xuanzjie
2021 年9 月 27 日 08:54
1
【 TiDB 使用环境】
架构:
【概述】
【现象】
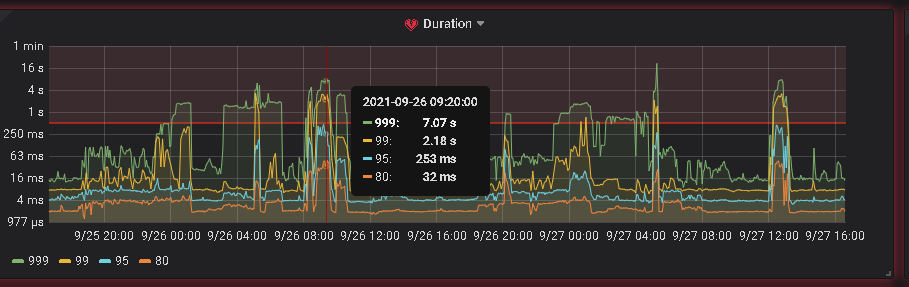
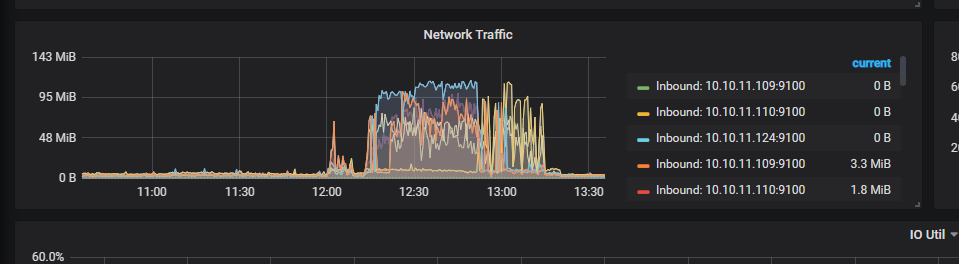
排查发现,宽带莫名其妙打满,但并不确定是这个功能的影响,为此,我们27号将数据接收放到了12点 。
第二天的八点,数据库一切正常,到了12点,再次出现了26号8点出现的问题,带宽打满,并且读写性能严重下降。
但非常奇怪的是,影响的数据只是每秒五六千的数据插入,并且两天8点的qps对比来看,并没什么太大起伏 ,不太理解为什么带宽被打满了,所以问题排查遇到了一些瓶颈。
【问题与目的】
【TiDB 版本】
日志:logs (1).zip (4.7 MB)
1 个赞
部署架构发一下,还有问题点的日志,tidb,tikv,慢日志等
1 个赞
xuanzjie
2021 年9 月 27 日 10:15
3
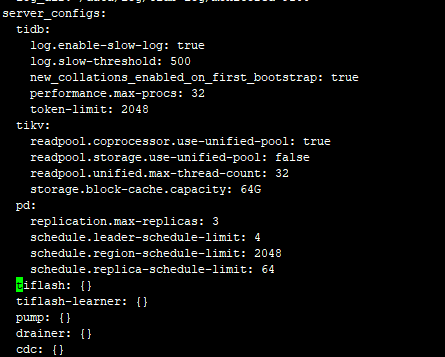
好的,已在问题补充日志,目前只有三台机器,pd,kv等都在同三台机器上,数量都是3
1 个赞
xuanzjie
2021 年9 月 28 日 07:28
6
xuanzjie:
4.0.12
没有发现什么很明显的痕迹,AutoID 的QPS和duration上升的很快,不知道是否有关?
1 个赞
xuanzjie
2021 年9 月 28 日 08:50
7
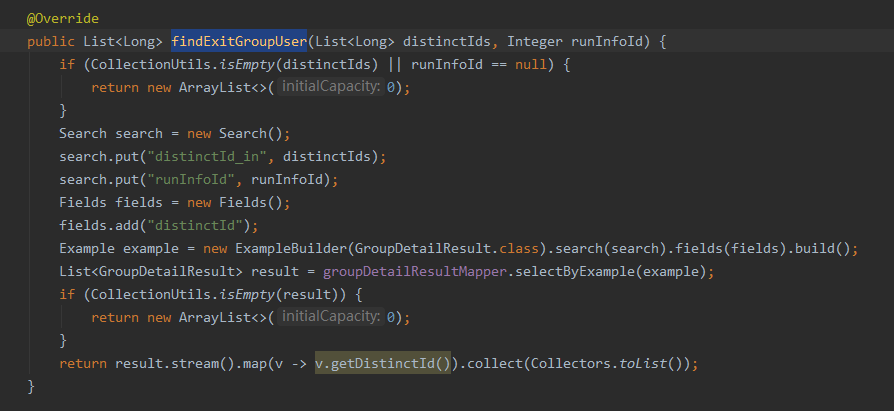
问题解决了,我们有一段幂等校验逻辑,如下图,表数据约五千万
把这段逻辑注释掉后即没有出现任何问题。
现在的问题是,为什么这段平平无奇的代码会导致问题出现:sweat_smile:
1 个赞
xuanzjie
2021 年9 月 28 日 10:31
9
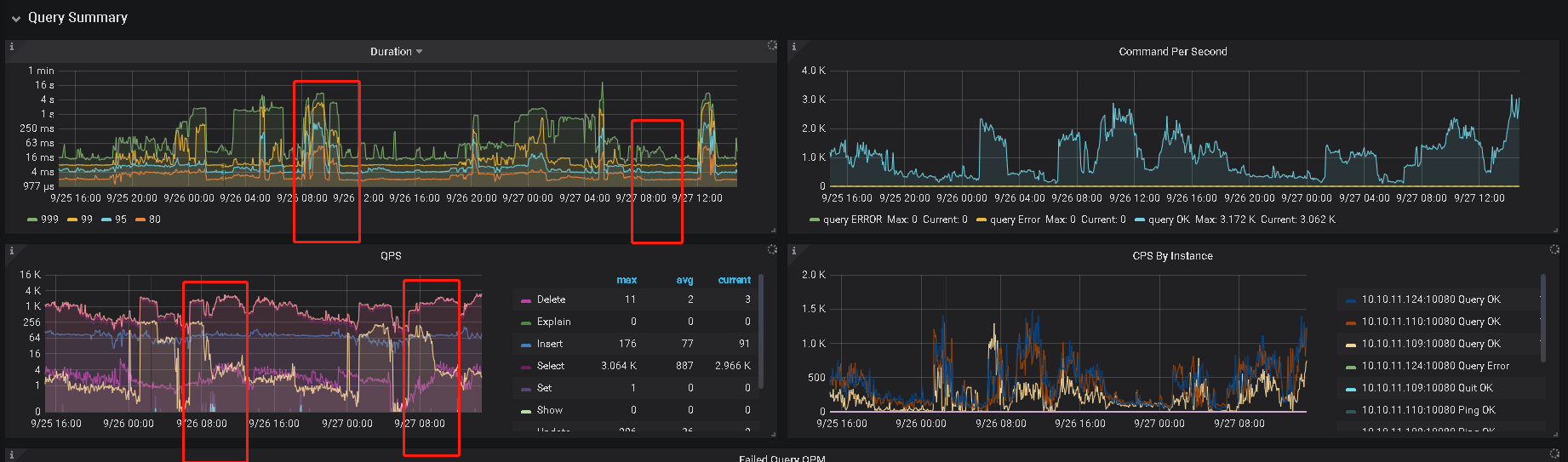
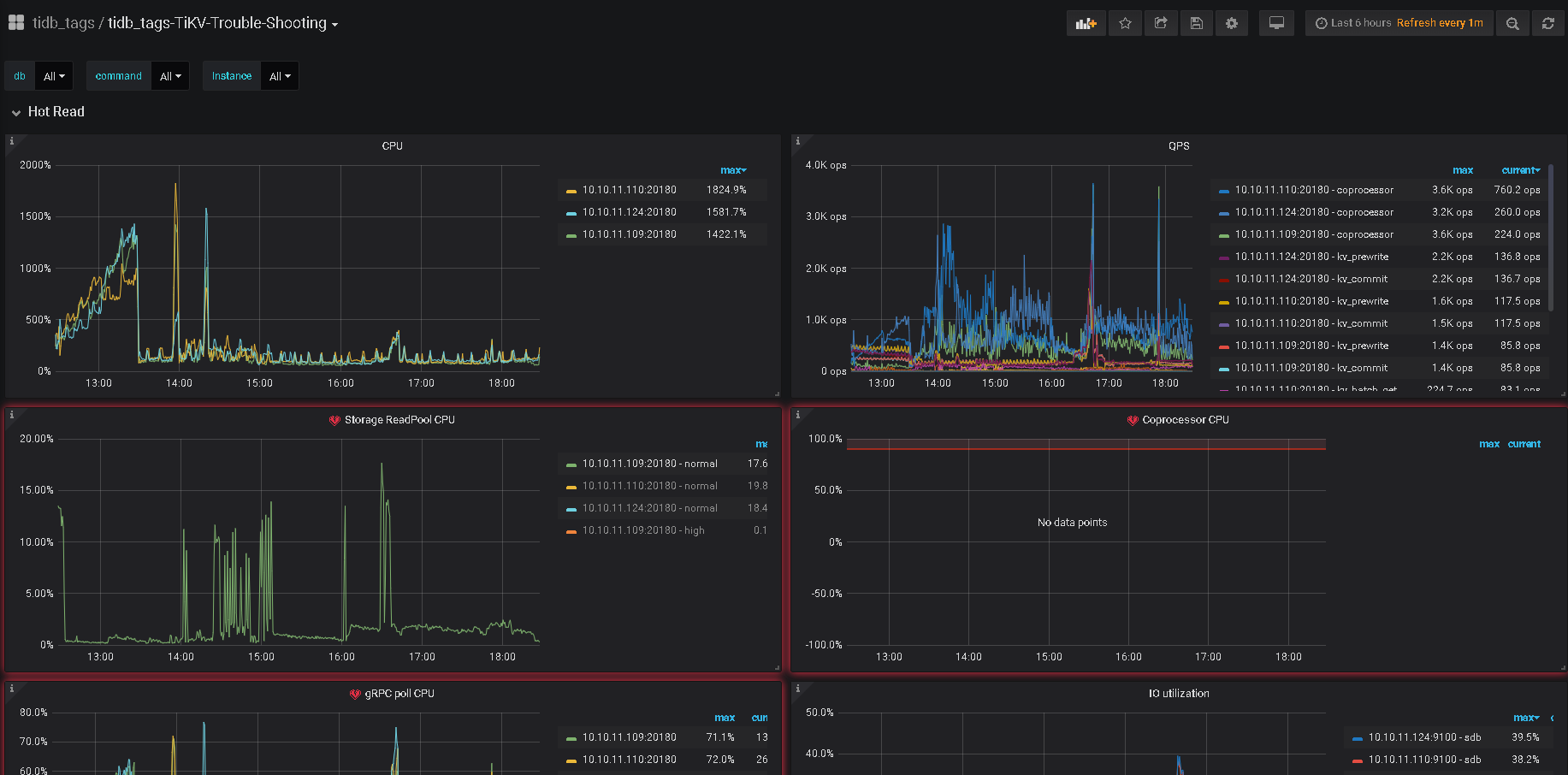
我们也猜测是热点数据导致,所以定位到了那段代码。实际上,按照@ sultan8252 提供的文档,总的来说并没有哪一台节点非常明显高于其他节点(但其实在不同时间还是会有一台比另外一台高百分之五百)。但相似的是,unified read pool cpu都有很高的拔升,如图,分别在三个时间段尝试执行时发生比较高的拔升:
在TiKV-Trouble-Shooting,cpu的占用中有存在一台占用比另外一台多百分之五百这样的情况
1 个赞
xuanzjie
2021 年9 月 29 日 06:59
11
看了官网的热点解释,我不是很明白,有什么推荐阅读的资料吗?
1 个赞
sultan8252
2021 年9 月 30 日 01:58
12
看你代码应该是个 distinct 语句
从 statment summary history 找下对应语句 看下 有关 kv total key 的数量是不是在同时间段内占比最高。
或者控制全量比对的 并发度
xuanzjie
2021 年9 月 30 日 03:48
13
感谢,具体的sql并不是distinct语句,具体是类似
用于做一个插入前校验
但大量kv返回给tidb应该是一个非常棒的思路,我后面看一下
system
2022 年10 月 31 日 19:22
14
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。