为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
服务器硬件:
10.160.60.18 Cpu 40核,256G内存,机械硬盘
10.160.60.19 Cpu 40核,256G内存,机械硬盘
10.160.60.20 Cpu 40核,256G内存,机械硬盘
【概述】 场景 + 问题概述
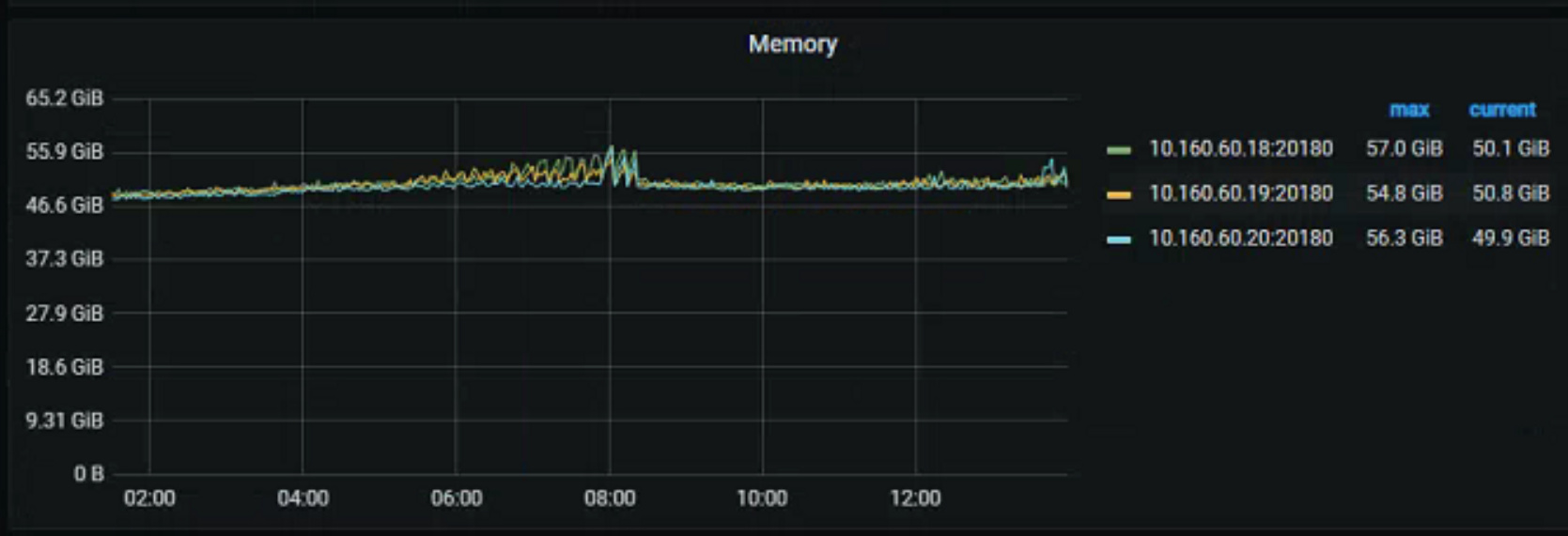
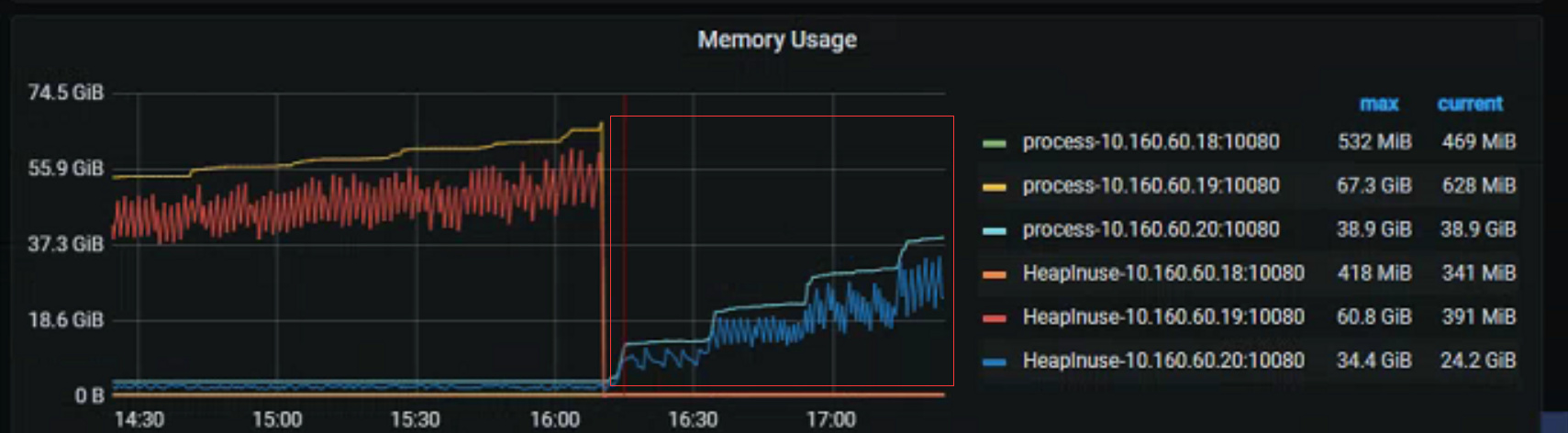
TIDB和TIKV,内存一直不断增长,其中TIDB特别严重,每次达到resource_control【memory_limit】阀值后,触发重启,每天至少重启1-2次,有无配置参数可以快速及时释放TIDB、TIKV占用内存
- TIDB内存情况(一直增长到96G阀值,然后自动重启,重启后内存一直增长)
- TIKV内存情况(一直占用50G,不释放)
全局配置如下:
global:
user: jhdcp
ssh_port: 22
ssh_type: builtin
deploy_dir: /jhmk/tidb/tidb-deploy
data_dir: /jhmk/tidb/tidb-data
resource_control:
memory_limit: 96G
os: linux
arch: amd64
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
deploy_dir: /jhmk/tidb/tidb-deploy/monitor-9100
data_dir: /jhmk/tidb/tidb-data/monitor-9100
log_dir: /jhmk/tidb/tidb-deploy/monitor-9100/log
server_configs:
tidb:
performance.txn-entry-size-limit: 125829120
performance.txn-total-size-limit: 10737418240
tmp-storage-path: /jhmk/tidb/tidb-tmp
tikv:
raftstore.raft-entry-max-size: 125829120
server.max-grpc-send-msg-len: 125829120
pd:
replication.enable-placement-rules: true
tiflash: {}
tiflash-learner: {}
pump: {}
drainer: {}
cdc: {}
【业务影响】
数据库非常不稳定,每天重启几次,导致长期数据作业中断,中断又要重来,重来又中断,根本没有办法用
【TiDB 版本】
TIDB 5.2.1
1 个赞
spc_monkey
(carry@pingcap.com)
2
spc_monkey
(carry@pingcap.com)
3
最近1小时,没有业务操作的情况下,20这台服务器内存一直到30多G,无解
1 个赞
这边是通过HAproxy访问的,不知道为什么三台服务器总有一台会飙高的很快
这边参数都是用默认的,主要问题是要内存不停增长,而且不释放,导致重启,即使在没有业务的情况下
看下connection count3个tidb是否均衡
THP这个是什么,怎么关THP,这边参数基本上是默认的
connection count三个节点目前有点不均衡
这里面的检查项都做一下 检查和配置操作系统优化参数
可以使用tiup cluster check命令检查下系统环境是否到最优状态
haproxy 基本上按照官网的,之前频繁断开,改了点延时参数
global # 全局配置
log 127.0.0.1 local0 # 定义全局的 syslog 服务器,最多可以定义两个
#chroot /var/lib/haproxy # 将当前目录为指定目录,设置超级用户权限启动进程,提高安全性
#pidfile /var/run/haproxy.pid # 将 HAProxy 进程写入 PID 文件
maxconn 4000 # 设置每个 HAProxy 进程锁接受的最大并发连接数
user haproxy # 同 uid 参数,使用是用户名
group haproxy # 同 gid 参数,建议专用用户组
nbproc 40 # 启动多个进程来转发请求,需要调整到足够大的值来保证 HAProxy 本身不会成为瓶颈
#daemon # 让 HAProxy 以守护进程的方式工作于后台,等同于“-D”选项的功能。当然,也可以在命令行中用“-db”选项将其禁用。
#stats socket /var/lib/haproxy/stats # 定义统计信息保存位置
defaults # 默认配置
log global # 日志继承全局配置段的设置
retries 3 # 向上游服务器尝试连接的最大次数,超过此值就认为后端服务器不可用
timeout connect 30000s # HAProxy 与后端服务器连接超时时间,如果在同一个局域网内可设置成较短的时间
timeout client 30000s # 定义客户端与 HAProxy 连接后,数据传输完毕,不再有数据传输,即非活动连接的超时时间
timeout server 30000s # 定义 HAProxy 与上游服务器非活动连接的超时时间
listen admin_stats # frontend 和 backend 的组合体,监控组的名称,按需自定义名称
bind 0.0.0.0:8080 # 配置监听端口
mode http # 配置监控运行的模式,此处为 `http` 模式
option httplog # 表示开始启用记录 HTTP 请求的日志功能
maxconn 10 # 最大并发连接数
stats refresh 30s # 配置每隔 30 秒自动刷新监控页面
stats uri /haproxy # 配置监控页面的 URL
stats realm HAProxy # 配置监控页面的提示信息
stats auth admin:jhdcp # 配置监控页面的用户和密码 admin,可以设置多个用户名
stats hide-version # 配置隐藏统计页面上的 HAProxy 版本信息
stats admin if TRUE # 配置手工启用/禁用,后端服务器(HAProxy-1.4.9 以后版本)
listen tidb-cluster # 配置 database 负载均衡
bind 0.0.0.0:3390 # 配置浮动 IP 和 监听端口
mode tcp # HAProxy 中要使用第四层的应用层
balance leastconn # 连接数最少的服务器优先接收连接。`leastconn` 建议用于长会话服务,例如 LDAP、SQL、TSE 等,而不是短会话协议,如 HTTP。该算法是动态的,对于实例启动慢的服务器,权重会在运行中作调整。
server tidb-1 10.160.60.18:4000 check inter 2000 rise 2 fall 3 # 检测 4000 端口,检测频率为 2000 毫秒。如果检测出 2 次正常就认定机器已恢复正常使用,如果检测出 3 次失败便认定该服务器不可用。
server tidb-2 10.160.60.19:4000 check inter 2000 rise 2 fall 3
server tidb-3 10.160.60.20:4000 check inter 2000 rise 2 fall 3
1 个赞
leeray
(Lileiaab)
17
机械盘很慢满足高度读写要求。之前遇到这么高的压力下会出现这种情况吗。
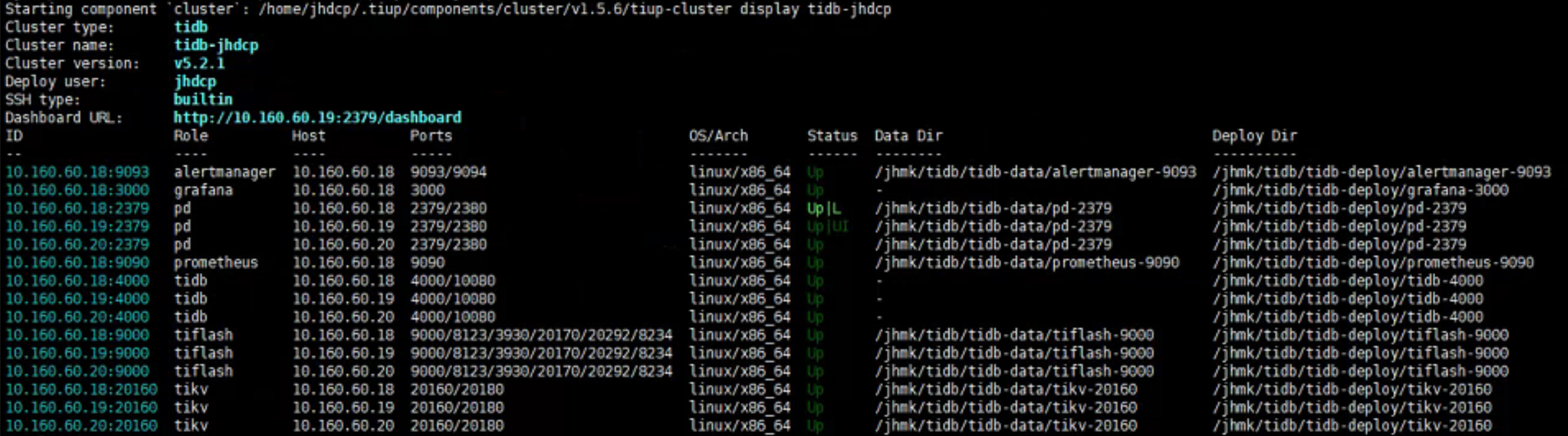
你的部署拓扑是怎么样的?如果你是每台机器1pd1kv1tidb,你们可能会遇到因为kv耗内存太大导致同一台机器上的tidb内存不够。
tiup cluster display 集群名。看看。
目前使用的是机械硬盘,但是现在问题点在于TIDB的内存不断增长,不释放,即使在低业务的情况,TIKV只是一直占用,增长没有太快
现在connection count均匀的情况下,18这台服务器占用内存也特别高
1 个赞