【 TiDB 版本】
3.0.11
【概述】 场景 + 问题概述
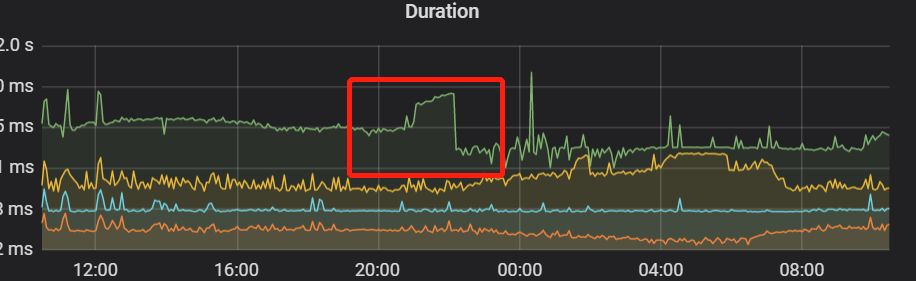
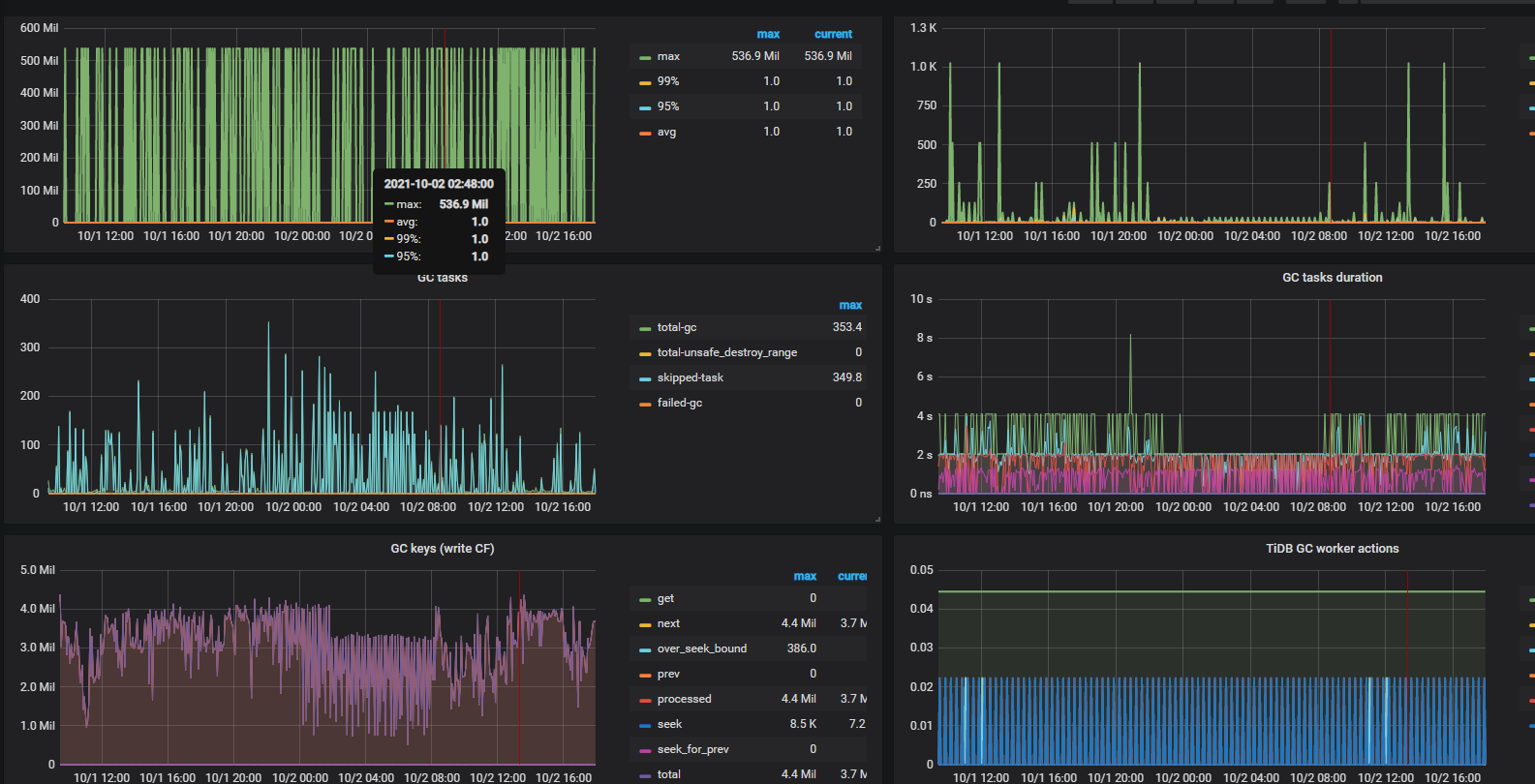
在晚上9点到10点监控发现sql延迟变高,但是qps并没有上升,业务量也没有很大的变化,排查发现rockdb一个指标有点异常
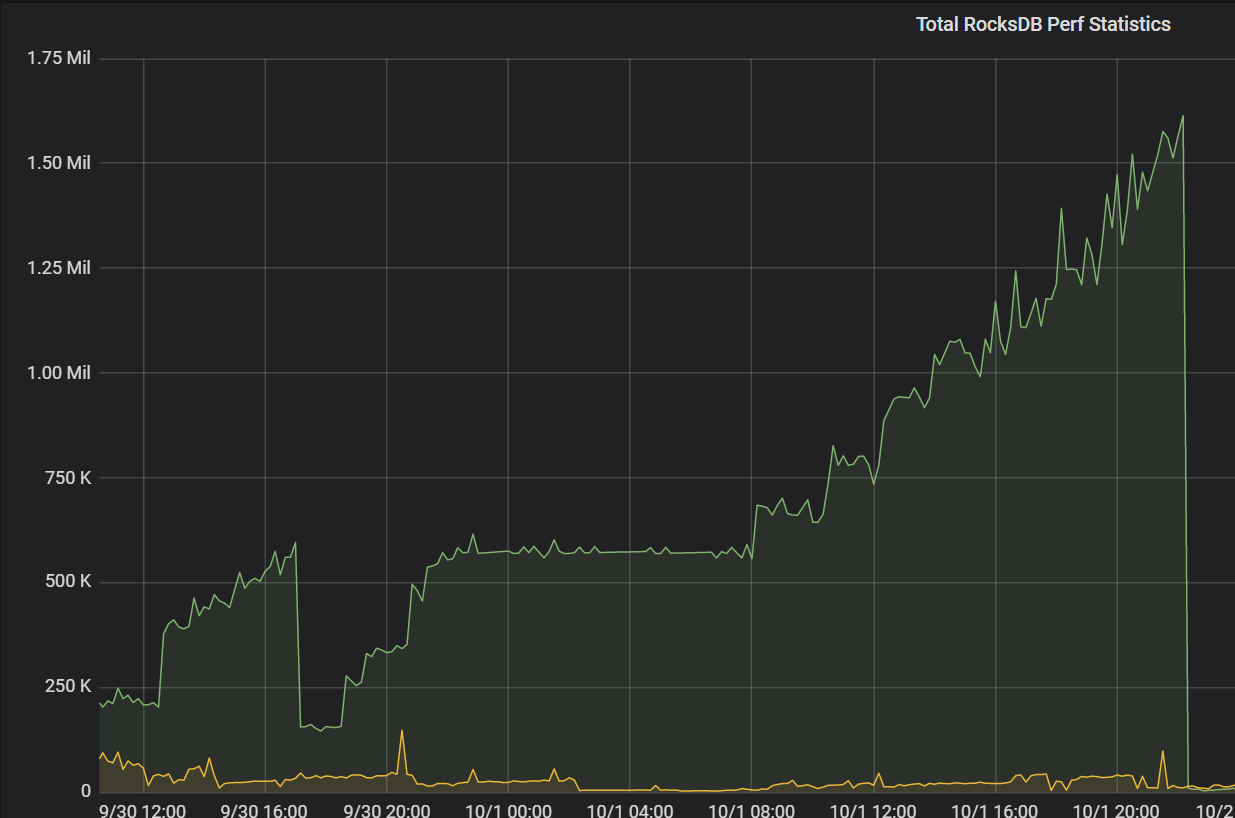
这个值每次都是很高才删除,导致其中一个kv节点读的延迟也变高了,然后sql延迟变高
【 TiDB 版本】
3.0.11
【概述】 场景 + 问题概述
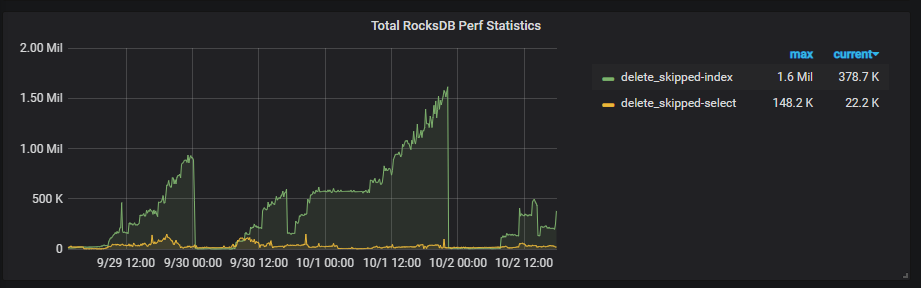
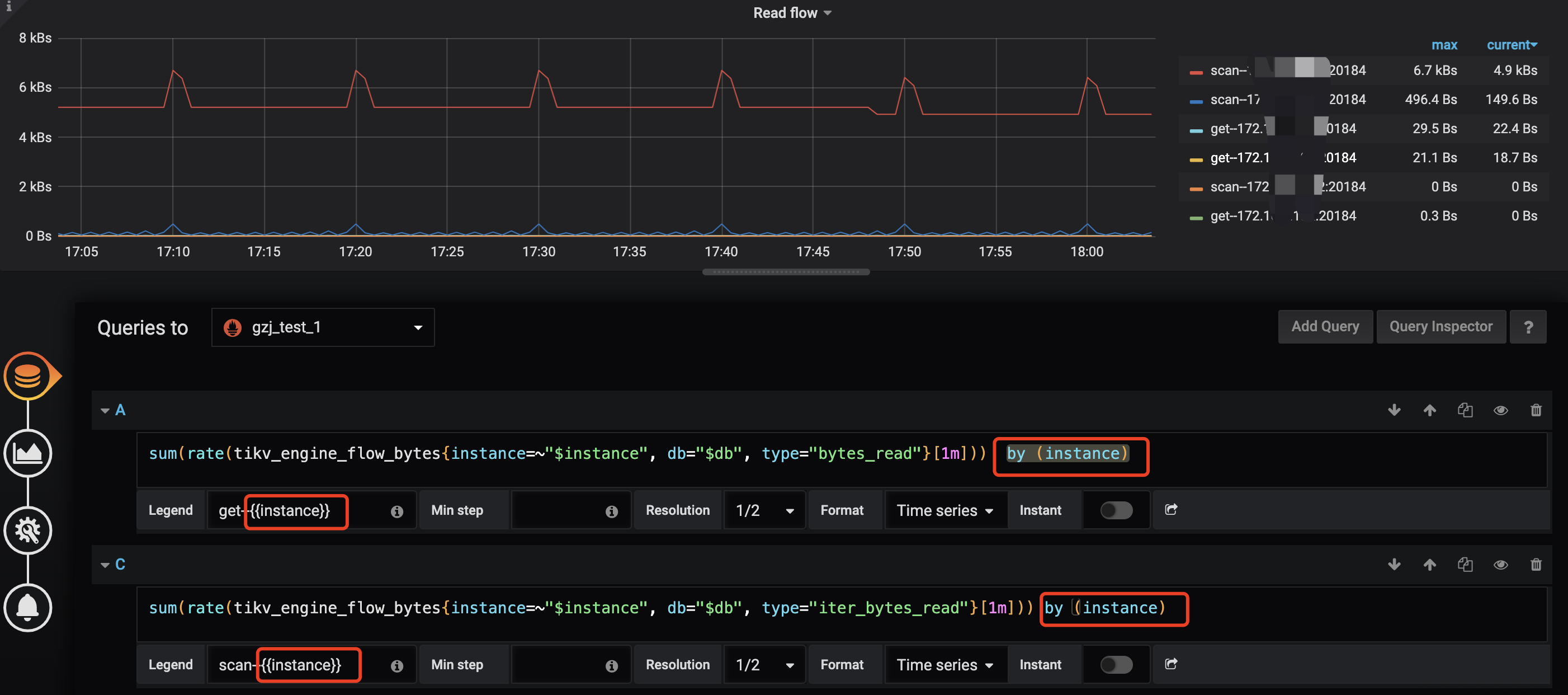
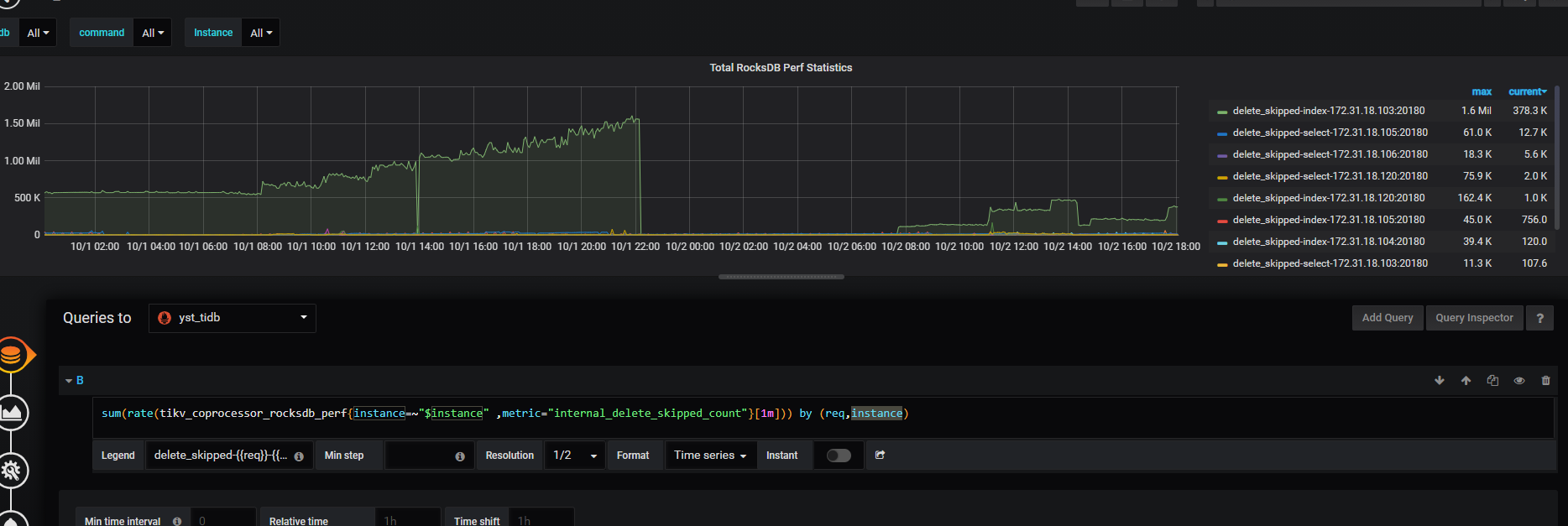
Coprocessor Overview —> Total RocksDB Perf Statistics 表示 RocksDB 的性能统计数据,包括扫描的 key 的 mvcc 版本,以及 tombstone key 的数量。除此之外, 还有下面两个相关的监控项:
key 的 mvcc 版本在 GC 的 Do GC 这一步即删除所有 key 的过期版本。但是这个 key 仅会被标记为删除,在 compaction 后,才会真正的被删除掉。
所以出现上面的问题,可以检查下 GC 或者 compaction 相关的监控,比如是否在 20 点前后进行了 compaction 操作,操作后,tidb duration 下降了。
在 『读性能慢』的文档中也有提到类似的问题,见下述文档:
compaction 相关的监控,可以在 TiKV-Details → RocksDB KV 里面找到,参照官方文档:
https://docs.pingcap.com/zh/tidb/v3.0/grafana-tikv-dashboard#rocksdb---kv
不是看这个时间段 compaction 是否有异常现象,而是看下 compaction 和 tidb duration 的相关性,比如是否是在 compaction 结束,key tombstone 数量减少后,tidb duration 恢复正常 。GC 同理 ~
另外,建议看监控的时候把时间范围缩小,比如 29 号 00 ~ 30 号 01:00,这样比较容易看到相关趋势 ~
检查过了 没有相关性 ,高低无常
排查后,确认米有相关性,但是 tidb duration 周期性升高,可以参照下 『读慢排查文档』,比如 tidb slowlog 查看各阶段的时间消耗,以及是否慢在 TiDB 或 TiKV 侧 :
如果仍然没有定位或者新的发现,那么可以提供下,29 号 9 ~ 10 点间,duration 升高期间的:
Grafana 监控导出方式参考:[FAQ] Grafana Metrics 页面的导出和导入
Yst_tidb-TiKV-Details_2021-10-08T08_20_39.997Z.rar (2.6 MB)
我把监控导出来了,麻烦帮我看看 谢谢
tidb_2021-10-08T08_29_57.495Z.rar (789.9 KB)
慢SQL没有了,已经被自动清空了 时间段是 10-01 21:00到22:21
因为 slowlog 已经么有了,所以只能基于当前的监控信息进行猜测,对于定位问题的准确性有一定的影响。
另外,TiDB 的 Grafana 监控面板是下面的这个,不是 Overview 面板:
TiDB Grafana 监控导出与 TiKV-Details 一样的时间段:
Yst_tidb-TiDB_2021-10-08T09_03_49.838Z.rar (579.5 KB)
我自己也检查过那天的慢SQL ,没有什么特别的SQL
没注意到,因为慢SQL阈值是300ms,有很多,知识观察有没有时间长或者不常见的SQL去了
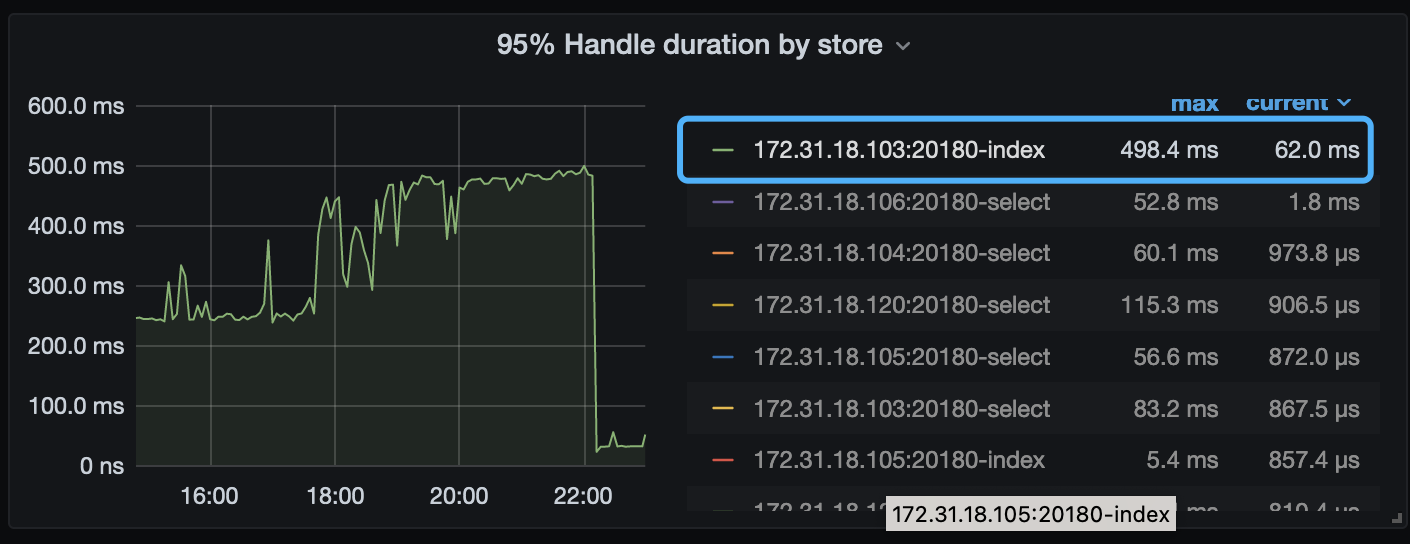
tidb 的监控显示,从 1 号的 18 点后,开始 store-1 的 duration 逐渐升高,并且到 22 点左右下降,于此同时 coprocessor 类型的请求 duration 也逐渐升高,且趋势较为吻合:
tikv-details 的 coprocessor 的相关监控,再次佐证了这个推测:
基于上述现象,建议你那里看下这个时间段的相关信息:
看下 store1 的 TiKV-Details 在相同时间段和其他 store 的差异
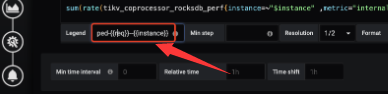
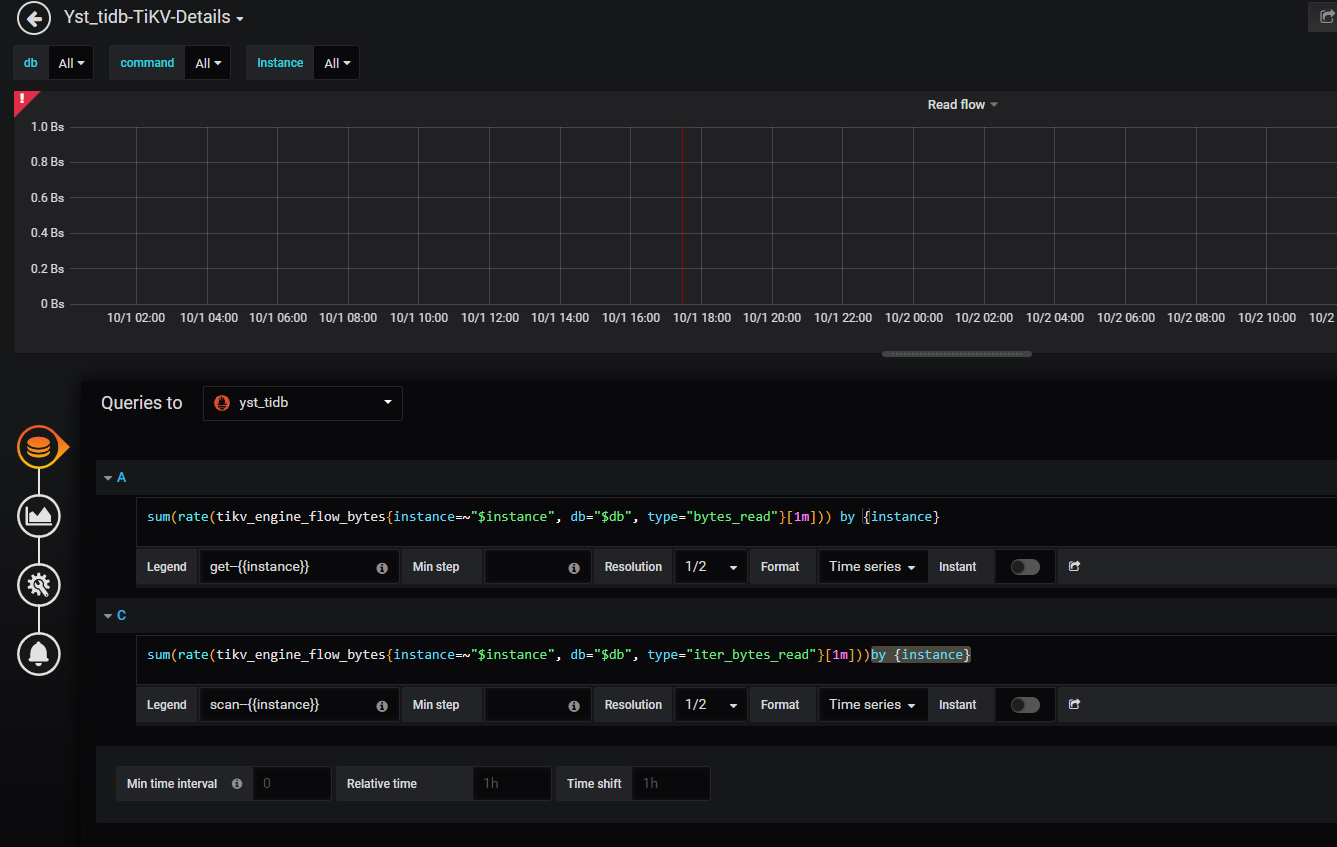
看下 tikv-details 的 Total RocksDB Perf Statistics 每个 store 的情况是否有非常大的差异,需要修改公式参考:
看下 tikv-details → RocksDB kv 下的 read flow by store instance 的情况是否有非常大的差异,需要修改公式参考:
另外,当前版本为 v3.0.11,非常低,建议在测试环境充分测试后,升级集群版本,4.0 版本有了 tidb dashboard ,对 slowlog 的查看,集群各个组件日志的检索非常便捷,升级相关的帖子参考:
能给一下这个吗,看不清