update 和 delete 都是根据主键来更新的,也不应该产生大量的读。这个读太夸张了:

并且感觉在读一个没有索引的东西,因为磁盘io很大,但是网络io基本没有变化,说明费了很大的 io 真真用的数据是很小的。
update 和 delete 都是根据主键来更新的,也不应该产生大量的读。这个读太夸张了:
并且感觉在读一个没有索引的东西,因为磁盘io很大,但是网络io基本没有变化,说明费了很大的 io 真真用的数据是很小的。
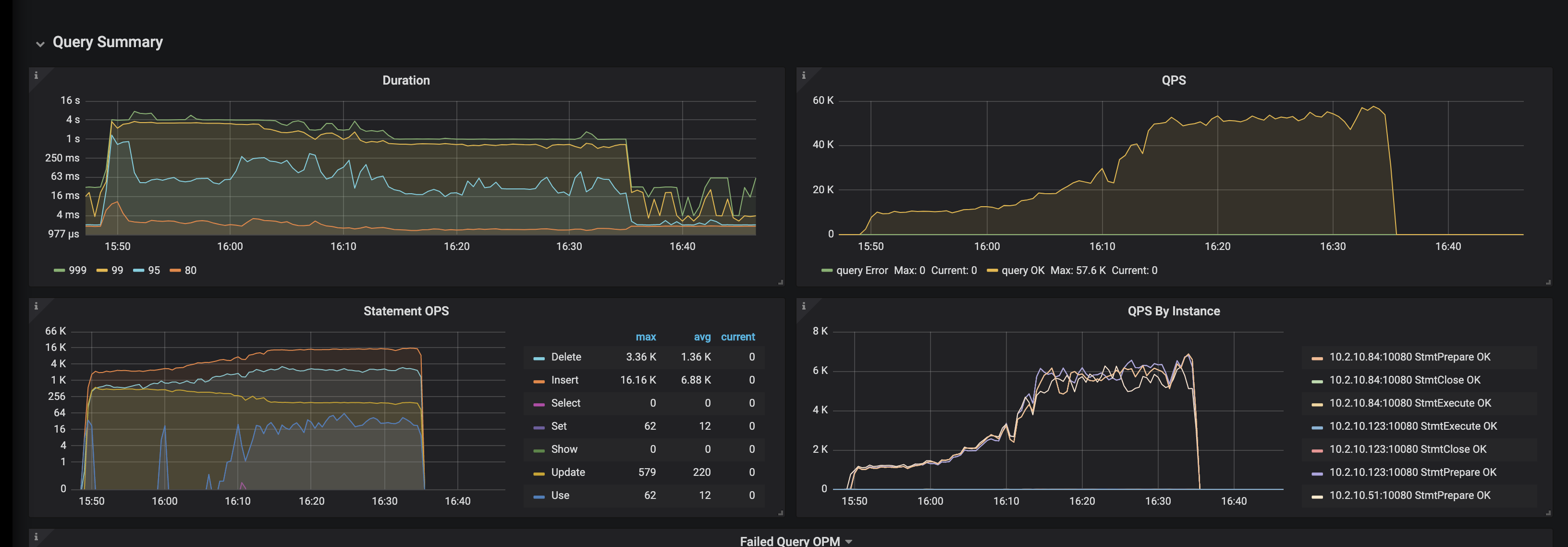
这个图是在做什么,和之前图的时间不一样
这个 query_time 名字有些误导,其实应该是 “sql_time”,代表的是整个 sql 的执行时间,不是 insert 中查询部分的时间- -
另一方面监控中可以看到到大量 kv_get 操作的原因是 insert ignore 的时候会 tidb 会向 tikv 发 kv_get 来判断重复(也就是 g_chat_messages 表中的 primary)
是我在 insert 的时侯的截图,和前面的时间是不一致,做的事情是一样的,都是在 insert
单纯对 insert 有 kv_get 大量这个问题,比较简单有效的方法可以试下,将
func InsertMessage(db *sql.DB, event ChatMsgEvent) (err error) {
修改为
func InsertMessages(db *sql.DB, events []ChatMsgEvent) (err error) {
然后下面拼的 sql 从
insert IGNORE INTO g_chat_messages (message_id, client_ref_id, created_time, media_type, message_type, ndc_id, thread_id, uid, content, extensions, media_value) values (?,?,?,?,?,?,?,?,?,?,?)
改为
insert IGNORE INTO g_chat_messages (message_id, client_ref_id, created_time, media_type, message_type, ndc_id, thread_id, uid, content, extensions, media_value) values (?,?,?,?,?,?,?,?,?,?,?),(?,?,?,?,?,?,?,?,?,?,?),(?,?,?,?,?,?,?,?,?,?,?),(?,?,?,?,?,?,?,?,?,?,?),(?,?,?,?,?,?,?,?,?,?,?),(?,?,?,?,?,?,?,?,?,?,?).....
在一个 sql 中做批量,可以在 insert ignore 这个场景下减少 kv_get 的数量
所以,有没有可能是因为布隆过滤器的错误率太高了,导致大概率都要去读磁盘,今天和 @Damon-PingCAP 一起看了这个问题,我们把 block cache 调大了很多,insert 的 QPS 上万了,看监控发现 cache hit 也上来了。
今天调大了block-cache,恢复gc从1分钟到10分钟默认值,增加了gc的流控. 上面@robi说的,你可以修改一下,一次批量插入,减少扫描次数. 观察一下变化.
你好,使用 sql 批量的方法和单个的方法表现一致,我这边测下来,效果差不多,磁盘的读 IO 很快就打满了,晚上,我把 autocommit 设置为 true 继续插入,qps 又上不去了。
我使用 sql 批量插入的办法,通过监控可以看到 tikv 的 cpu 占用小很多,但是磁盘读 IO 依然爆炸。
问题排查中,稍后回复
今天还有一个小细节,我们刚改大 cache 之后,速度并没有上来,而是继续排查等了很长一段时间之后,发现 qps 上万了,感觉还有个 warm up 的过程,如下图,希望可以帮助排查问题:
所以我猜想有没有可能是底层 rockes db 的问题,布隆过滤器的错误率太大,导致检查一个key是否存在要去读磁盘?
我还有个猜想, 当前每个 tikv 下的 rocks db 的 sst 文件接近有 20w 左右,而8.1M的小文件 sst 有12W,因为随机插入的关系,tikv 是不是要把所有的 sst 文件打开才可以,并且读取一定的数据量才行?
数据第一次读取到block cache之后,下一次就可以不走磁盘从内存读取了,所以有一个过程,比较正常.
请问插入的时候是完全随机插入的吗?我感觉主要原因还是 block-cache 不够用影响 QPS。可以截一下 tikv 的 block cache 相关的 metrics 吗?把时间跨度调长一些,让曲线同时包含 block-cache 之前和之后方便对比观察。
主键是 UUID,完全随机的,下面是 block cache 的截图:
昨晚我把 block cache 调到了 60GB,QPS 有上到过一万,现在的 QPS 配置是 16GB,QPS 跑了一晚上,早上才到 5k 多,磁盘 IO 还是爆满状态:
我重启换了下机器型号,测了一下,又换回来了。
那从目前的结论看,我只能加大内存才能缓解这个问题了,对吧?
是的, 另外昨天调整block cache,你重启后可能就恢复默认配置了,你在查一下日志确认下,配置文件里也可以改为你想要的值。
你好,那你们这边有经过实践得出的合理的内存和磁盘的空间比吗?
看监控似乎是 filter_evict 太高,也就是缓存 bloom filter 的 cache 不够用。
可以考虑在调大 block cache 本身调大的同时,适当调大一点 storage.block-cache.high-pri-pool-ratio 的值,这个参数是控制 block cache 中 bloom filter block 和 index block 的比例。
你好,storage.block-cache.high-pri-pool-ratio 默认值,我没找到相关的文档,多大算比较合理的大呢?