为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
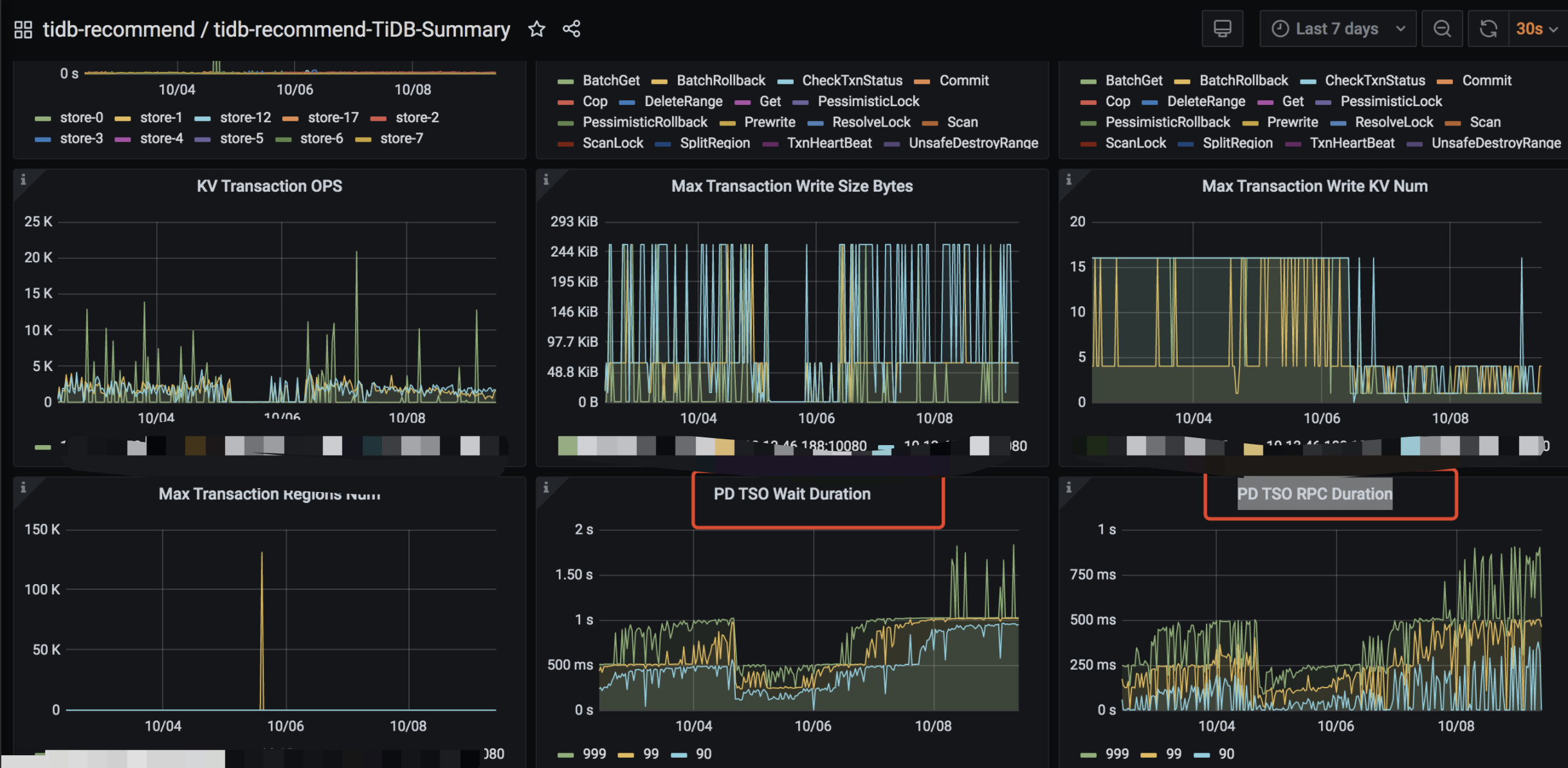
【概述】国庆期间tidb写入明显较慢,耗时增长2倍;查看graff监控,发现duration和PD TSO RPC Duration都增长较多
【背景】
【现象】
【业务影响】写入较慢,已引起调度延迟;急需定位和优化
【TiDB 版本】4.0.3
【附件】
- 相关日志 和 监控
- TiDB- Overview 监控
- 对应模块日志(包含问题前后1小时日志)
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
【概述】国庆期间tidb写入明显较慢,耗时增长2倍;查看graff监控,发现duration和PD TSO RPC Duration都增长较多
【背景】
【现象】
【业务影响】写入较慢,已引起调度延迟;急需定位和优化
【TiDB 版本】4.0.3
【附件】
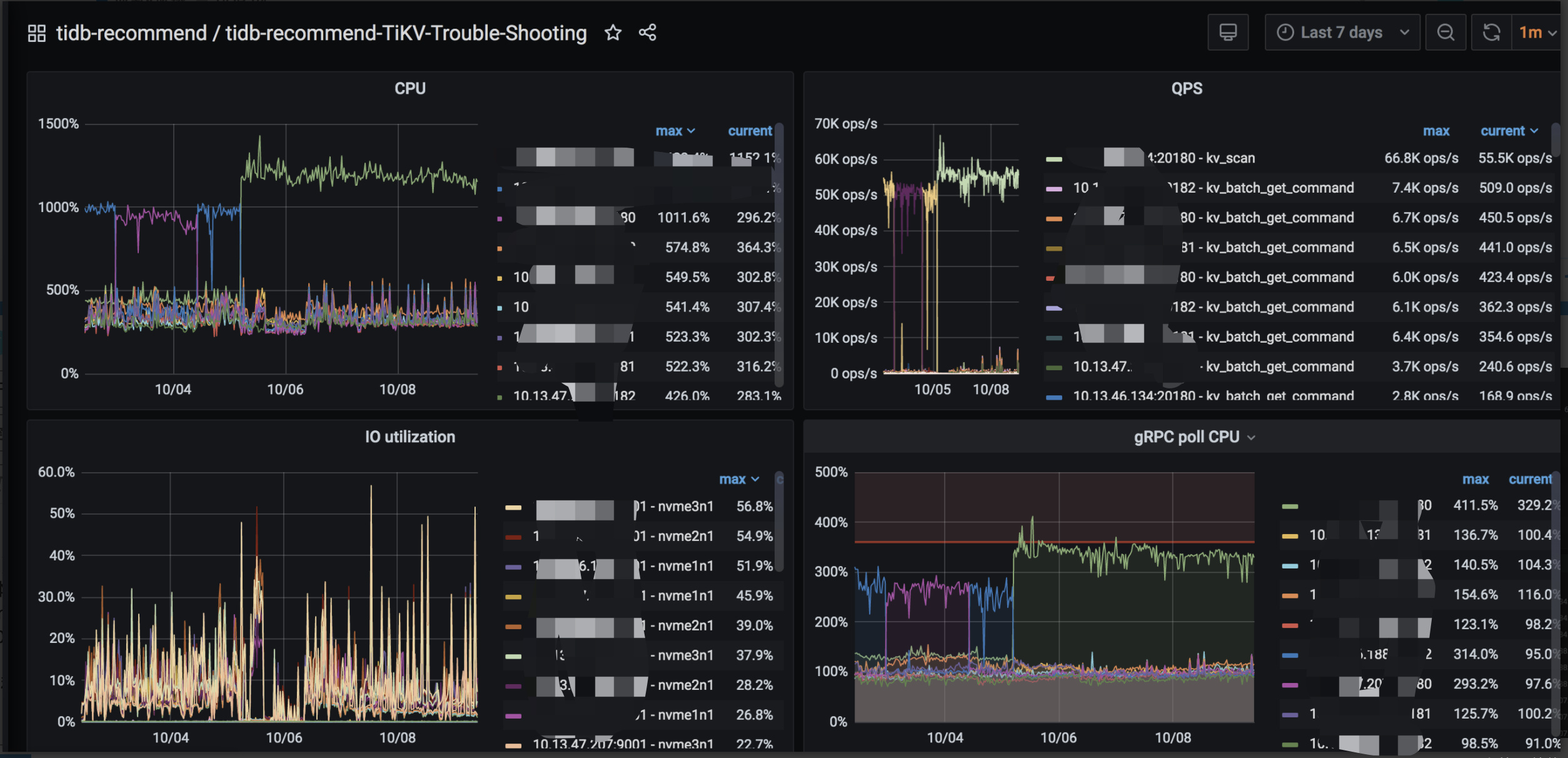
看下pd leader节点的CPU、pd data路径磁盘IO、tidb到pd 的网络延迟
具体是哪几个监控指标呢?
overview node-exporter disk-performance这几个页面可以看
screencapture-grafana-meitu-int-d-eDbRZpnWk11111-tidb-recommend-overview-2021-10-09-11_33_09.pdf (10.6 MB)
比较急,能直接给出要看哪几个监控指标吗?和简短一点的排查思路
这里有一篇相关监控的排查可以参考:
134 这个 tikv 存在明显热点。 存在大量 kv scan 排查下 大的慢查询
全部都是按主键update, 没有找到其他慢查呢!这个还有其他原因吗 ?
首先从你的监控看
2 个问题
特别注意 服务混部情况。是否存在 pd tidb tikv 混部情况
问题1,确定方向应该是tidb有一台压力比较大;所有sql都会通过host206执行,即使最开始连接到了host206和host134;
问题2,包括 dashboard 和 information 重点 hot region 视图来关联排查;这块有详细的排查步骤吗?dashbord是指【流量可视化】吗?
dashboard 是流量可视化
infromation 参考tidb 官方文档 相关视图 含义。自行编写 SQL 可以分析现场情况
或在官网搜索 热点问题 FAQ
还有一个问题,tidb连接数是均匀的,但是sql全部都是集中在了一台机器;
这个能帮忙解释下是啥原因吗?如何均衡sql
看起来是业务测或 LB 的问题
建议看下 LB 的 分发规则
TiDB 是无状态的 serving 没有流量调度功能
可能您还没有明白我意思,LB和业务侧已经均衡了tidb的连接数,但是SQL还是不均衡的,甚至有一台几乎没有执行SQL
首先 tidb 是无状态服务 并不存在 流量调度的功能,既然你肯定 LB 已分发了上游应用的 connection
可以通过以下几个方法来排除问题
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。