看一下
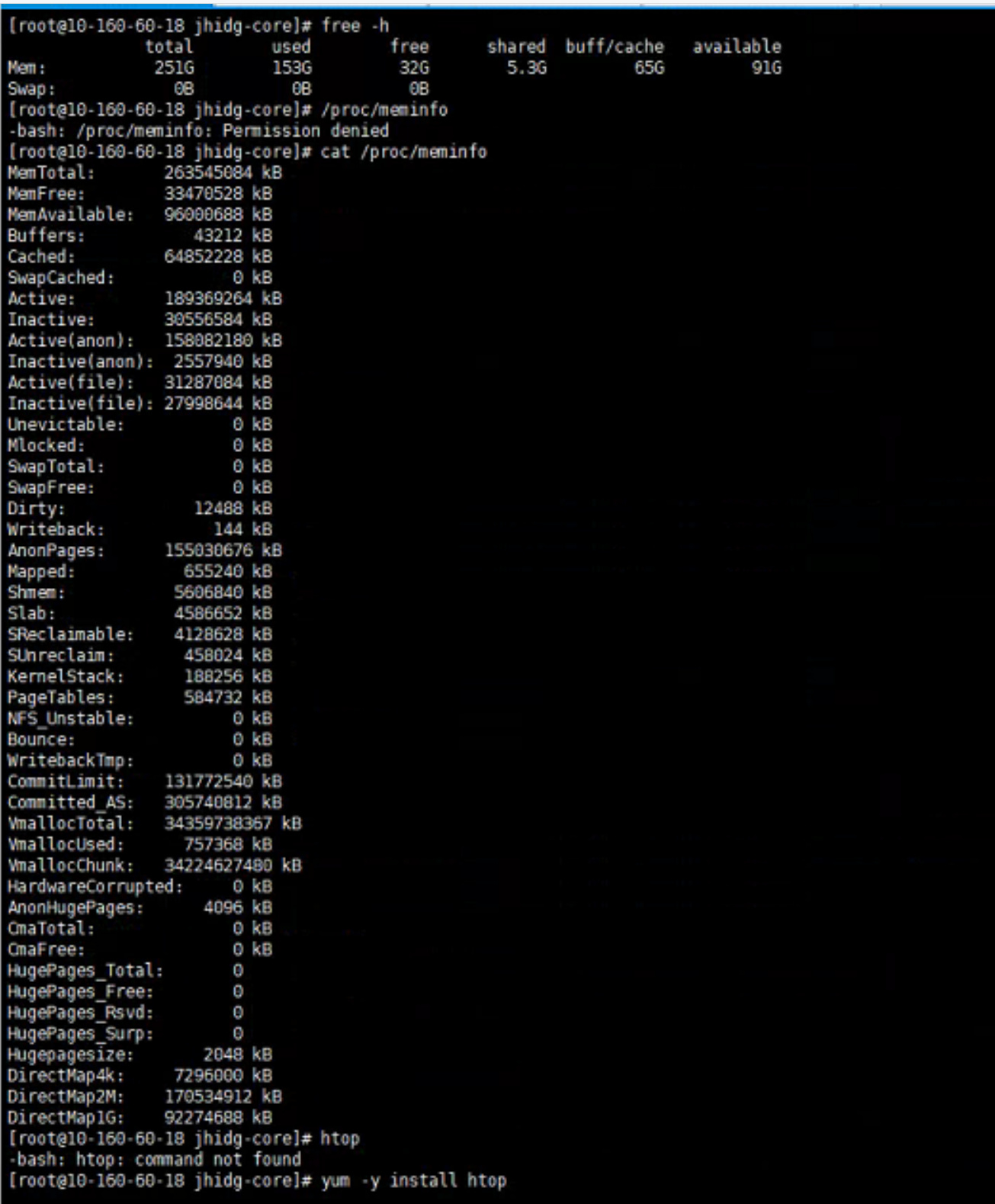
free -h
/proc/meminfo
htop
用top先看一下


使用curl -G http://{TiDBIP}:{tidb_status_port}/debug/zip?seconds=30" > profile.zip抓一下内存数据看看,
另外,60.18这台机器有没有单独加过什么配置项?
1 个赞
我用命令取的profile.zip,有空帮忙看看,谢谢
curl -G http://10.160.60.18:10080/debug/zip?seconds=30 > profile.zip
60.18这台机器没有单独加过什么配置项,和其他服务器一样,现在是重启后,跑数据业务,我观察到的现象是经常集中在某一台TIDB服务器内存一直增加,选18/19/20其中一台,现在18那台服务器内存已经上升到60G了

1 个赞
你这个业务是不是经常有查询大结果集的SQL,慢查询页面是否有异常SQL,看下processlist情况:
select * from information_schema.processlist order by MEM desc;
1 个赞
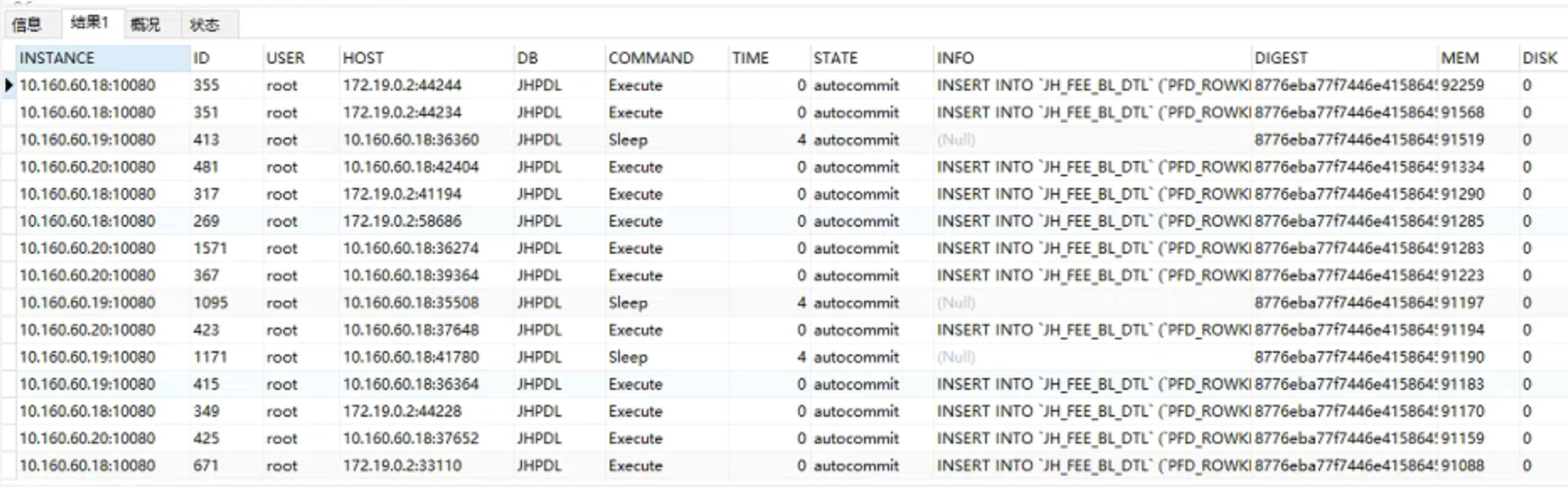
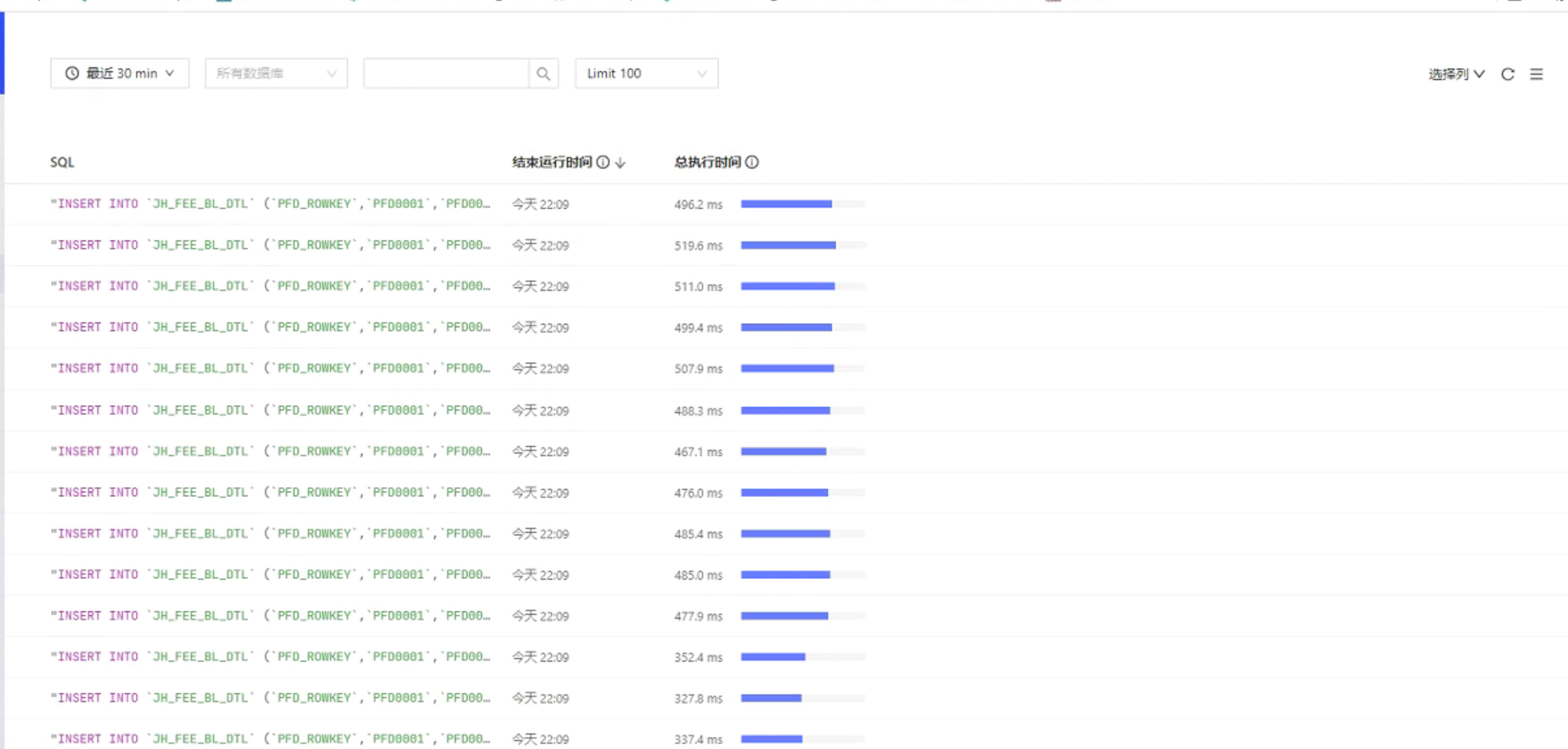

看一下这个TiDB节点的报错日志,有没有频繁发生OOM导致进程被OS干掉
1 个赞
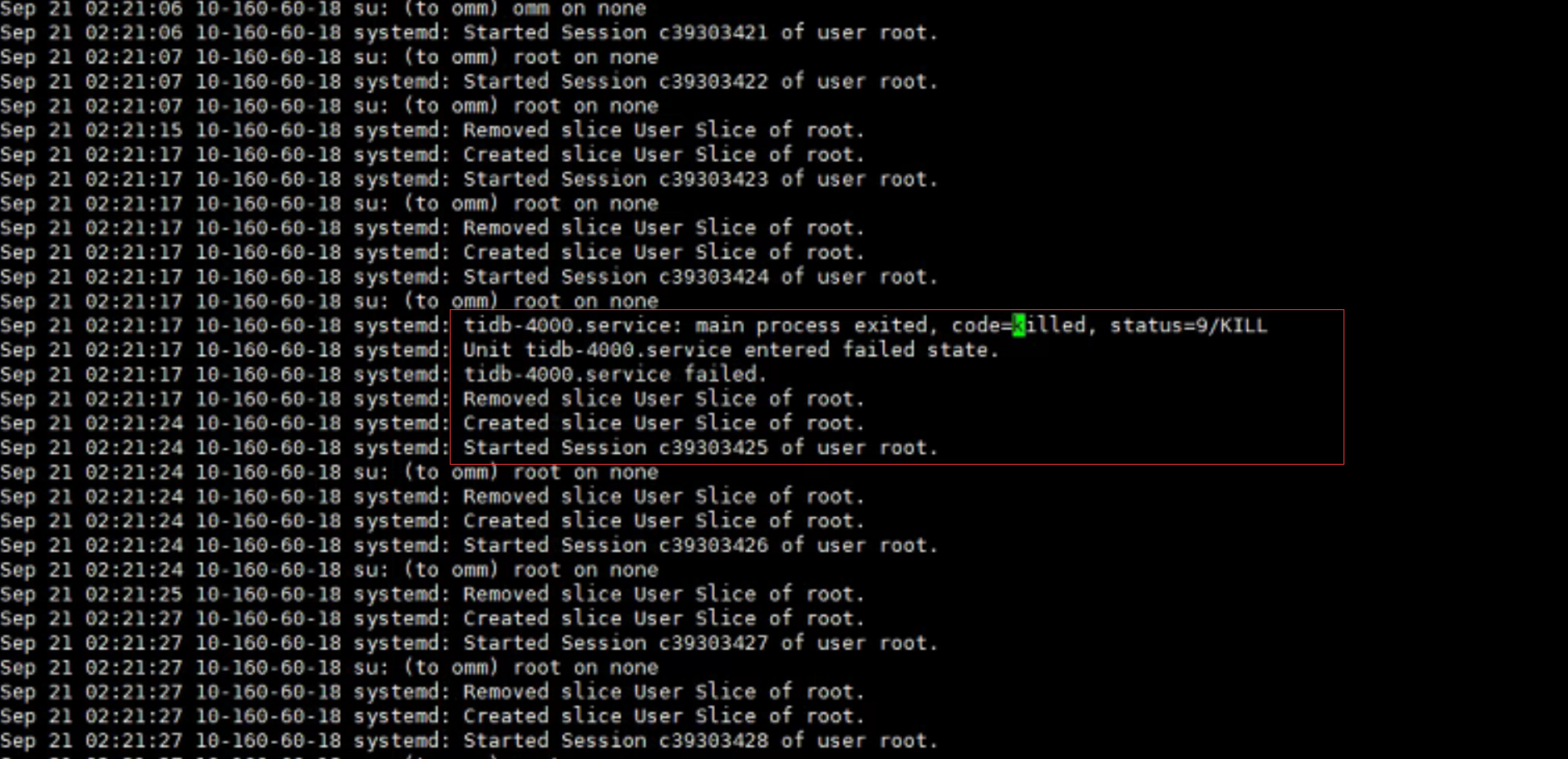
是被OS系统kill掉的,看/var/log/message就知道,如图,有这么一个规律,resource_control的memory_limit设置为96G,当tidb程序内存接近这个值,就会触发kill服务,然后重启操作,如果设置为64G,会接近64G的时候kill掉,这个验证过了。
所以问题点在于如何释放不断增长的内存,使其不经常重启。
1 个赞
有些内存,被占用了,不会立即释放,但可以被下次的连接使用,至于限制内存方面,可以看看上面发的链接
设定单条SQL最大执行时间,最大占用内存
不断的优化慢 SQL
除此,别无他法… ![]()
开启 oom-use-tmp-storage 之类的参数等也行,其实还是有很多参数可以调整的,可以先试试。https://docs.pingcap.com/zh/tidb/stable/tidb-configuration-file,看集群已经是 v5.2 了,内存相关的控制 还是比较 ok 的了
1 个赞
oom-use-tmp-storage默认是开启了
问题解决了吗?
问题还没有解决,目前试了一下一些oom参数没有效果,其实很多默认就好了
你的问题其实有2个对吧:1、热点问题,即 tidb-server 使用不均衡。2、OOM 问题
1的问题,先不管,可以先看2,你配置 90+G ,已经配置很高,按道理不会,帮把 tidb-server/tikv-detail/oview 的监控导出一份给我吧(可以参考:https://asktug.com/t/topic/37248)
1 个赞
目前怀疑TIDB里面有个自动ANALYZE TABLE,可能有bug,导致内存不断上涨,我确认好回复一下你,监控图我看看怎么导出先