【 TiDB 使用环境】
CentOS-7 官方最低推荐集群部署配置(3PD+3TIDB+3KV+MONITOR)
【TiDB 版本】
Release Version: v4.0.0
Edition: Community
Git Commit Hash: 689a6b6439ae7835947fcaccf329a3fc303986cb
Git Branch: heads/refs/tags/v4.0.0
UTC Build Time: 2020-05-28 01:37:40
GoVersion: go1.13
Race Enabled: false
TiKV Min Version: v3.0.0-60965b006877ca7234adaced7890d7b029ed1306
Check Table Before Drop: false
【概述】 场景 + 问题概述
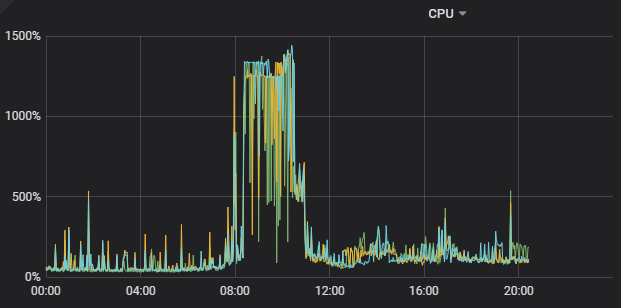
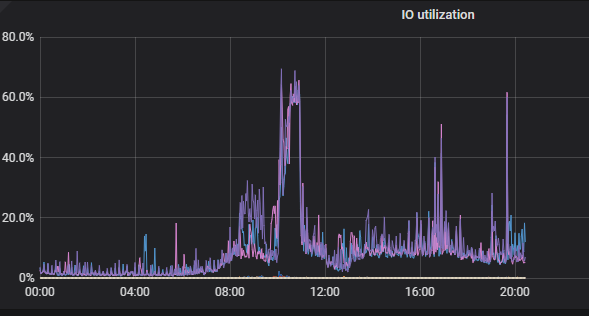
业务上线稳定5个月后,非高峰期情况下,今天8-10点出现2个小时TiKV 3个节点CPU负载及IO负载比较高,8000W数据量,索引查询耗时非常多。
【背景】 做过哪些操作
近期无版本更新,无业务量新增
【现象】 业务和数据库现象
慢查询日志:
# Time: 2021-09-27T08:32:24.860844308+08:00
# Txn_start_ts: 428003196946350106
# User: user
# Conn_ID: 779979
# Query_time: 119.749504109
# Parse_time: 0.000125808
# Compile_time: 0.000537373
# Cop_time: 239.571195613 Process_time: 2.221 Wait_time: 2.6870000000000003 Backoff_time: 0.29 Request_count: 171 Total_keys: 151764 Process_keys: 151024
# DB: table
# Index_names: [table:yyy]
# Is_internal: false
# Digest: 6d97f0b0b5bf53a05ea3361cfab4a8c79fbca3c7a05a1cb0d82dfae16dc8d299
# Stats: table:428003035059322910
# Num_cop_tasks: 171
# Cop_proc_avg: 0.012988304 Cop_proc_p90: 0.017 Cop_proc_max: 0.138 Cop_proc_addr: 10.74.198.27:20160
# Cop_wait_avg: 0.01571345 Cop_wait_p90: 0.028 Cop_wait_max: 0.062 Cop_wait_addr: 10.74.198.29:20160
# Cop_backoff_regionMiss_total_times: 144 Cop_backoff_regionMiss_total_time: 0.288 Cop_backoff_regionMiss_max_time: 0.002 Cop_backoff_regionMiss_max_addr: kv_ip:20160 Cop_backoff_regionMiss_avg_time: 0.002 Cop_backoff_regionMiss_p90_time: 0.002
# Cop_backoff_updateLeader_total_times: 1 Cop_backoff_updateLeader_total_time: 0.002 Cop_backoff_updateLeader_max_time: 0.002 Cop_backoff_updateLeader_max_addr: kv_ip:20160 Cop_backoff_updateLeader_avg_time: 0.002 Cop_backoff_updateLeader_p90_time: 0.002
# Mem_max: 2192076
# Prepared: false
# Plan_from_cache: false
# Has_more_results: false
# Succ: true
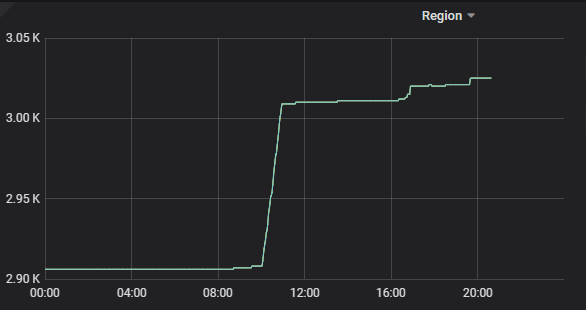
PD监控

KV 监控:

KV日志
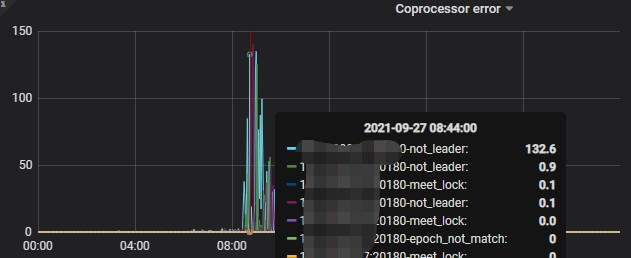
出现大量Region Error告警信息:
[WARN] [endpoint.rs:527] [error-response] [err="Region error (will back off and retry) message: "peer is not leader for region 8077, leader may Some(id: 8080 store_id: 5)\


TIDB监控



【业务影响】
业务端查询请求大多数阻塞超时。
请大佬们帮忙看看是什么原因导致,有什么解决方案,感谢~








