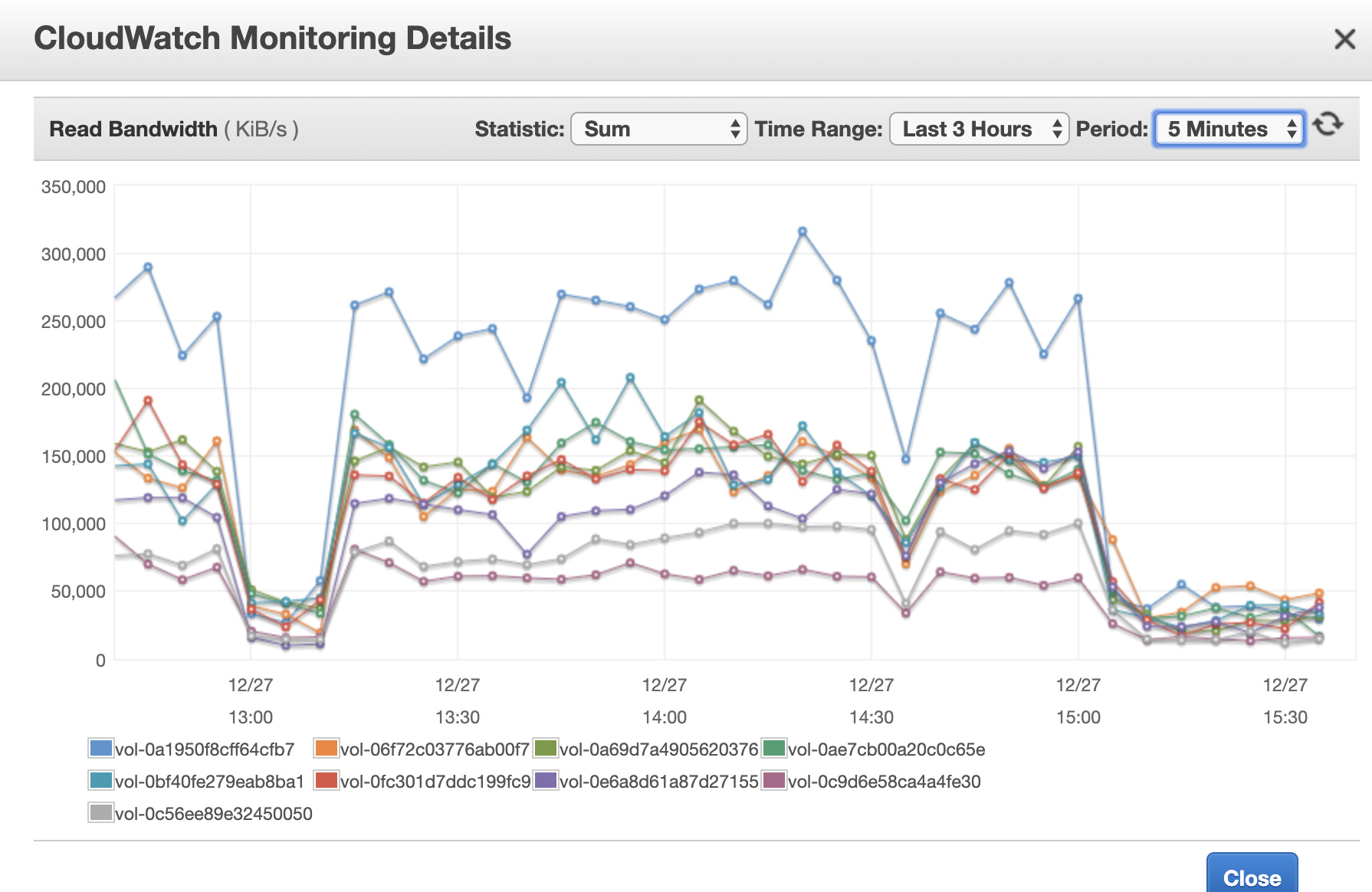
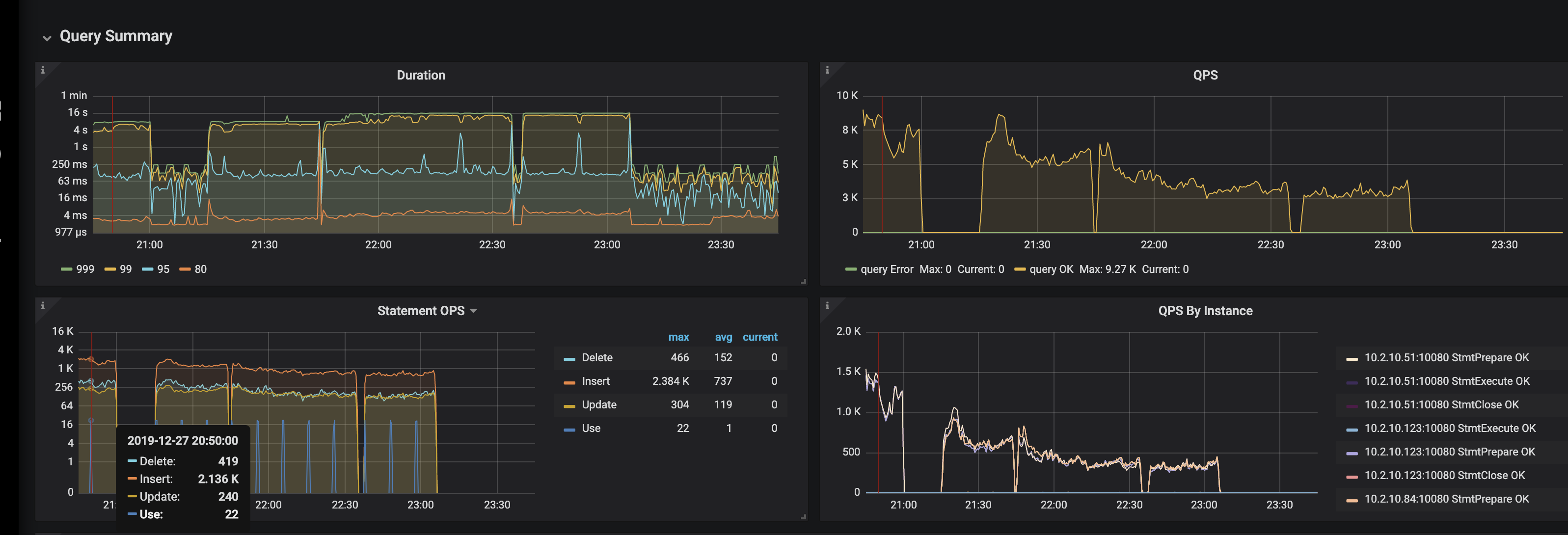
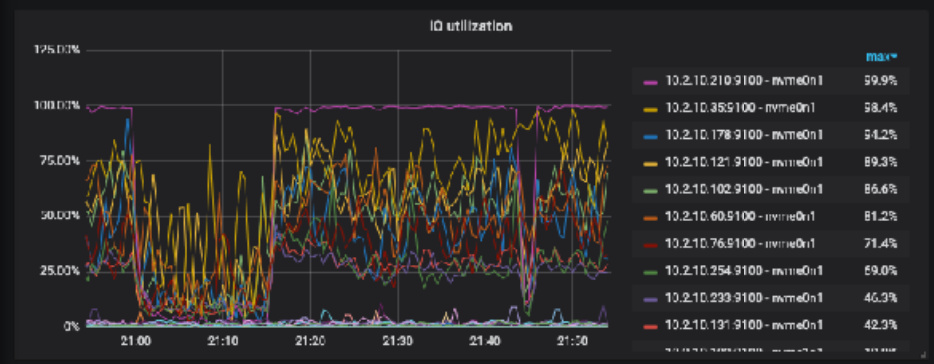
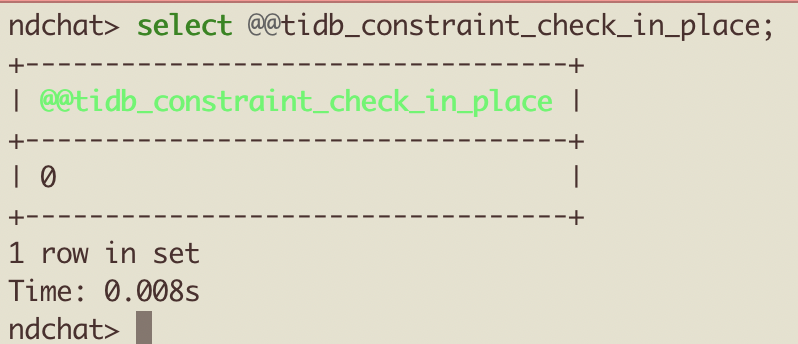
是磁盘 io 撑满了,我贴了 aws 磁盘的监控,insert 的时侯,读的流量非常大,上面贴的盘 300MB/s 的读。我没想明白为什么 insert 会导致读流量这么大?而且insert 的qps 并不大,当然我可以给磁盘继续增加 iops,但是不解决问题。
下面是我的数据表:
CREATE TABLE `g_chat_messages` (
`message_id` binary(16) NOT NULL,
`client_ref_id` int(10) unsigned DEFAULT '0',
`created_time` int(10) unsigned NOT NULL,
`media_type` tinyint(3) unsigned DEFAULT '0',
`message_type` tinyint(3) unsigned DEFAULT '0',
`ndc_id` int(10) unsigned NOT NULL,
`thread_id` binary(16) NOT NULL,
`uid` binary(16) NOT NULL,
`content` mediumtext COLLATE utf8mb4_general_ci DEFAULT NULL,
`extensions` mediumtext COLLATE utf8mb4_general_ci DEFAULT NULL,
`media_value` varchar(1000) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`message_id`),
KEY `idx_tid` (`thread_id`,`created_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci/*!90000 SHARD_ROW_ID_BITS=4 */
下面是一条 slow query 的log:
# Time: 2019-12-27T20:55:14.070916822+08:00
# Txn_start_ts: 413519396325032016
# User: root@10.12.10.217
# Conn_ID: 284418
# Query_time: 3.612195236
# Parse_time: 0.000078978
# Compile_time: 0.000035423
# DB: ndchat
# Is_internal: false
# Digest: 21ac279396eca3f13ae706353ccdb1a8cae894f0e8e3d656ce72859a9a19251d
# Num_cop_tasks: 0
# Prepared: true
# Has_more_results: false
# Succ: true
insert IGNORE INTO g_chat_messages (message_id, client_ref_id, created_time, media_type, message_type, ndc_id, thread_id, uid, content, extensions, media_value) values (?,?,?,?,?,?,?,?,?,?,?) [arguments: (���t�GT�>�U�-��, 646995120, 1576469952, 0, 0, 244304829, �4�q�rF�g�b��, ۙ$�Le����4�, CLEUR, {}, NULL)];
非正常字符是 binary 的 uuid
从上面的 slow log 上可以看出 query 非常耗时,为啥 insert 要去 query,而且从磁盘侧监控看 query 的量如此巨大?
还有是不是单表数据量太大的原因,这张表里插了 630 亿的数据,我在同样的这个集群开一个新表,insert iops 很容易上 2w。