【版本】 v5.0.3 ARM
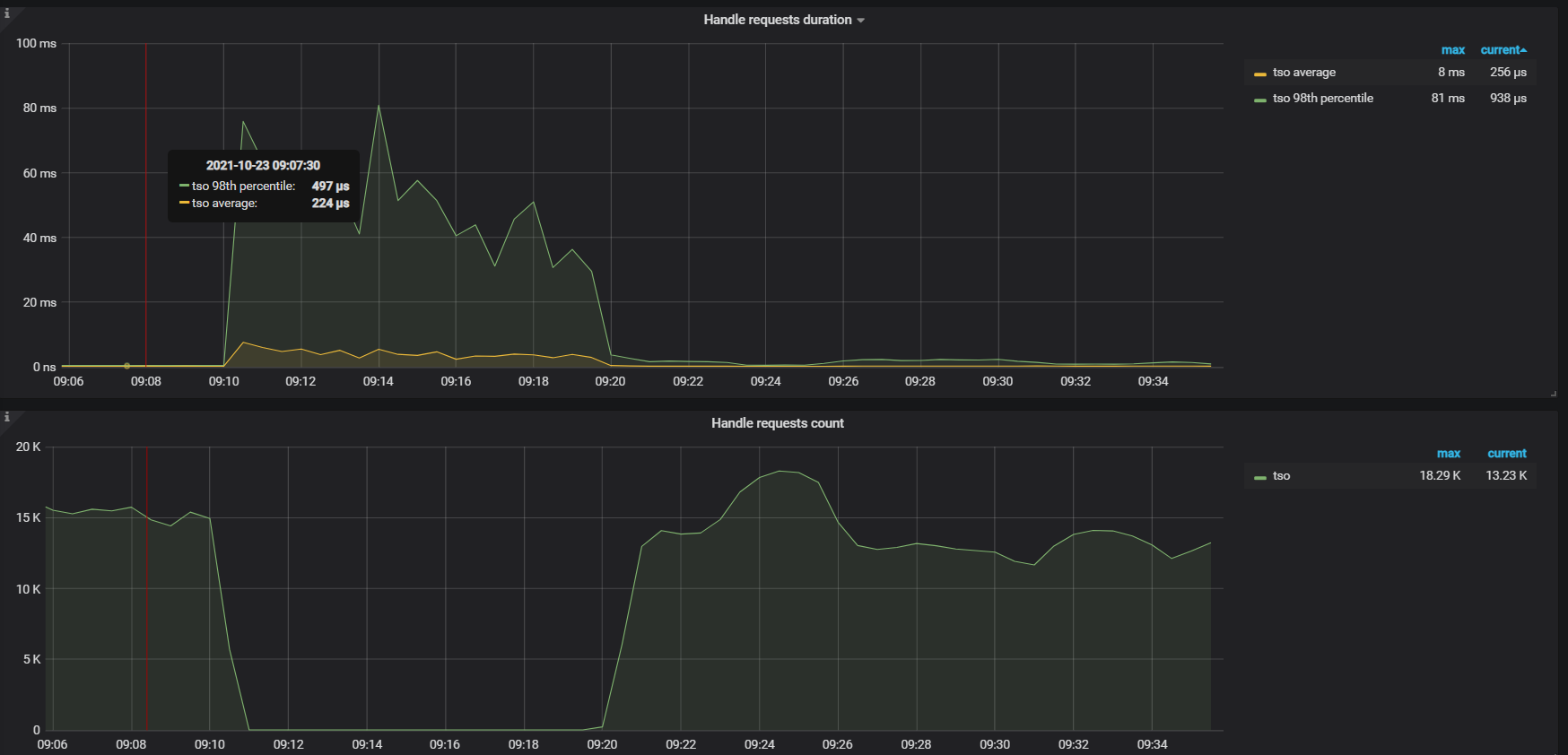
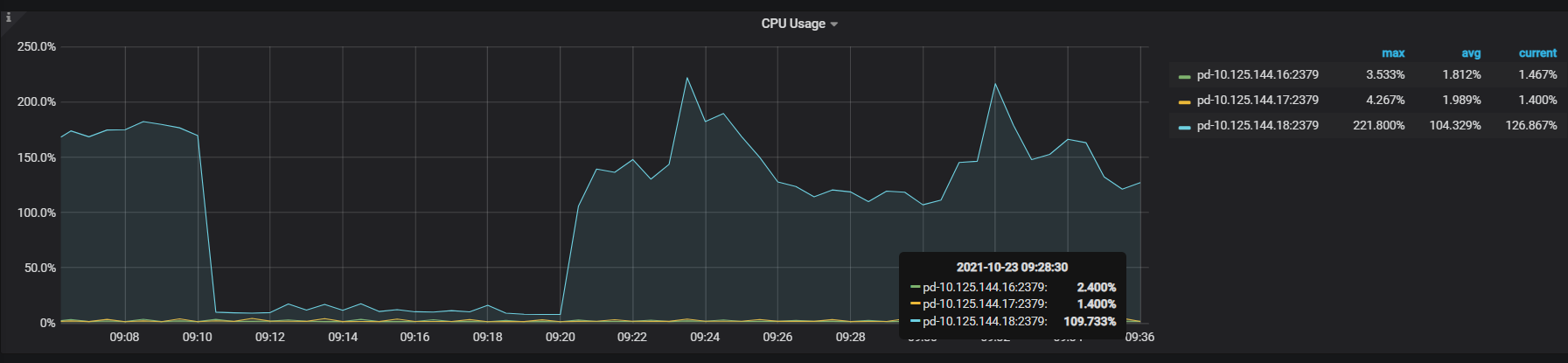
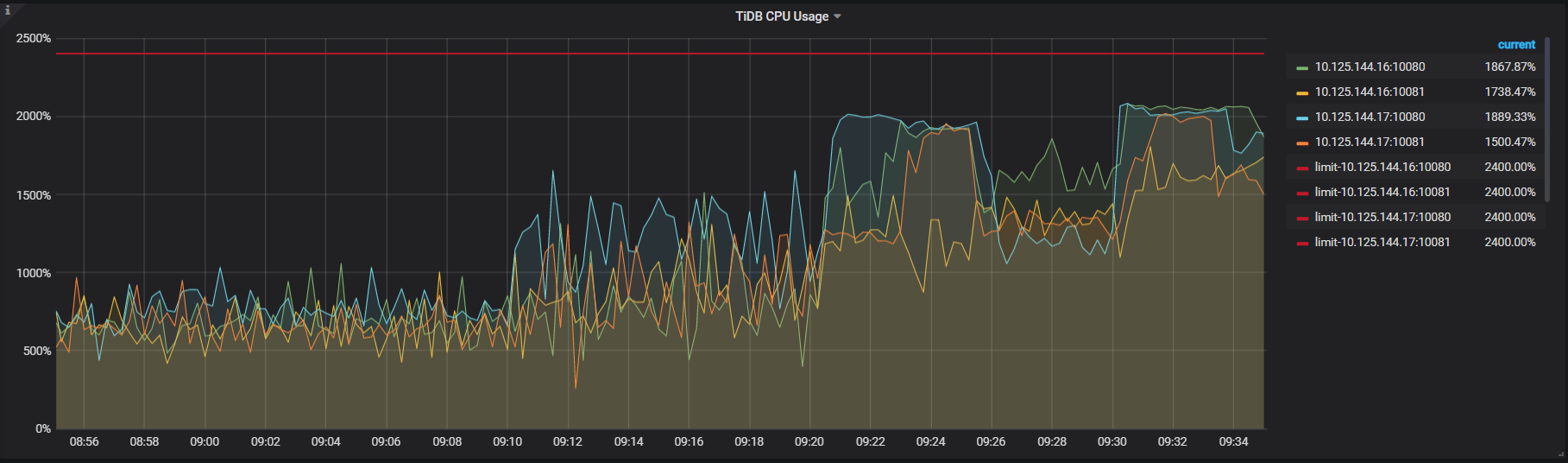
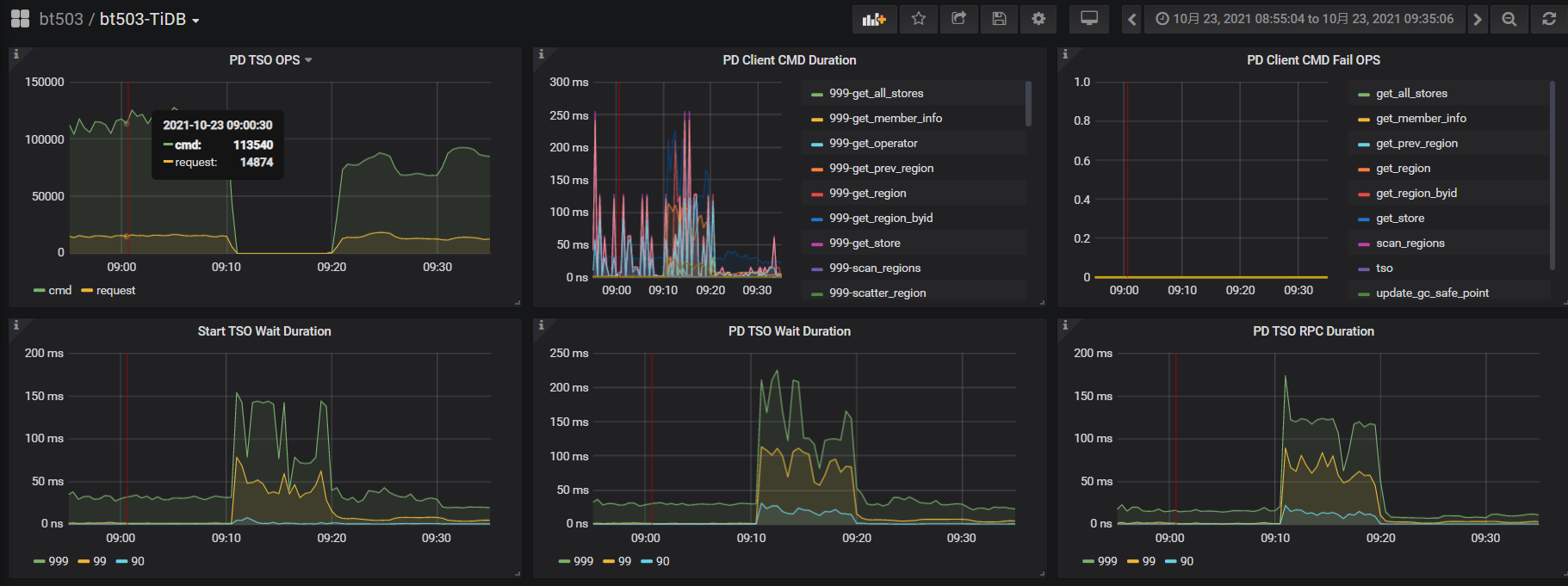
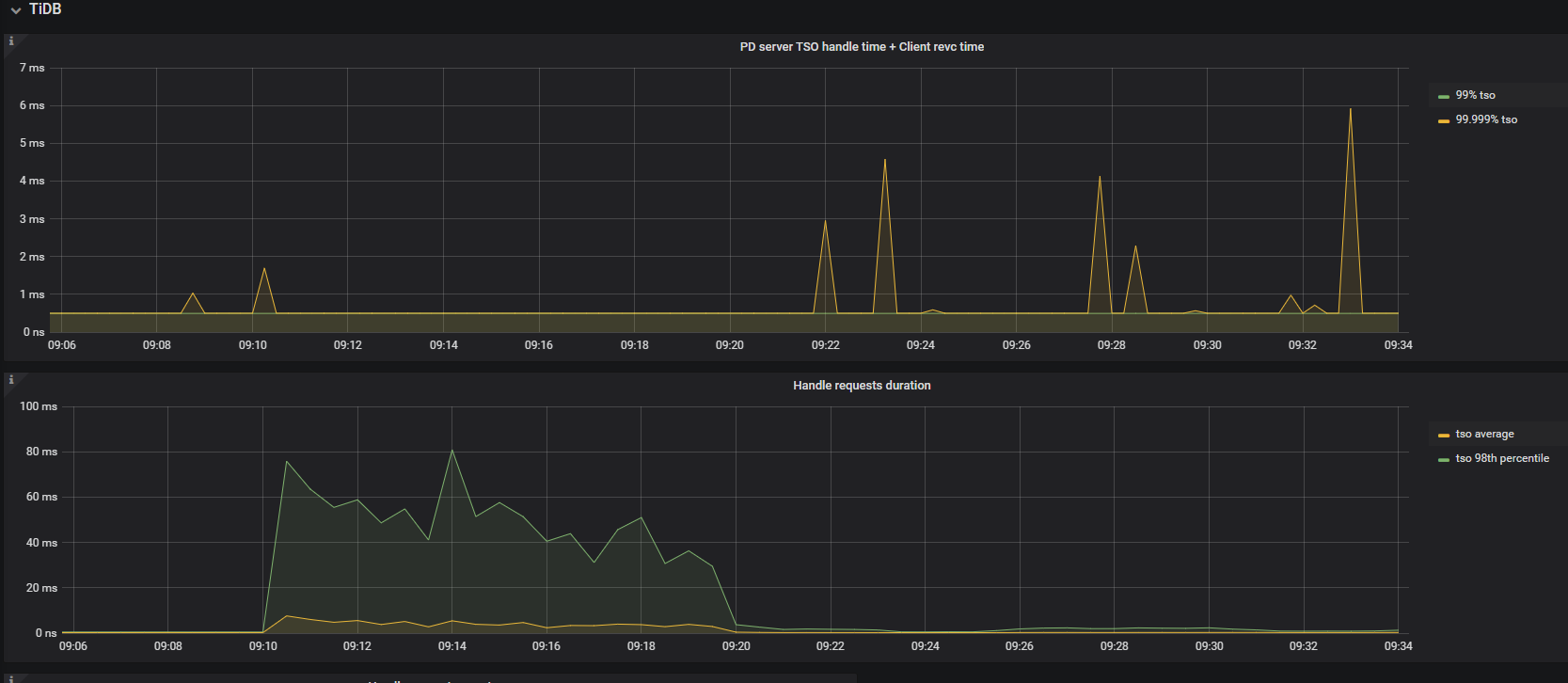
sysbench oltp_point 256线程压测时,pd tso wait duration升高,tso ops几乎为零,pd CPU大幅下降,检查网络延迟带宽、磁盘IO无问题,tidb CPU(numa绑核24核)也不高
【版本】 v5.0.3 ARM
sysbench oltp_point 256线程压测时,pd tso wait duration升高,tso ops几乎为零,pd CPU大幅下降,检查网络延迟带宽、磁盘IO无问题,tidb CPU(numa绑核24核)也不高
麻烦提供部署拓扑和主机配置以及当时做了什么操作?谢谢!
从上面监控看 PD TSO RPC Duration 时间很高,需要再排查下监控面板中 PD → TiDB → 指标 PD server TSO handle time + Client revc time ,如果该指标值不高,那大概率是网络层面有问题,如果该值也非常高,需要排查下 PD 在处理 TSO 请求时耗时高的原因,可以参考下面这篇文档排查下:
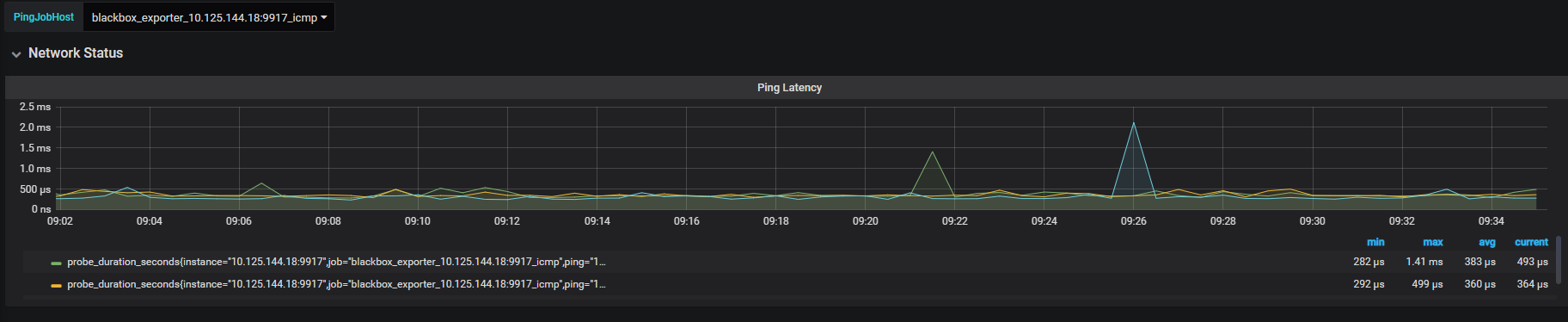
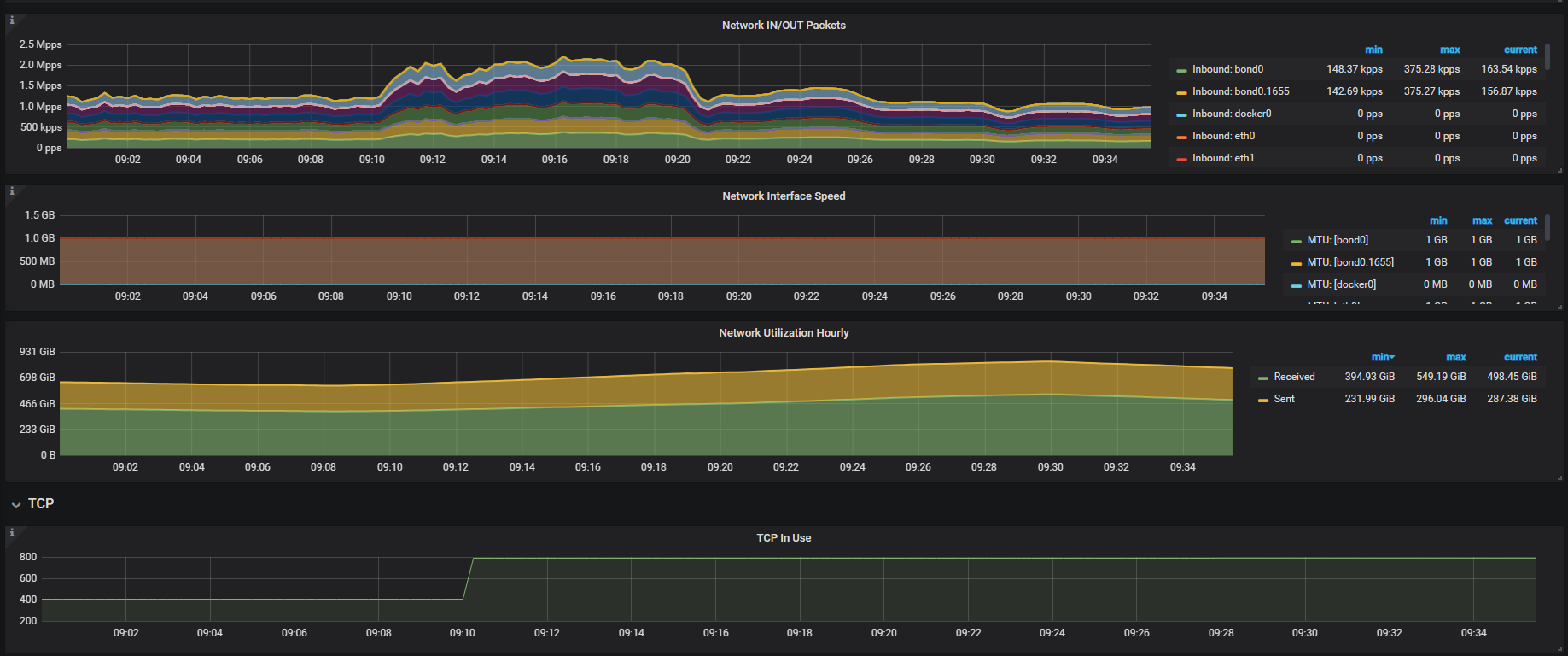
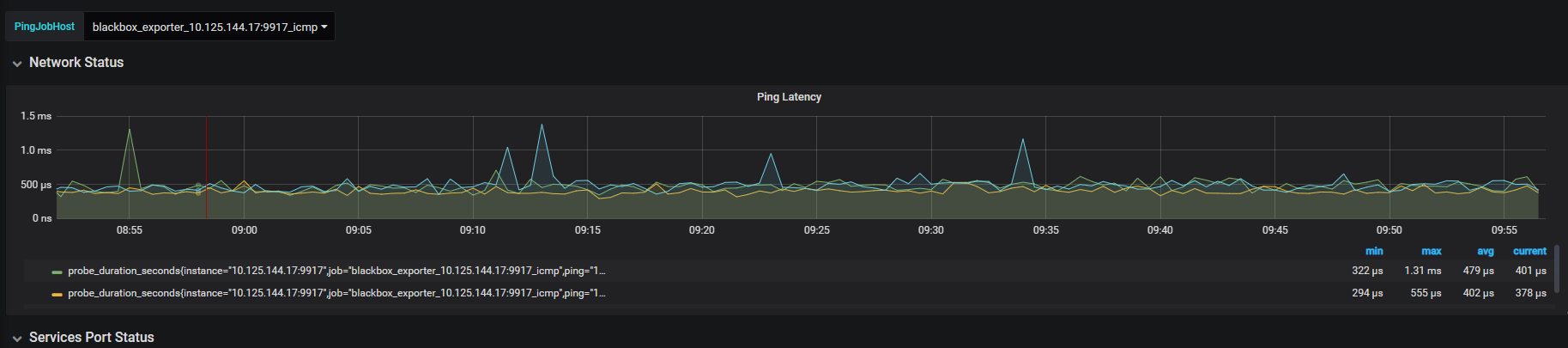
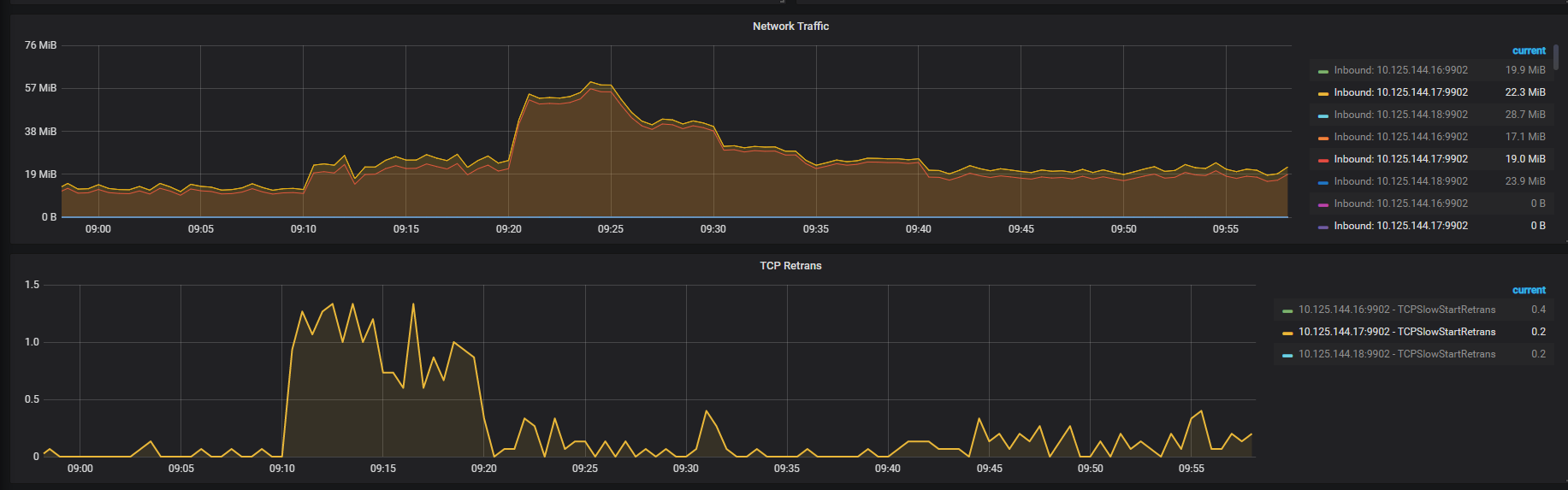
tiup cluster display 中显示的 pd leader 是 144.17 节点,上面网络监控面板是 144.18 ,这个无法反应出问题;另外看下监控面板 overview -> system info -> Network Traffic 和 TCP Retrans 指标在问题时间段的情况。
1.麻烦看下 pd leader 节点对应时间的日志,核实下日志里有无报错或 warning 信息;
2.另外由于集群是 ARM 架构,而且 tidb/pd/tikv 存在混合部署情况,你可以尝试下对这些进程都 NUMA 绑核下,看下压测效果有无改善。
日志被清理了,4个numa_node绑的pd/tidb/tikv,在测试过程中突然出现的pd延时增大的情况
后面压测还有出现这种吗?如果有的话可以提供下日志和监控数据。
没有出现,就这一回
这就不太好继续排查了,案发现场的日志和监控数据不全 ![]()
原来pd data的文件系统是xfs,后来通过扩缩容方式改成ext4,原来的内容都清理了
好吧,下次遇到时麻烦及时提供下日志和监控数据 ![]()
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。