peace
(三文鱼)
1
均为独立部署,无混合部署
-
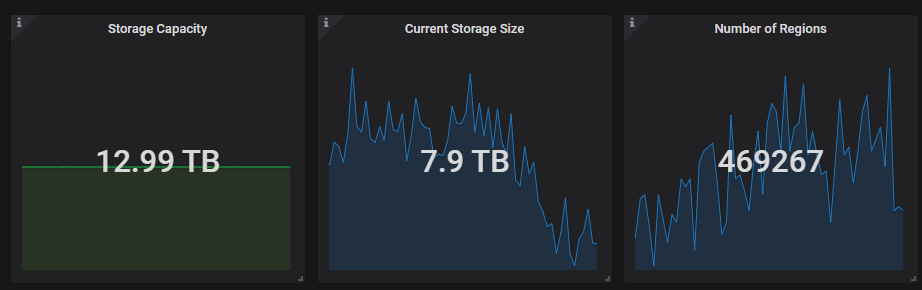
【数据量 & region 数量 & 副本数】
-
【问题描述(我做了什么)】
tidb集群用途说明:从上游分库分表的mysql中,通过DM工具同步聚合数据到tidb集群。
问题描述:
- 2019-10-20 18:00左右,DM同步开始出现延迟,业务数据没有及时同步到tidb集群中。
- 2019-10-21 15:00,怀疑是DM同步数据量较大的问题(事实上业务数据并没有增长),把DM任务全部停掉,观察tikv集群负载并没有降低,磁盘IO流量仍然很大,可以判断和业务DM同步没有关系。
- 2019-10-21 16:00 怀疑是tidb集群内部在做数据搬迁导致CPU和IO飙涨,初步诊断是在做region balance,以下是2019-10-20 - 2019-10-21号两天可能能帮助定位的监控视图
1 region分布
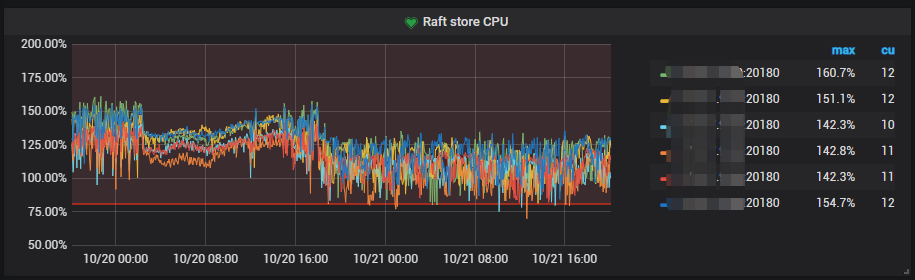
2 Raft store CPU
3 Scheduler worker CPU
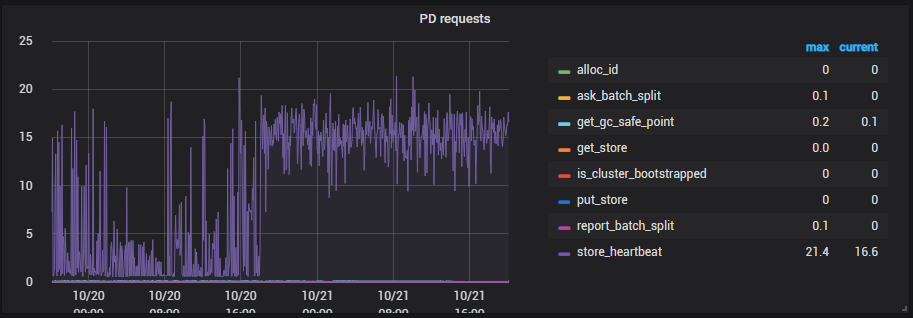
4 PD request
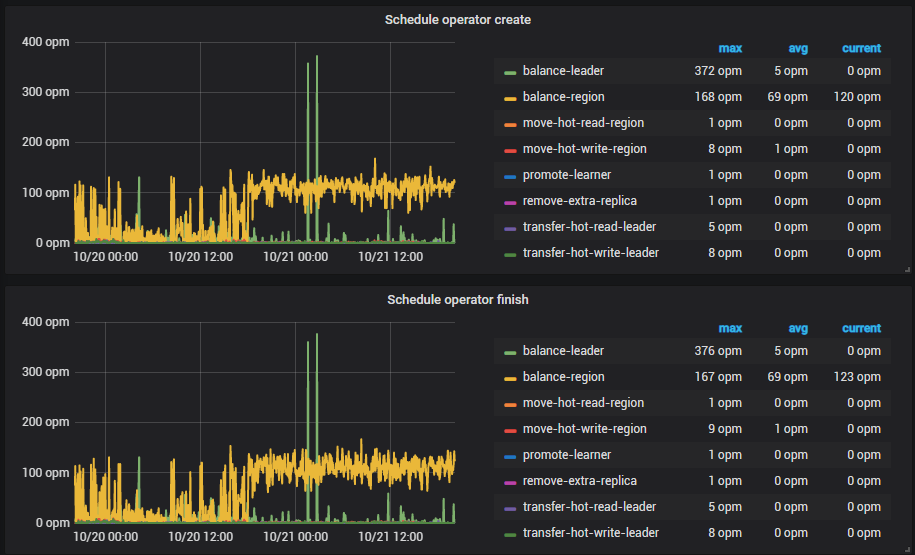
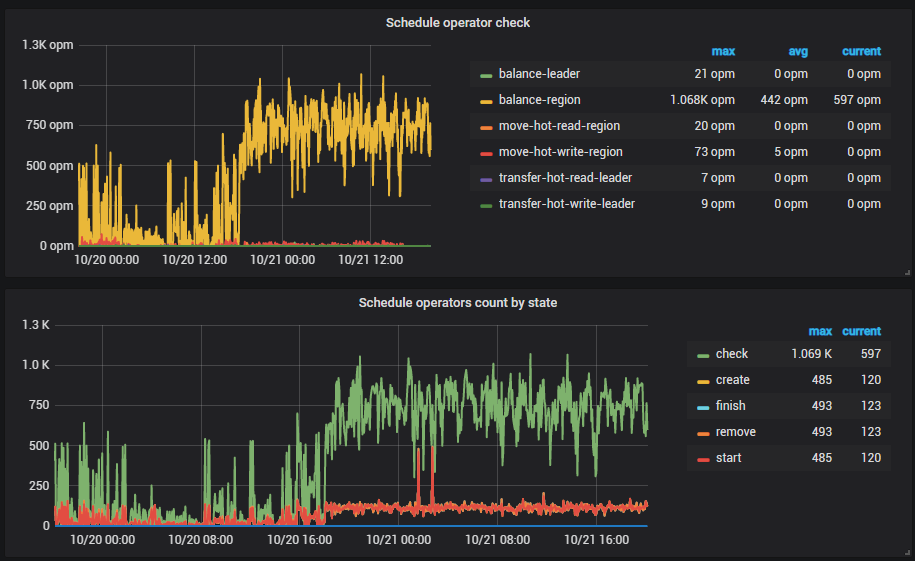
5 PD Operator
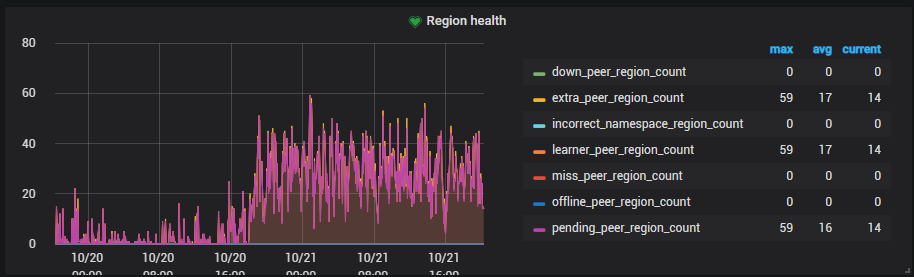
6 region health
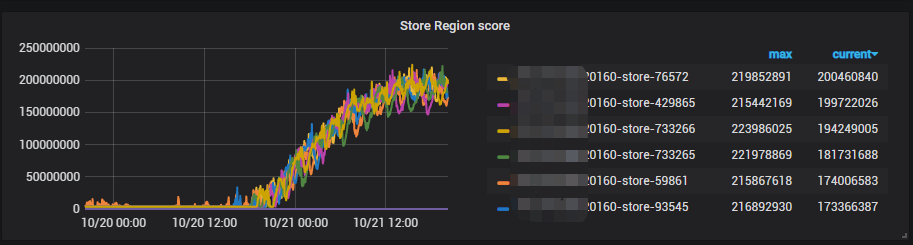
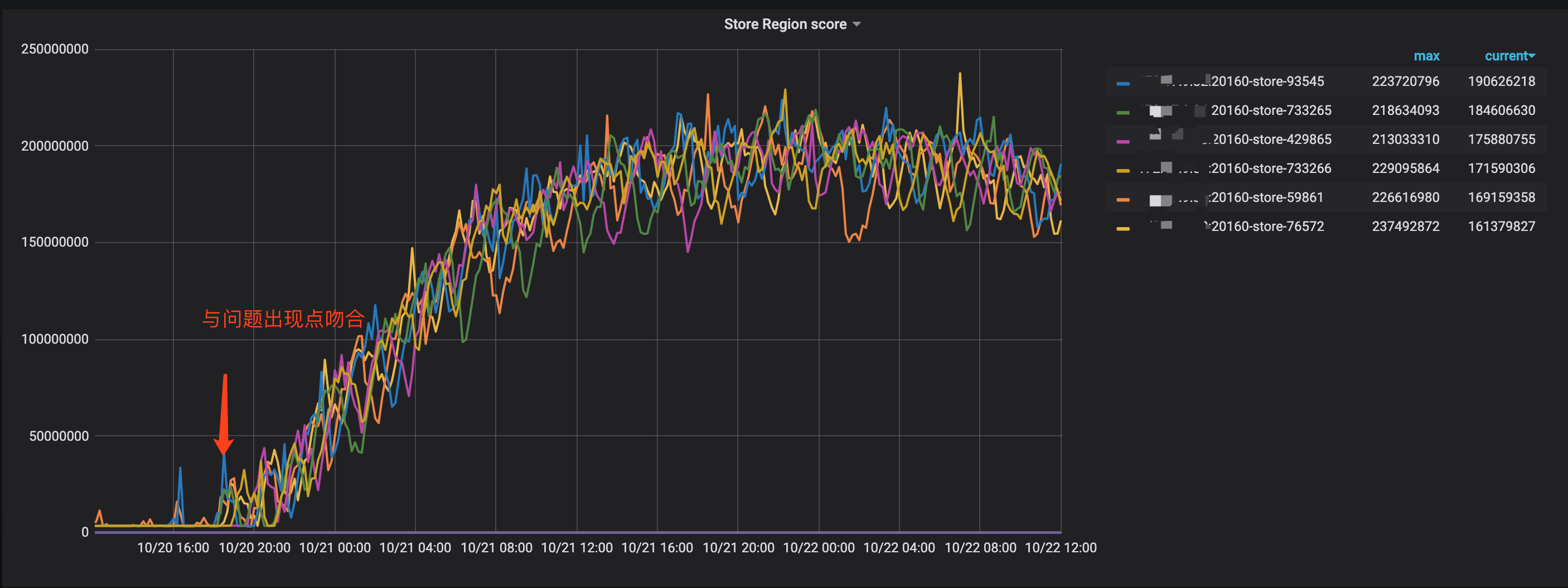
7 Store Region score
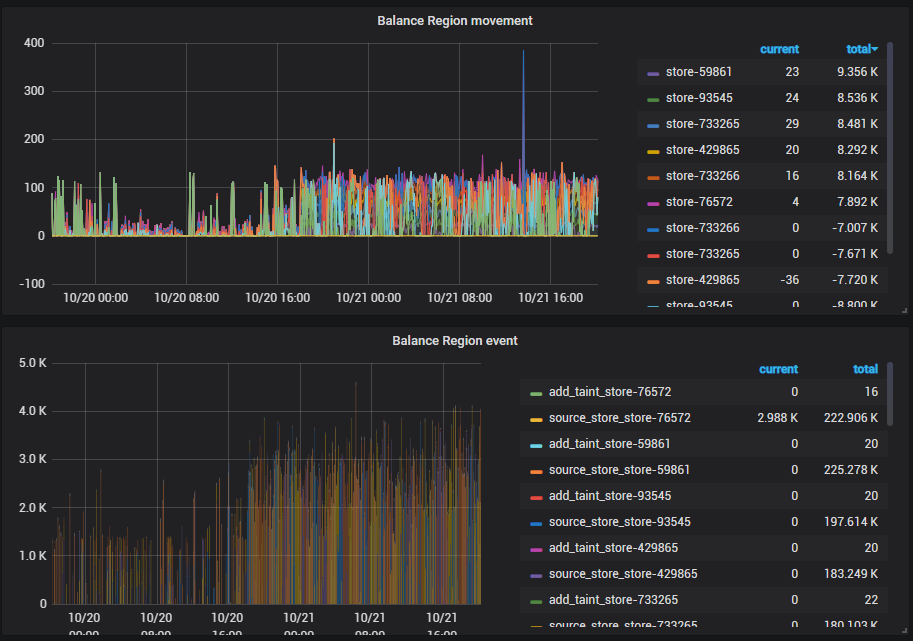
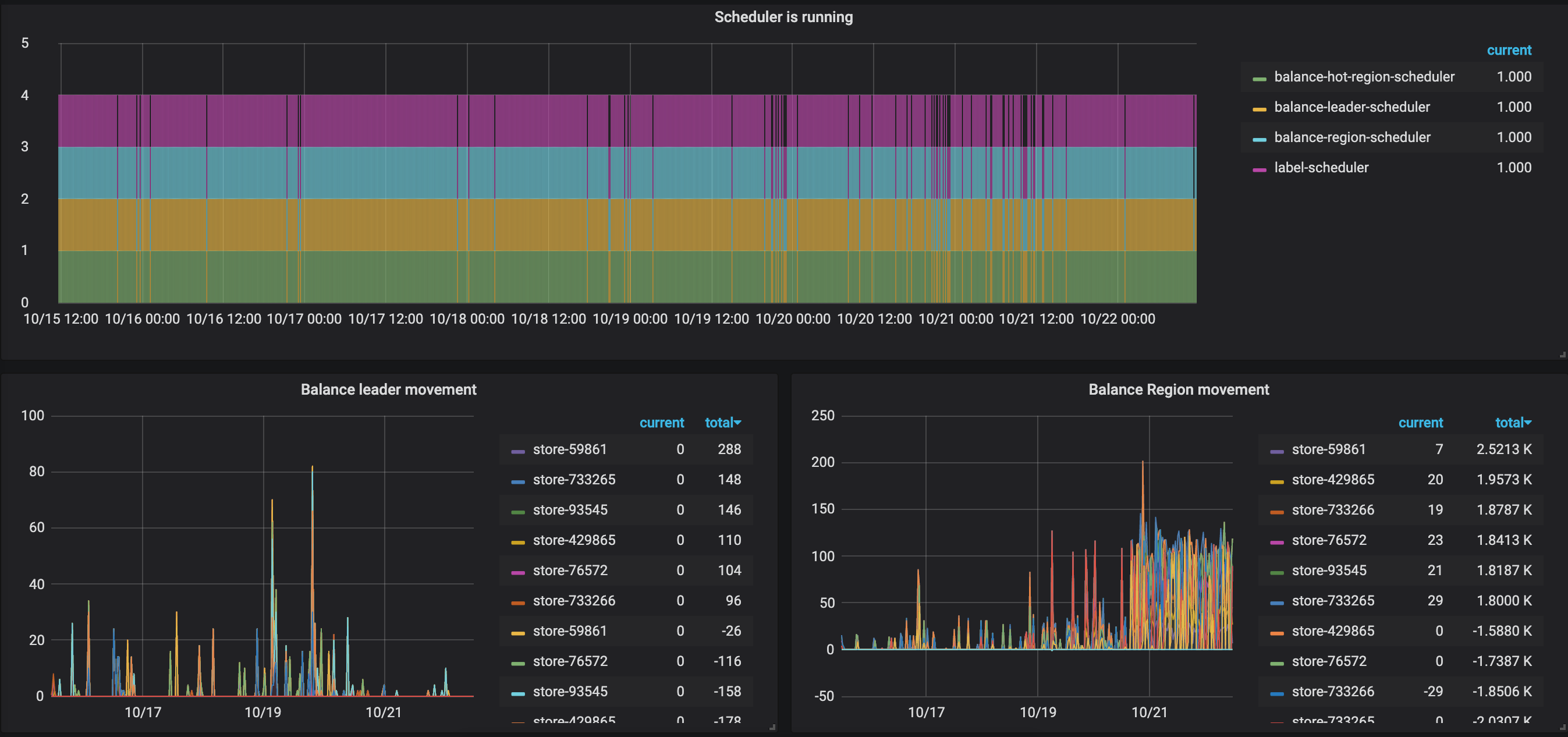
8 Balance Region movement
想请教一下,tidb集群到底在做什么操作,触发这个操作的原因是什么,目前已经过去了一天的时间,为什么操作一直在执行,有什么办法可以解决
region 数量过多了,有无开启 region merge?
roman
(roman)
3
好奇一下, 如果还没有启动region merge, 在这种情况下,启动后,会不会正常呀?
建议从如下几点进行排查:
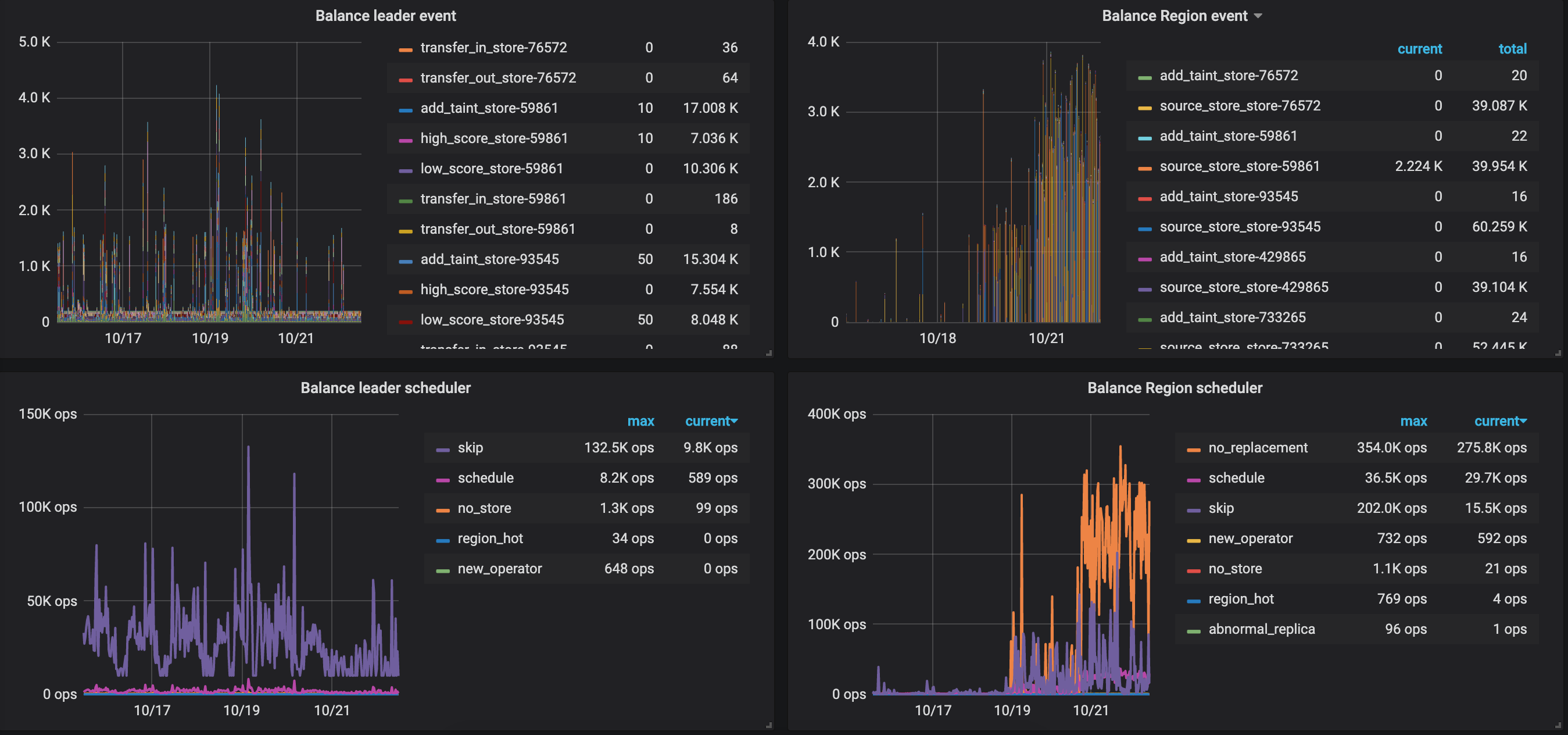
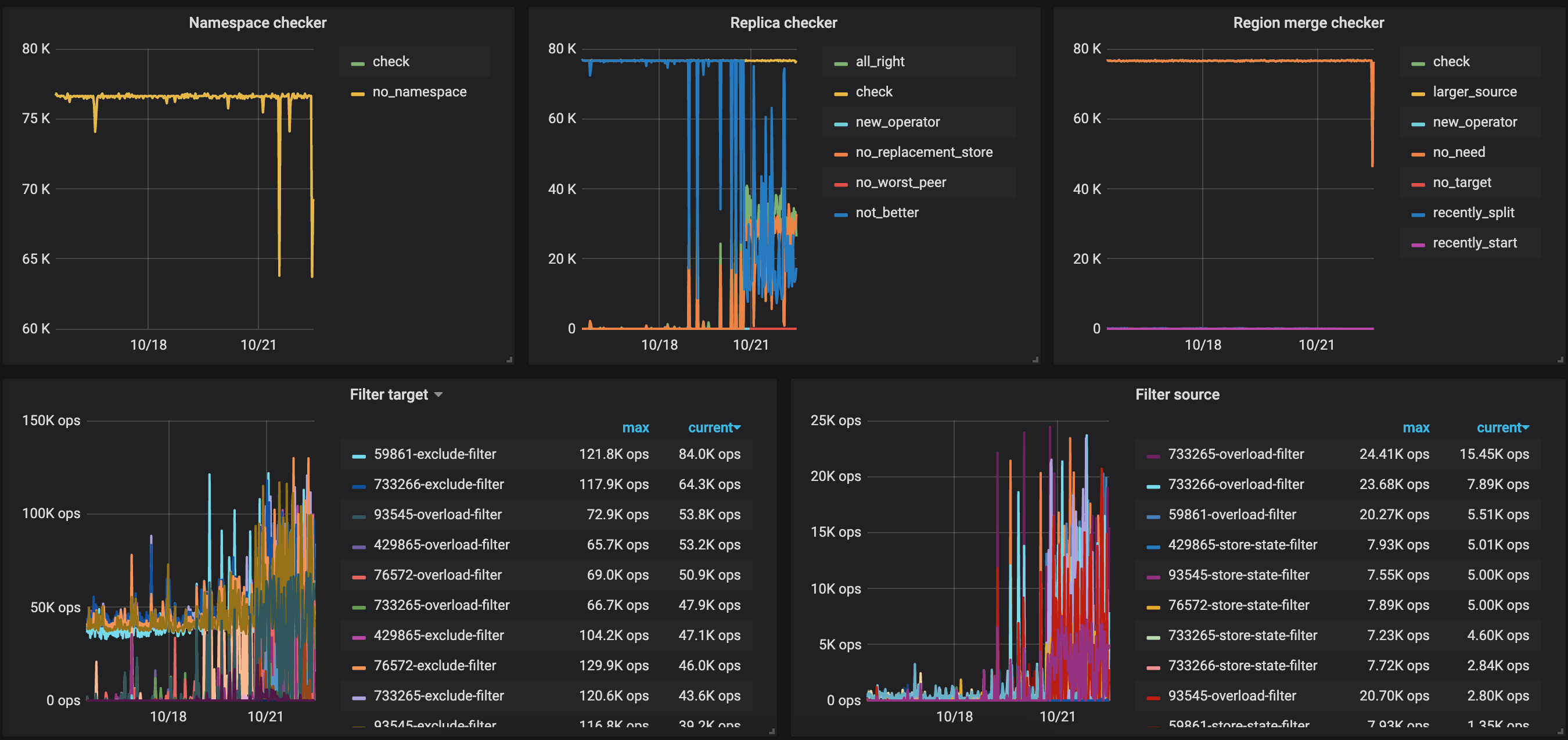
1、看下监控面板 pd --> Scheduler 中 balance 相关的监控项,确认下是否仍然在做 reblance 的操作
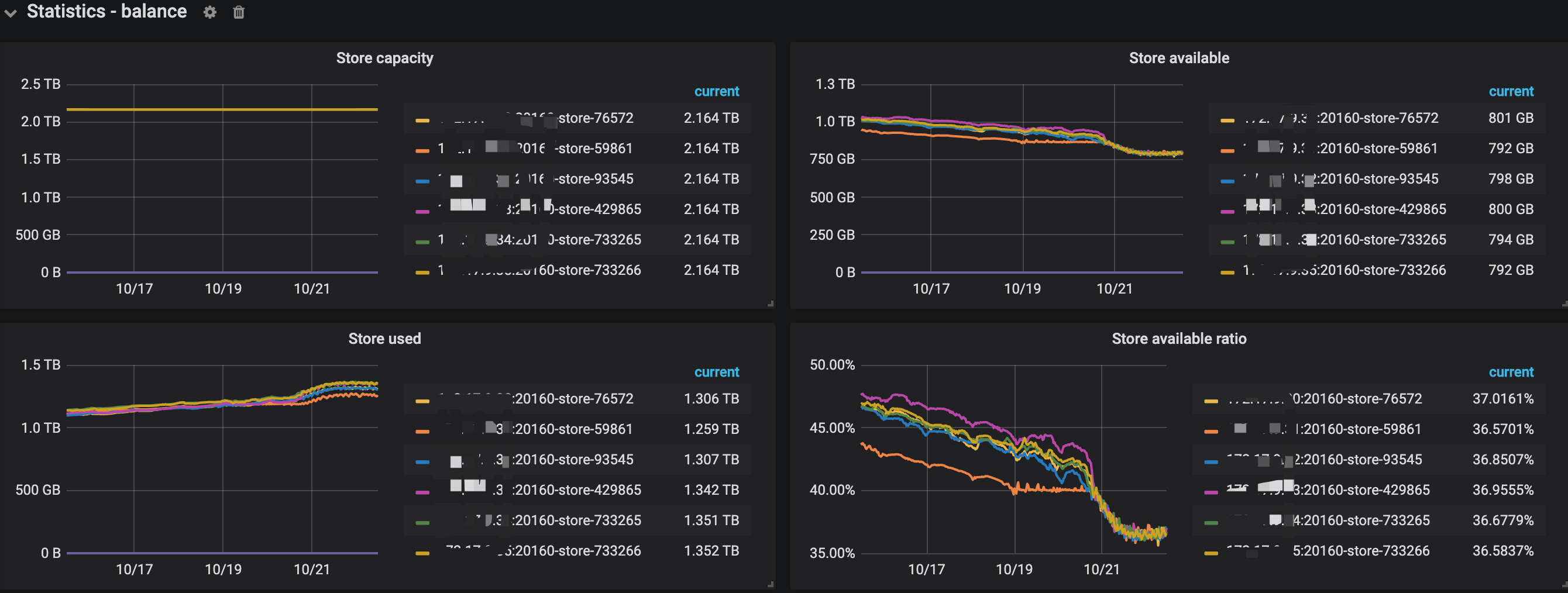
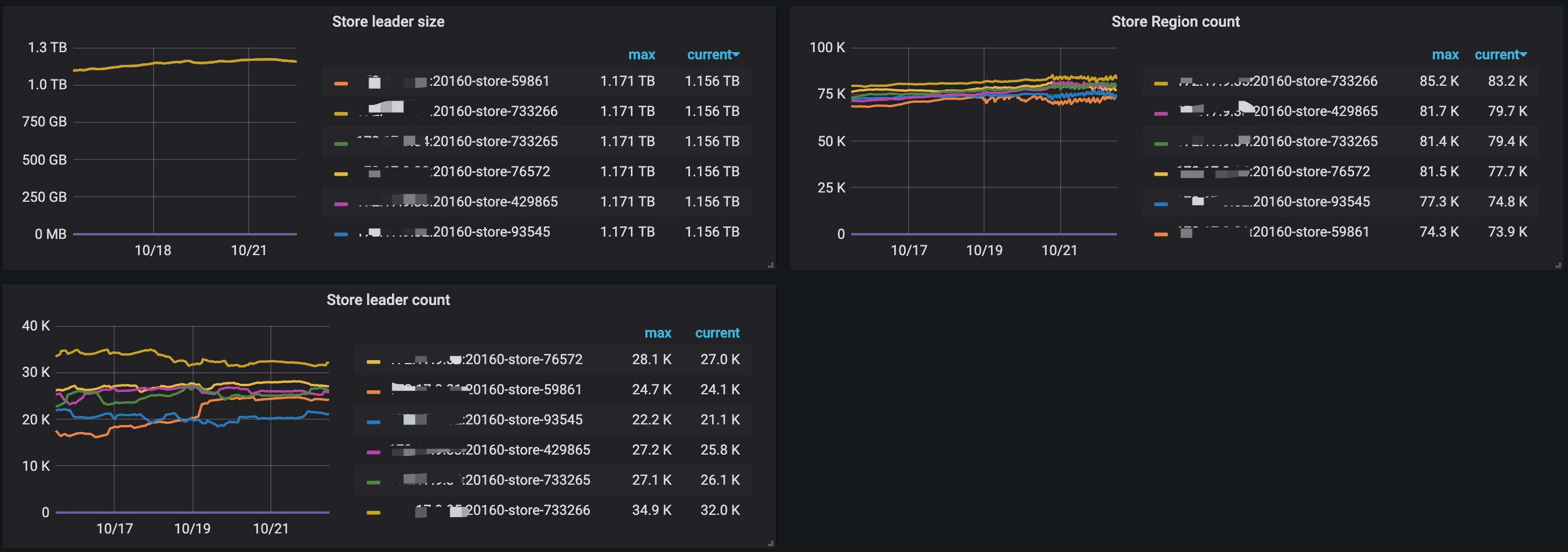
2、看下监控面板 pd --> Statistics - balance 中 region count / score,以及 leader count / score 相关的监控,确认下各个 store 的 region 的总量以及 leader 的数量分别是多少
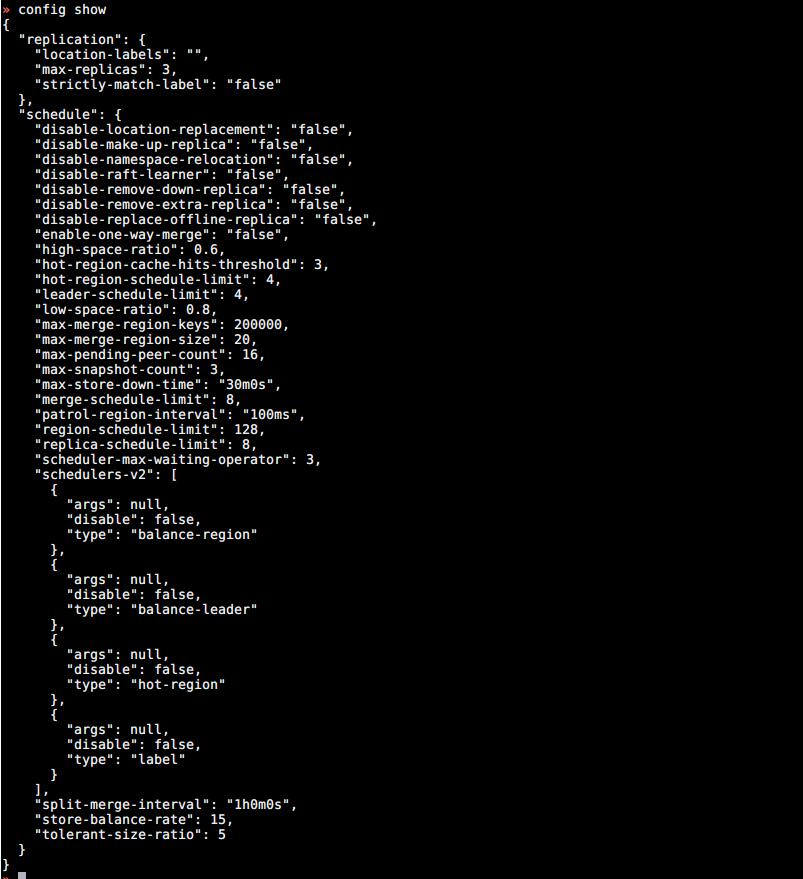
3、pd-ctl show config 看下 region-schedule-limit 、leader-schedule-limit 以及 replica-schedule-limit 相关参数的配置
peace
(三文鱼)
5
感谢关注和解答!
1 pd → Scheduler 中 balance 最近一周相关的监控项
2 pd → Statistics - balance最近一周相关的监控项
3 pd-ctl show config:
max-merge-region-size 20M
max-merge-region-keys 200000
merge-schedule-limit 8
---------这三个参数是上午刚改的,之前没有配置region merge
peace
(三文鱼)
6
感谢关注和解答!
之前我这边没有开启region merge,今天上午(2019-10-22 上午10点左右)开启了,目前看tikv正在做region merge,region数量在以每小时800个的速度减少。
另外有个问题请教一下,region数量超过多少了算是过多了?region数量过多会导致什么问题呢,触发region balance吗?
peace
(三文鱼)
7
补充一个可能可以提供帮助的监控项,和问题发生的时间基本吻合,Store Region score在什么情况下会飙涨起来呢
1、region merge 开启后,在一定程度上也会增加 IO 成本。
2、 这个参数设置的过大,如果要开启 region merge 那么建议将这个参数调整成 8(参照 region merge scheduler limit 设置)。如果不开启 region merge ,那么也建议将该参数调整为 8。
这个参数设置的过大,如果要开启 region merge 那么建议将这个参数调整成 8(参照 region merge scheduler limit 设置)。如果不开启 region merge ,那么也建议将该参数调整为 8。
3、另外,如果 region 数量较多会增加心跳消耗,从监控看 raftstore 的 CPU 使用较高,可以适当的调整下 region base tick 参数适当调整大,默认为 1s。调整大后,会增加 leader 选主的时长,故,请综合考虑。
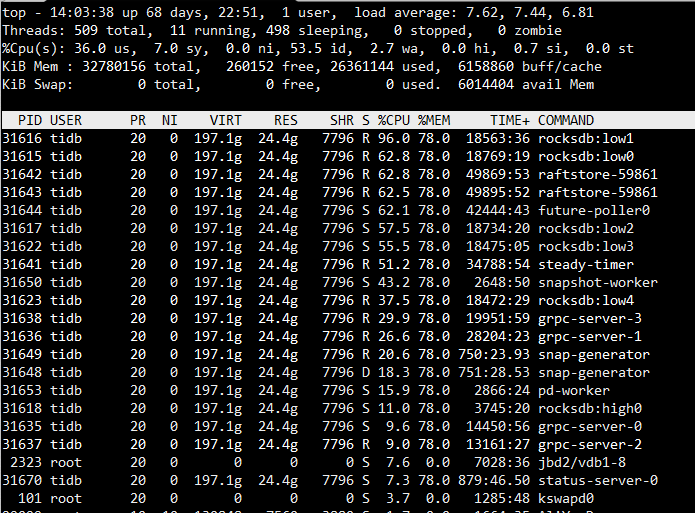
4、在操作系统层 使用 top 命令看下 tikv 服务器 io 比较高的线程是什么。
peace
(三文鱼)
9
好的,我重新调整一下region scheduler limit。
下面是tikv一个节点的top信息,其他几个tikv节点是类似的
peace
(三文鱼)
10
另外想问一下,region balance在什么情况下会大量触发,是region的数量达到一个瓶颈值之后么?
region 的 balance 是依据 pd 的调度算法,具体可以看下下面这篇文章:
另外,如果 IO 压力仍然很大,建议可以看下 tikv rocksdb compaction 相关的监控信息,一般情况下,磁盘 IO 压力大可以从以下几个方面排查:
1、region 调度,merge 情况
2、rocksdb compaction
3、前台业务高并发 DML 操作
peace
(三文鱼)
12
在@ zhenjiaogao-PingCAP和 Kay-PingCAP的帮助下,问题已经解决。
开启region merge一段时间,region数量下降到一定阶段,region balance完成后,tikv节点的磁盘IO已经下降到正常水平
重新启动DM工具,目前数据已经开始在同步了。
system
(system)
关闭
13
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。