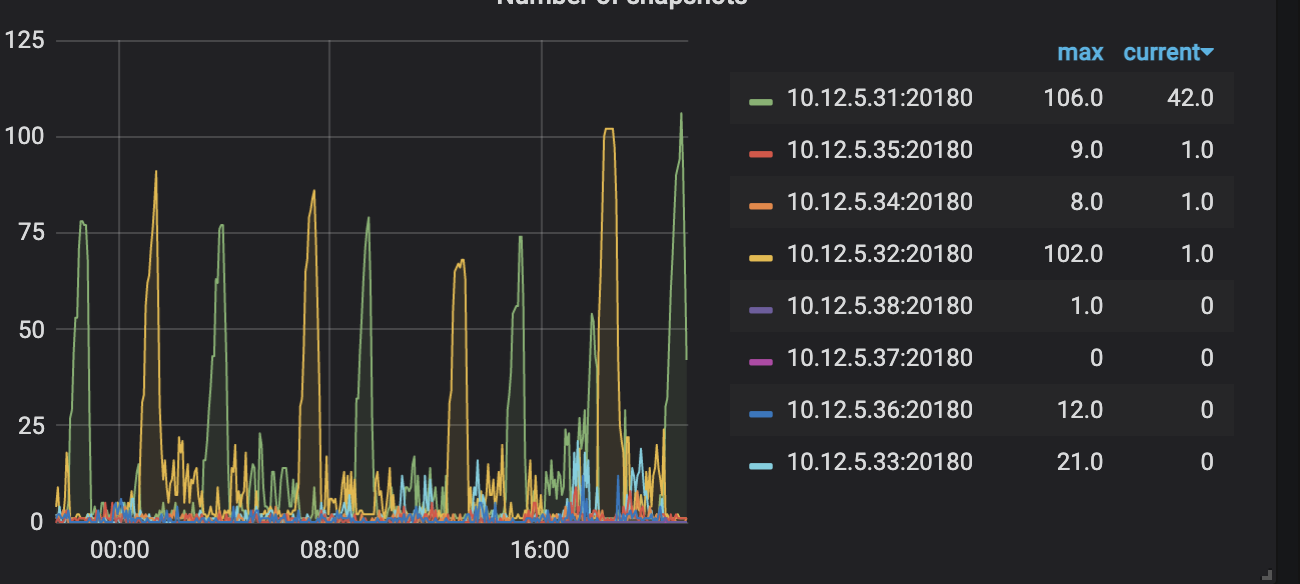
如图所示,两个kv节点交替性地每个一段时间snapshot数量就大幅上升,造成的现象为集群中大量查询阻塞并返回失败

关于snapshot以此关键词搜索在社区并未找到太多相关信息,推测是因为这两个节点的磁盘i/o跟不上导致,然而集群中所有kv节点均是相同ssd磁盘,为何只有这两个节点交替出错,以下是31,32节点的log和监控面板信息,烦请帮忙分析,谢谢
链接: 百度网盘-链接不存在 密码: 8f3m
该问题为 集群中查询全部tikv server timeout,查看监控发现为某一kv大量pending 帖子的后续,已经按照该贴意见进行了扩容
是我漏掉了吗?没有看到具体是哪个版本? 麻烦帮忙确认下,多谢。
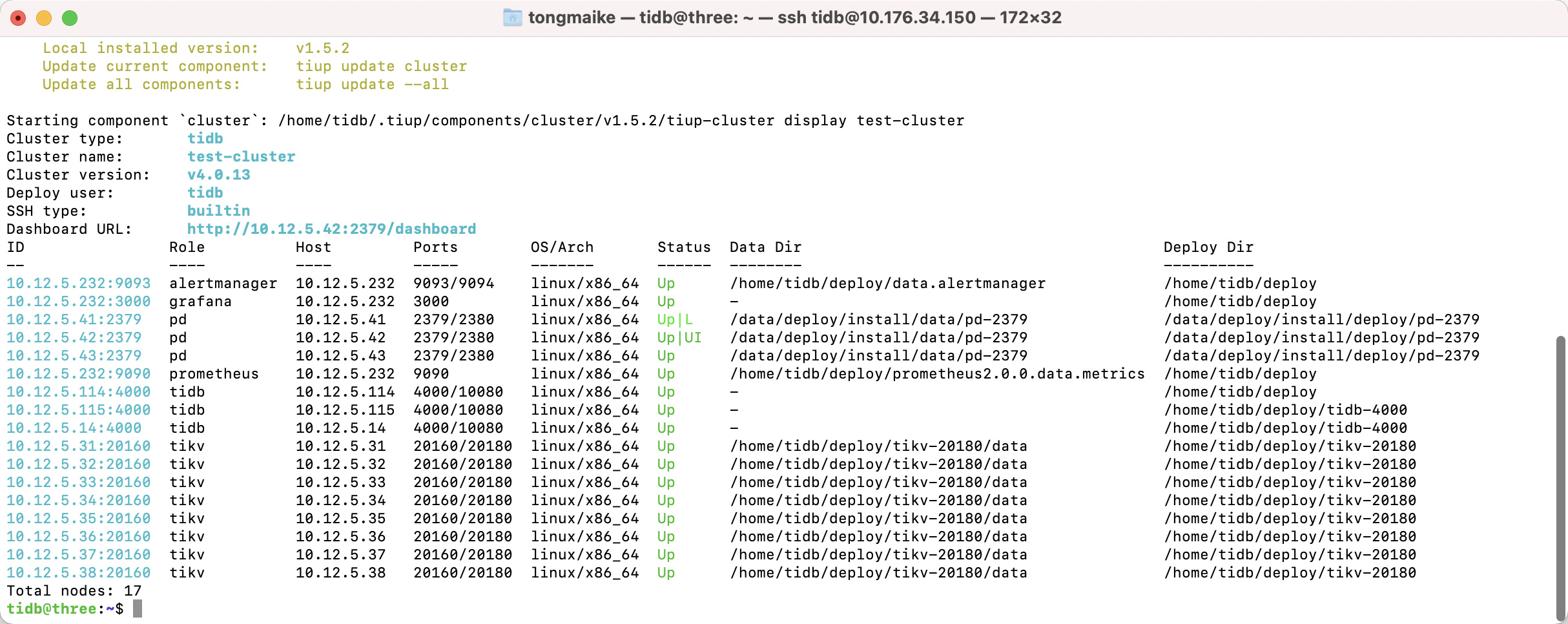
- 从监控看这两个节点的写都比较慢,平均 100ms ,可能是盘不行。
- 间接性的读流量会比较大
- 除了盘的问题,麻烦帮忙看下 region topread 和 region topwrite,是否业务主要集中在了这两个节点所在的region?导致只有这两个节点流量高。
https://docs.pingcap.com/zh/tidb/stable/pd-control#region-topwrite-limit


1、2我查看了另一个集群中正常的节点如图
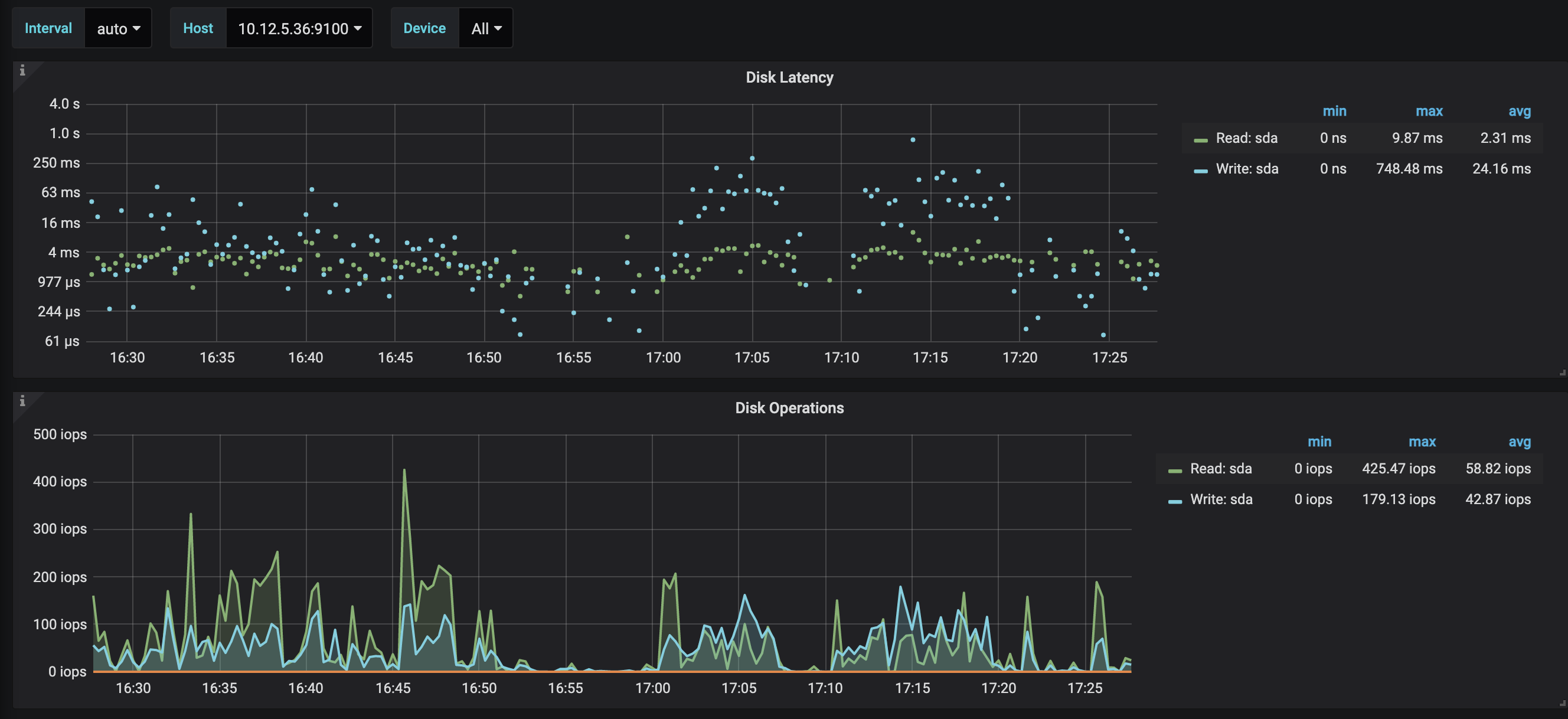
从平均延迟来看确实比31节点少,其他几个节点的也都没到三位数
3、store,read,write如下
topwrite.txt (12.1 KB) topread.txt (12.8 KB) store.txt (8.3 KB)
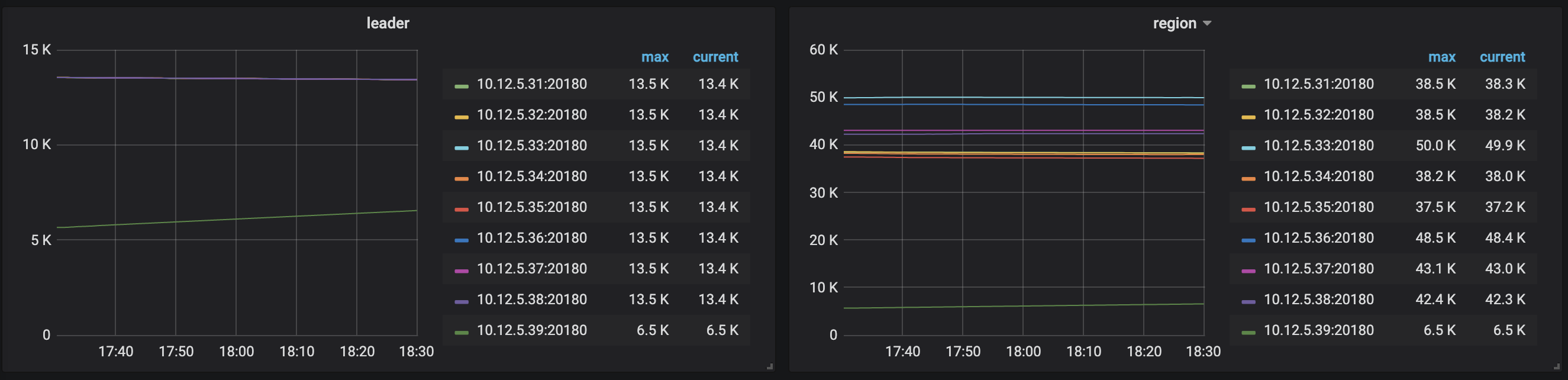
集群中所有节点的硬件都是一模一样的,综上来看应该是热点问题?
看了下,感觉在这两个节点的 topread 和 topwrite 也不是很多。有没有可能尝试扩容一个新节点,缩容一个31或者32节点,看看是否会转移? 验证下是否是 31,32 两个节点有问题。(目前看是这两个盘可能有问题。)
是的,等扩容完成再缩容吧。另外可以根据业务低峰期,尝试加快扩容。
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#pd-调度策略最佳实践
31、32节点的阻塞,大约是每四个小时出现一次,并且整个集群中仅有该两个kv节点有该情况。
针对这一现象,我检查了业务代码,并未发现有明显的周期性读写操作,该两个kv节点分别部署在不同的物理机器上,上面也没有任何定时任务。
我在停掉业务代码后,观察到该现象依然存在,通过查看dashboard可以看到已经没有业务语句了

31、32两个kv节点如期出现高读取
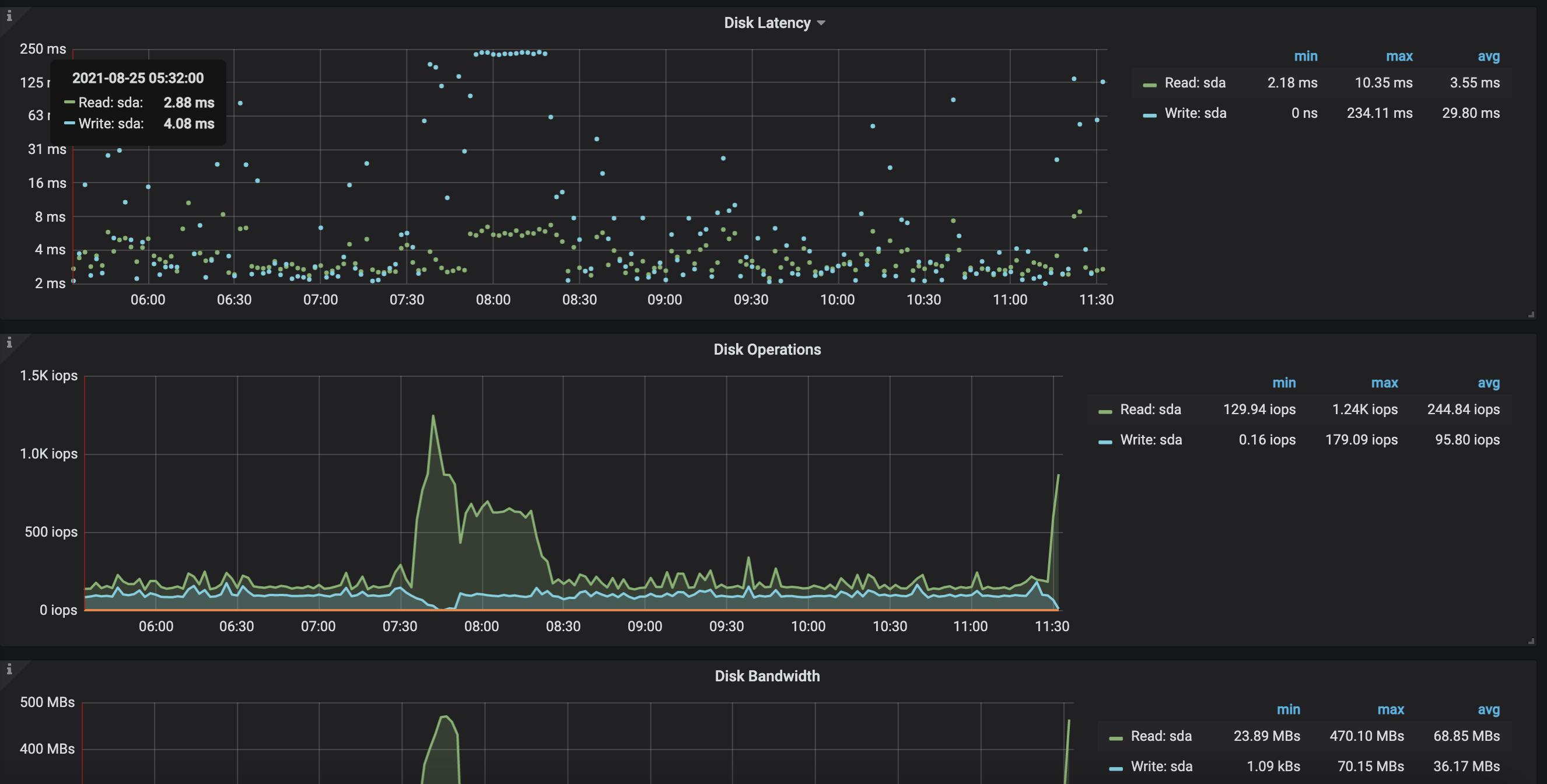
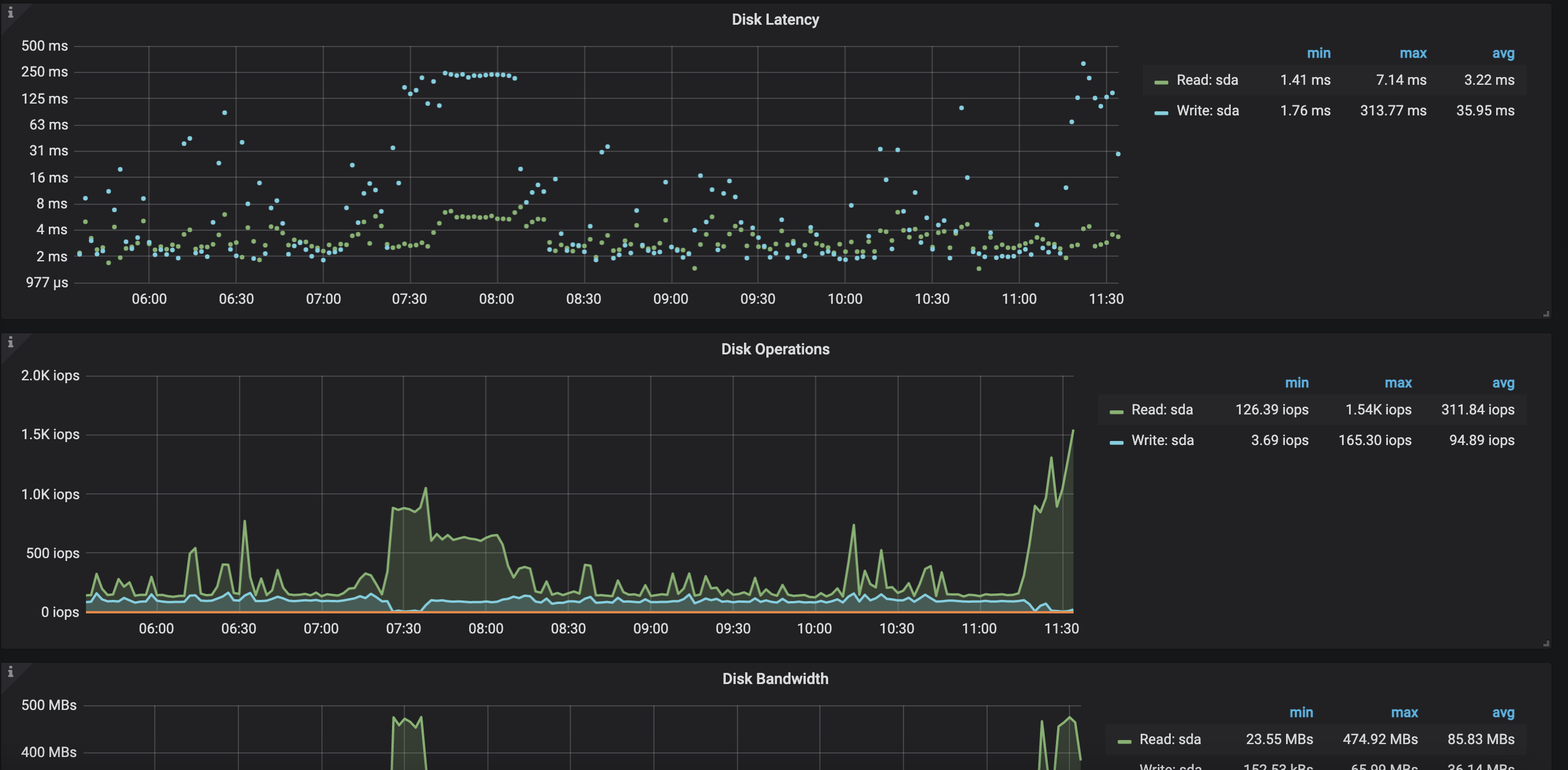
两个节点近期主要情况如下图

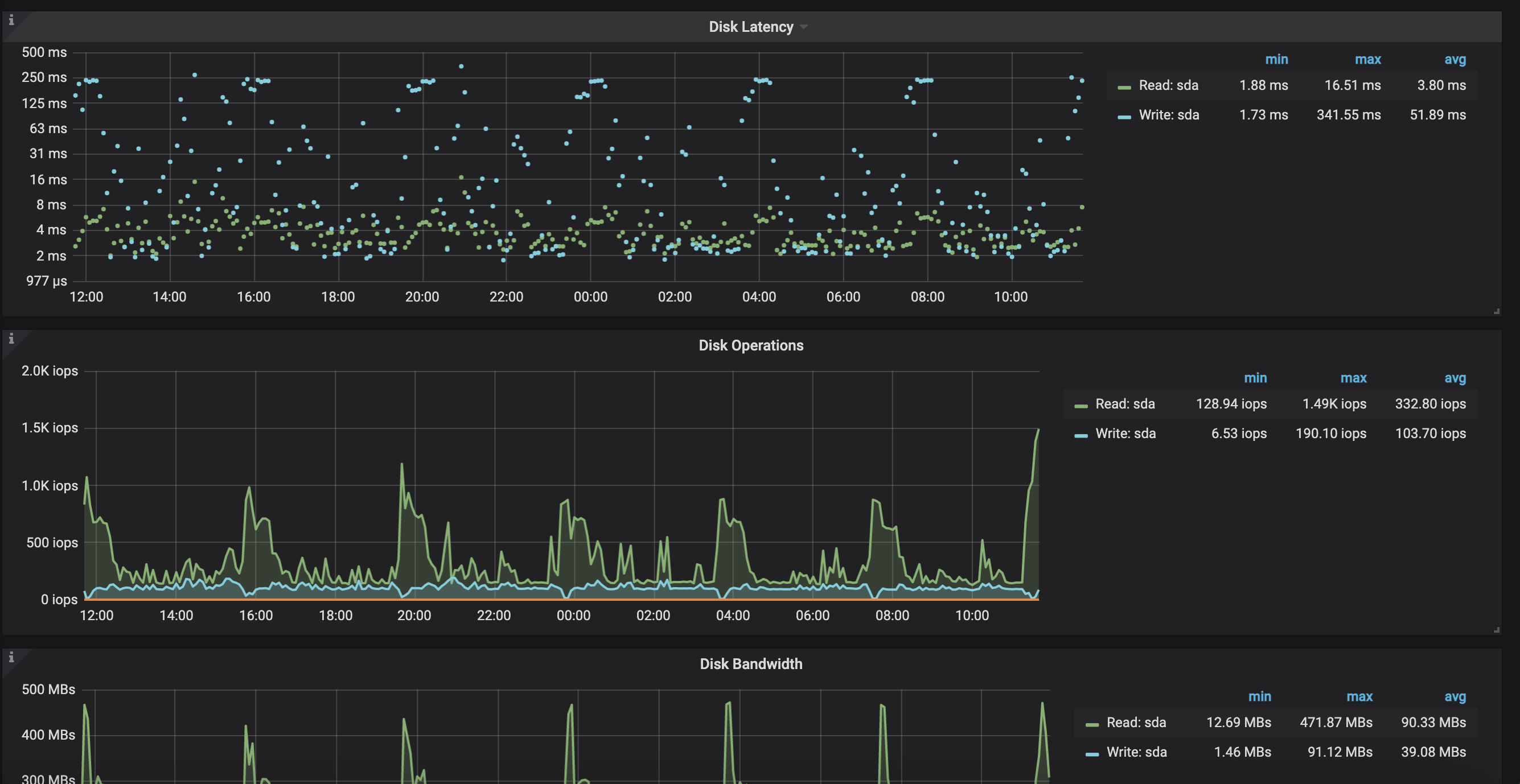
可以看到及其明显的规律,而其他节点则完全不同
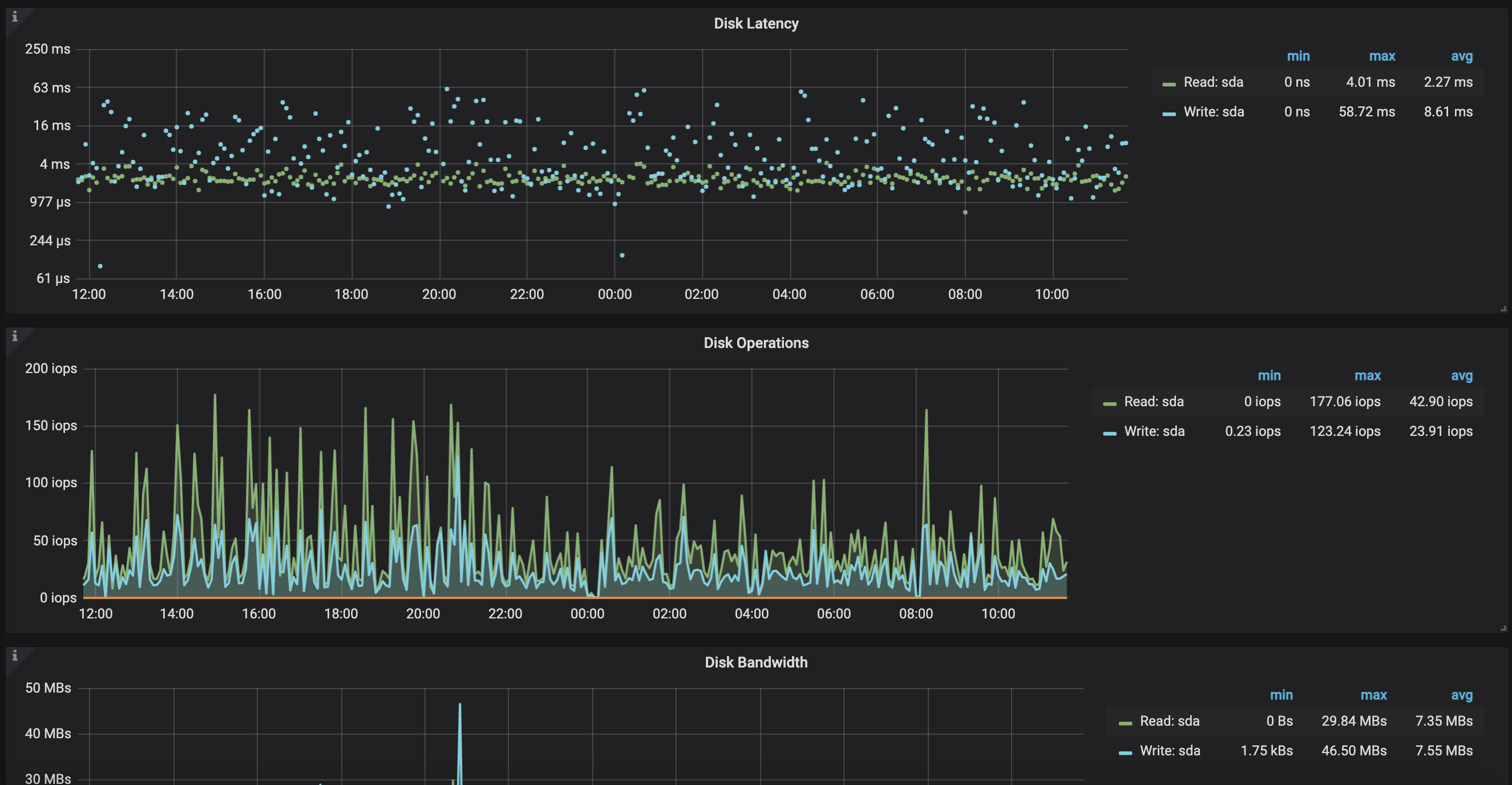
排除业务可能性,思考这可能为tidb内部的读写,因此查看调度,发现balance-region的状况与其惊人一致,初步推测为balance-region调度完成后落盘,但这似乎也无法解释为何只有两个节点的读写状况与其吻合
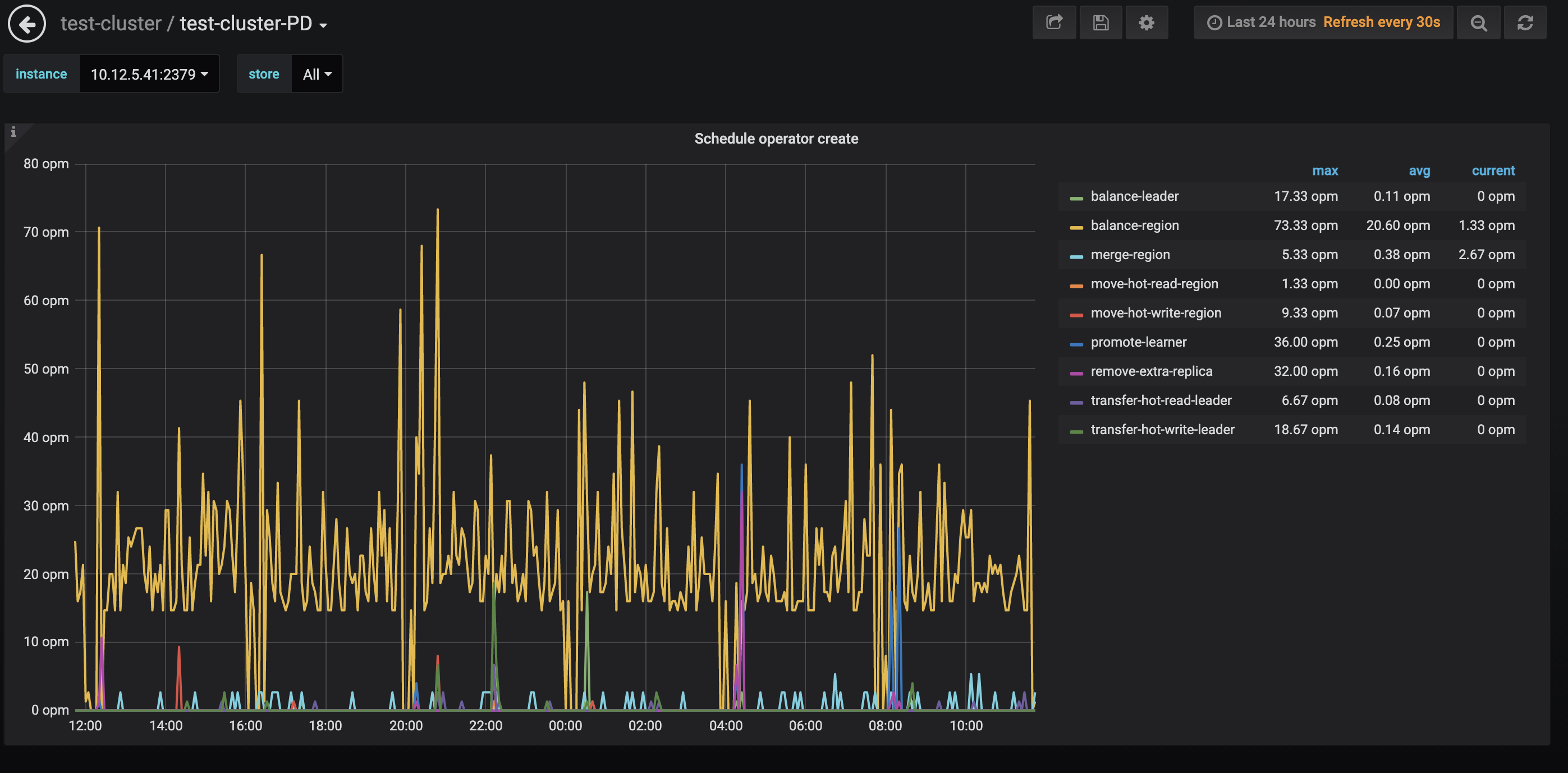
以下附上全套日志,日志收集时间为今日上午9点左右,在此之前便有该问题的存在,烦请帮忙分析一下上述情况的发生原因
链接: 百度网盘-链接不存在 密码: qdsv
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。