为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。
- 【TiDB 版本】:3.0.11
- 【问题描述】:
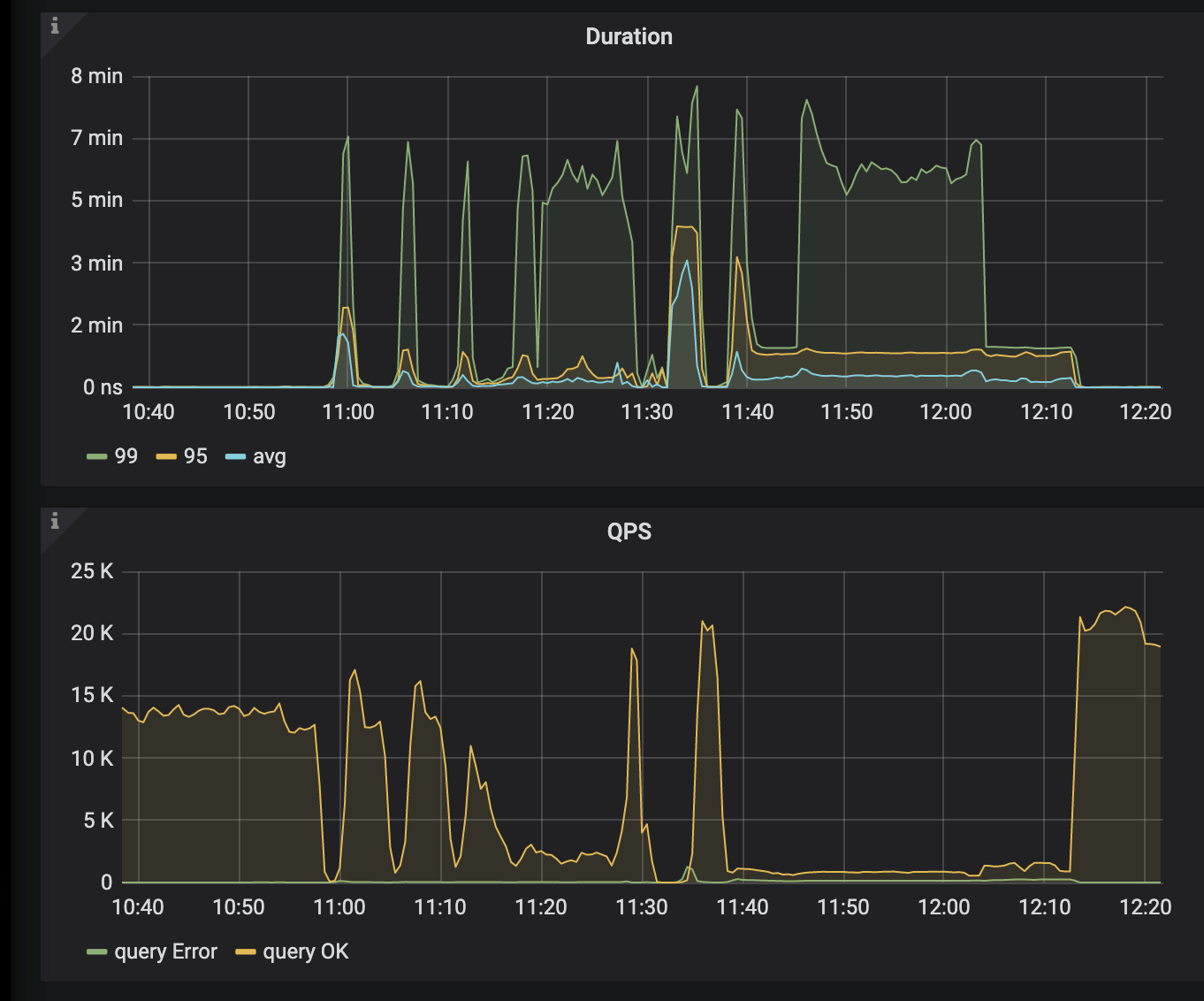
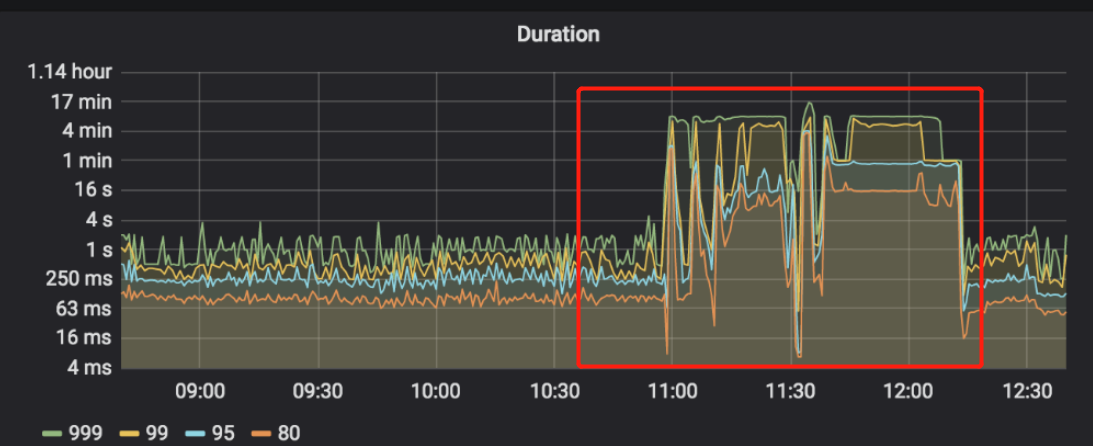
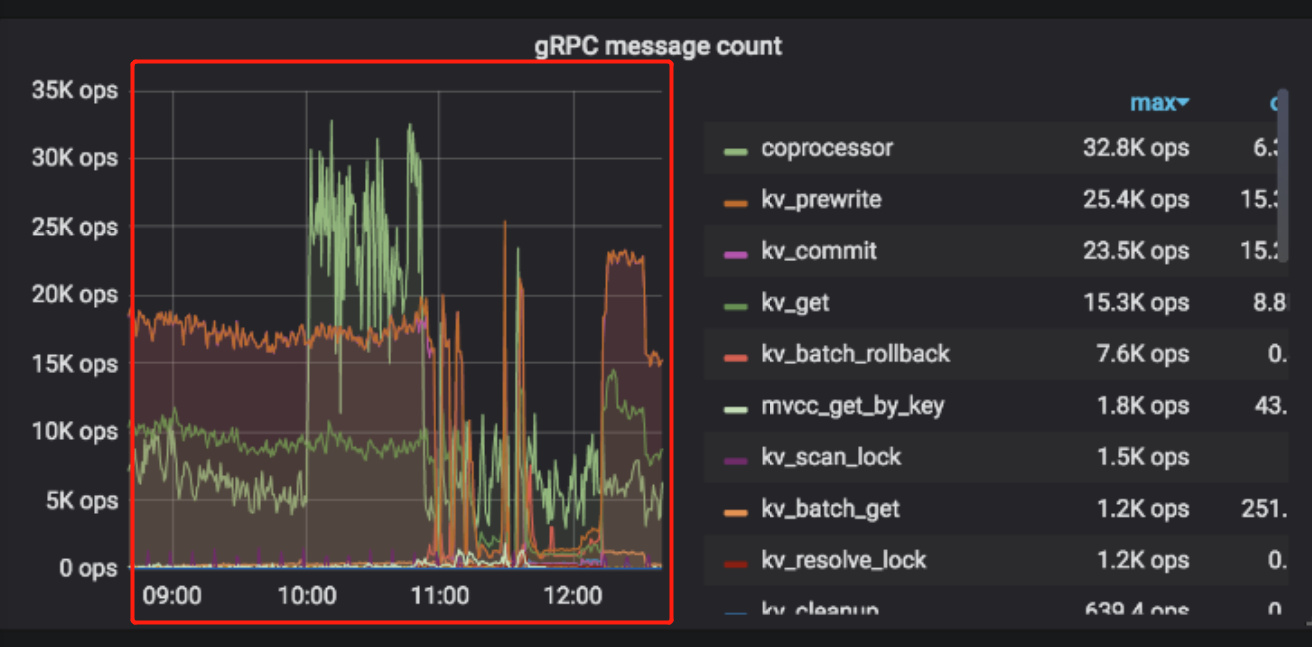
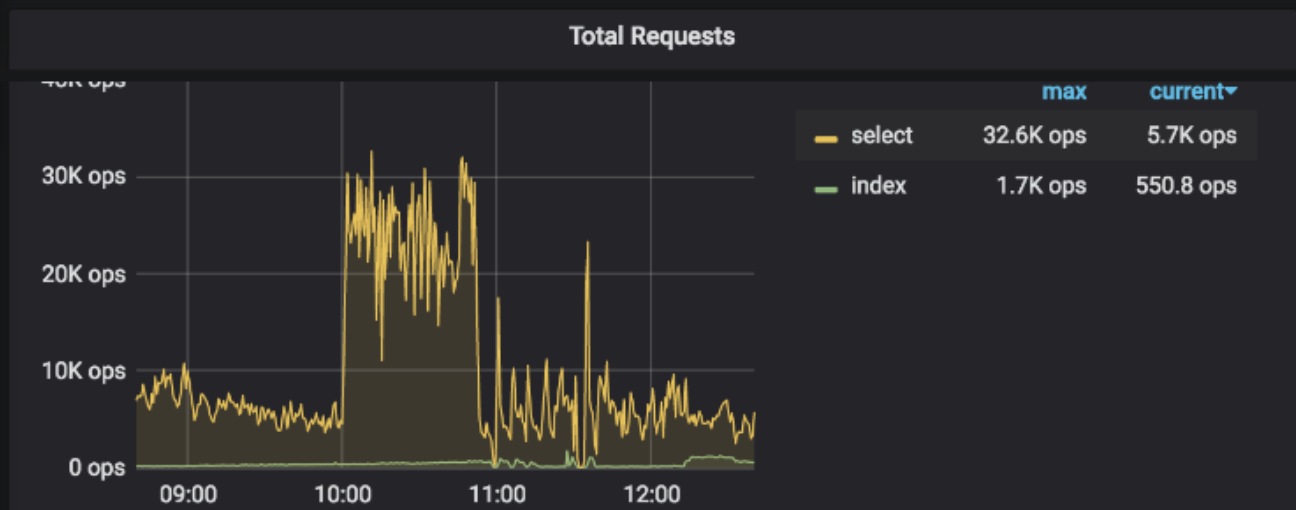
tidb整体耗时突然增大,读写处理都非常缓慢,集群基本瘫痪。
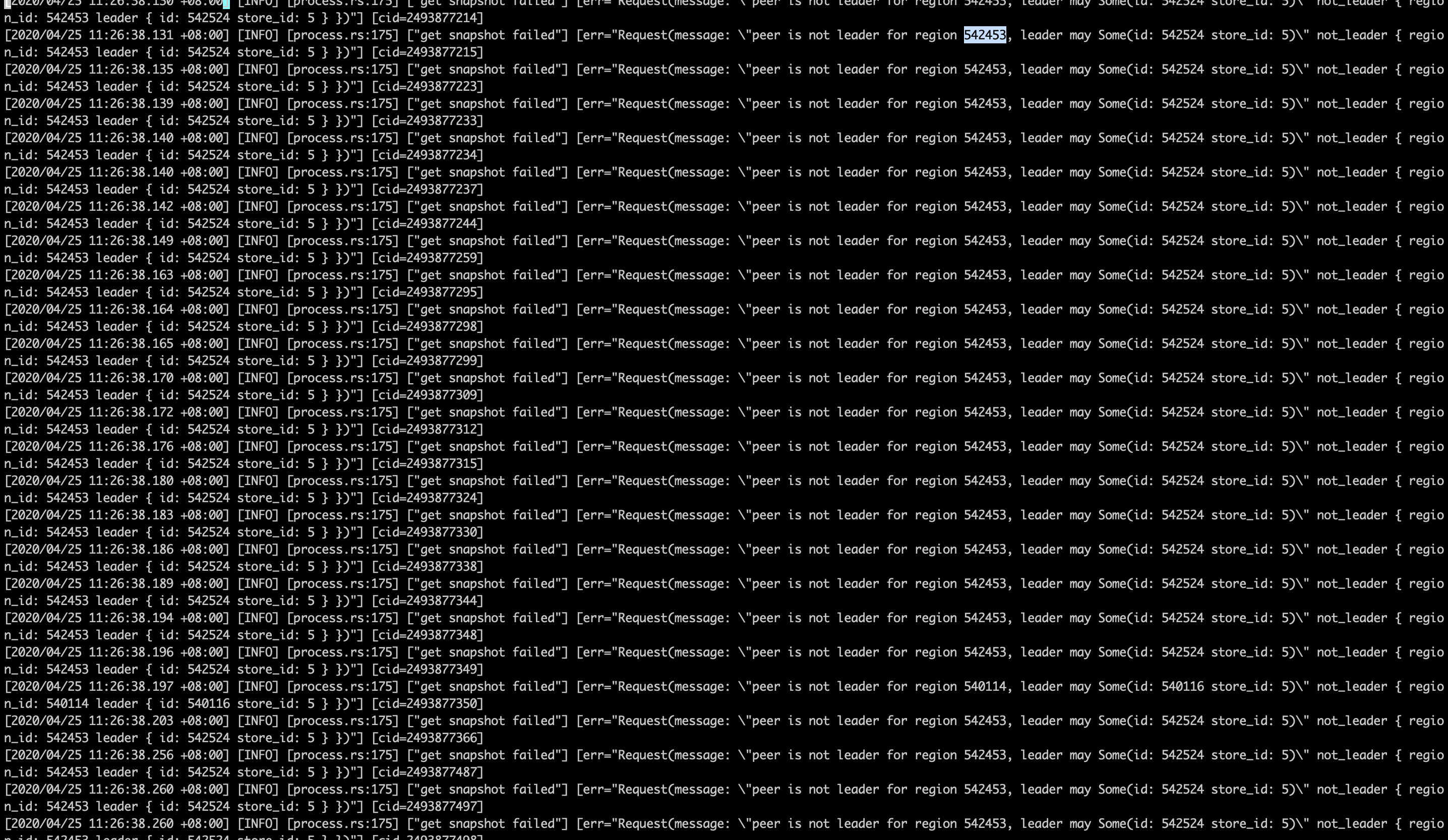
从dashboard中可以看到tikv某个分片出现region missing的问题,
从tikv的日志中可以看到"peer is not leader for region xxx"的报错"
执行了tikv、tidb、pd的所有节点重启,重启后没有恢复,异常tikv节点继续报错"peer is not leader for region xxx",持续一段时间后开始报错为"KvService response batch commands fail",这段时间tidb始终不可用。
最后第二次重启tikv后集群恢复
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
yilong
(yi888long)
2
- 请在tikv服务器上查看dmesg,在问题发生时是否有异常
- 请grep Welcome tikv.log 看看问题出现时,tikv是否有重启
- 如果有重启,请帮忙反馈tikv.log日志
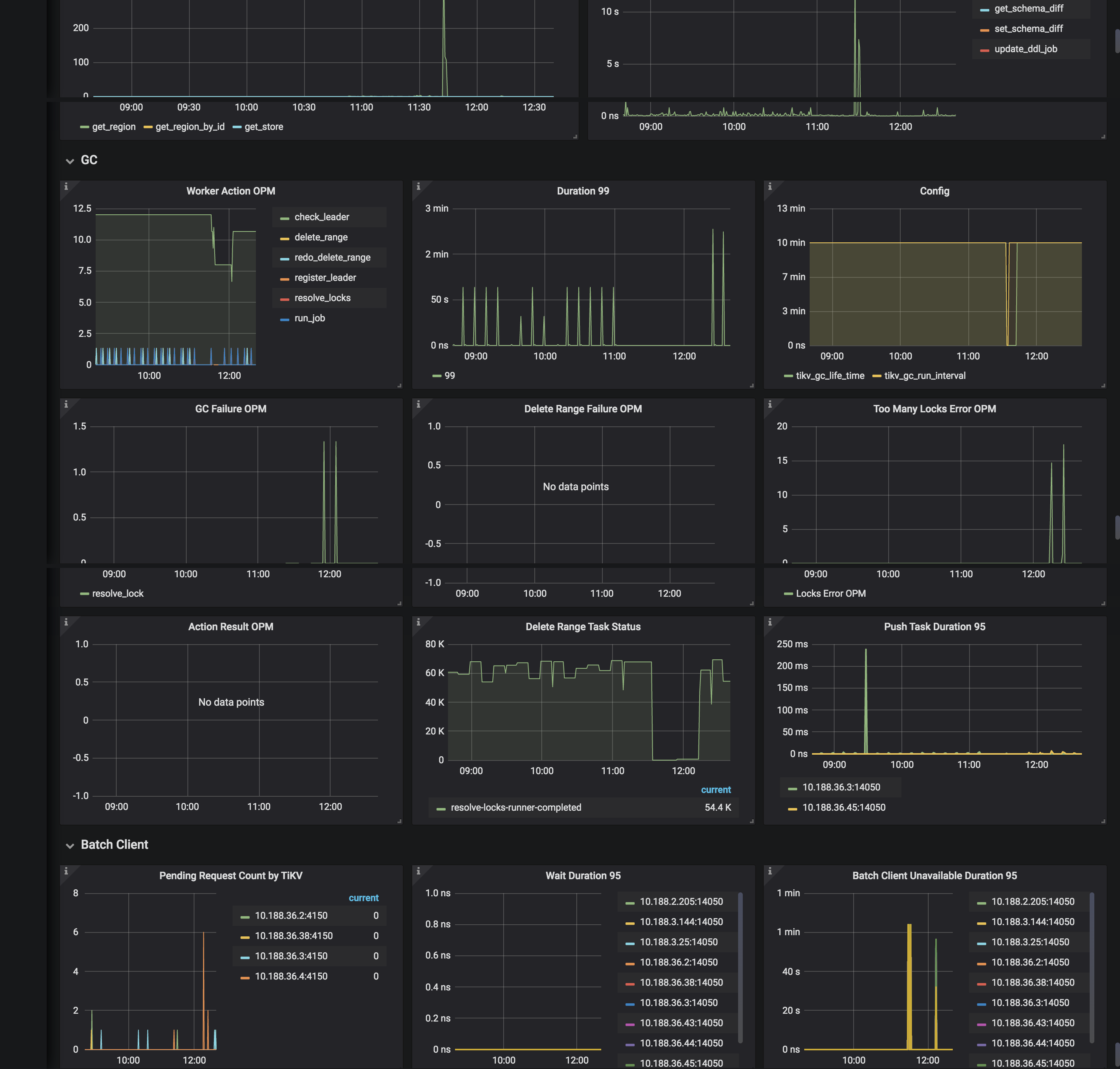
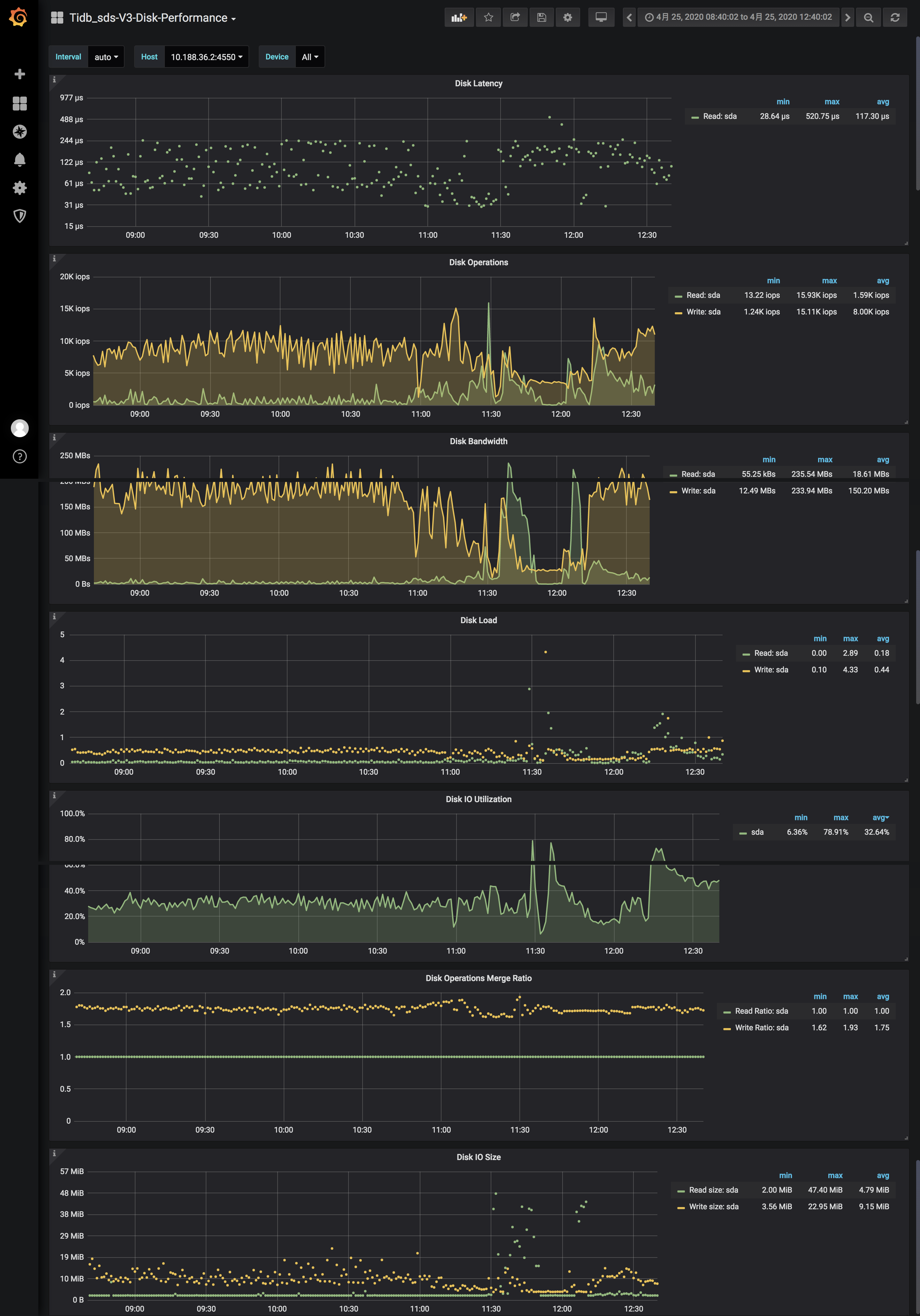
- 请采集overview tidb detail-tikv disk-performance 问题发生时的监控
(1)、chrome 安装这个插件https://chrome.google.com/webstore/detail/full-page-screen-capture/fdpohaocaechififmbbbbbknoalclacl
(2)、鼠标焦点置于 Dashboard 上,按 ?可显示所有快捷键,先按 d 再按 E 可将所有 Rows 的 Panels 打开,需等待一段时间待页面加载完成。
(3)、使用这个 full-page-screen-capture 插件进行截屏保存
感谢回复
1、dmesg中没有最近10天的异常记录
2、查看tikv重启 和人为操作时间点还一致,没发现自动重启
4、overview:
tidb:
tikv details:
disk: