集群状态全up
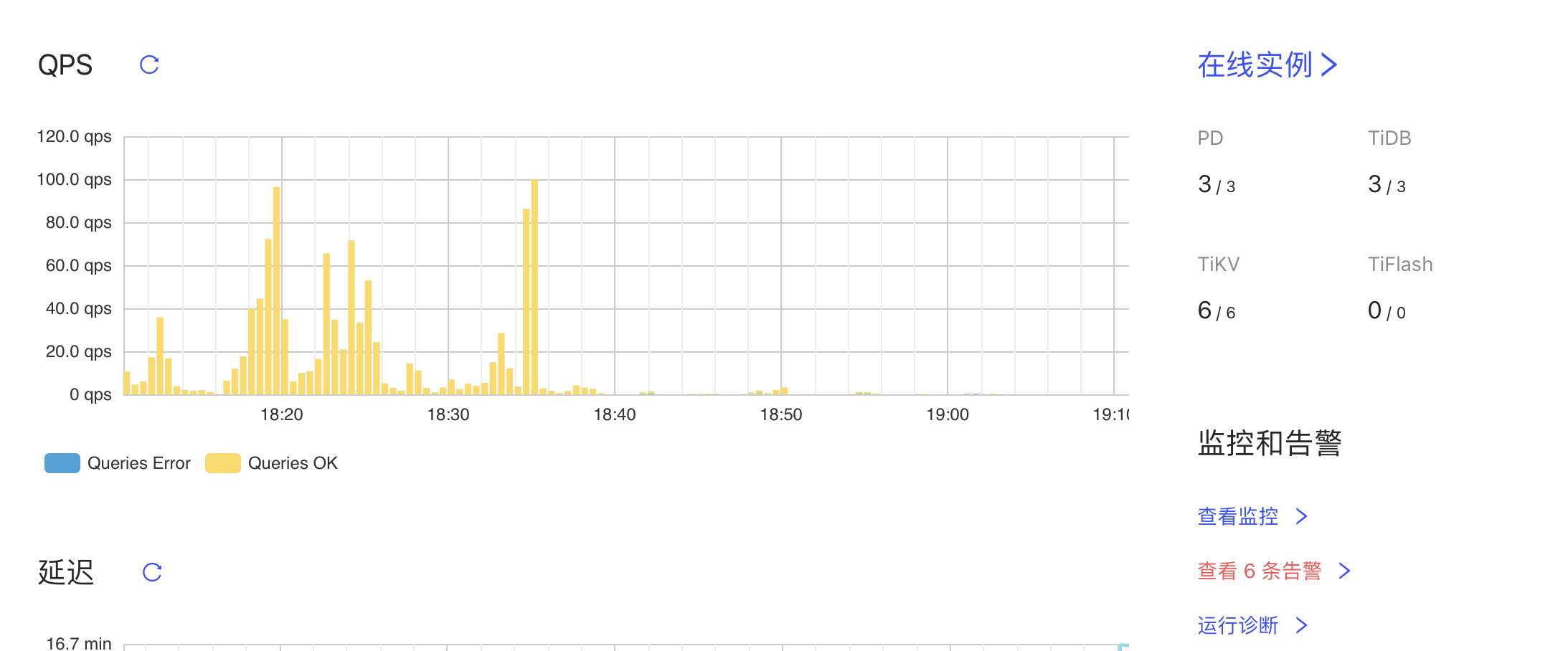
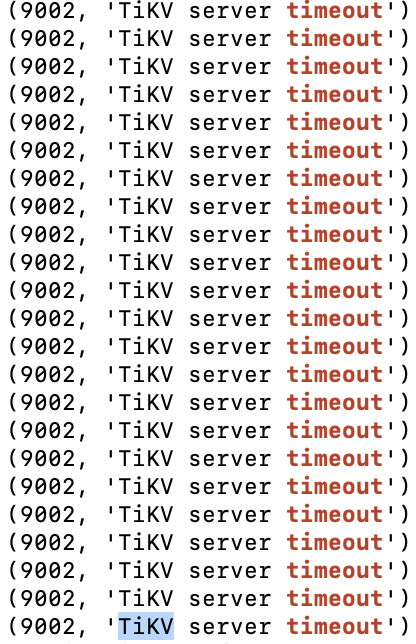
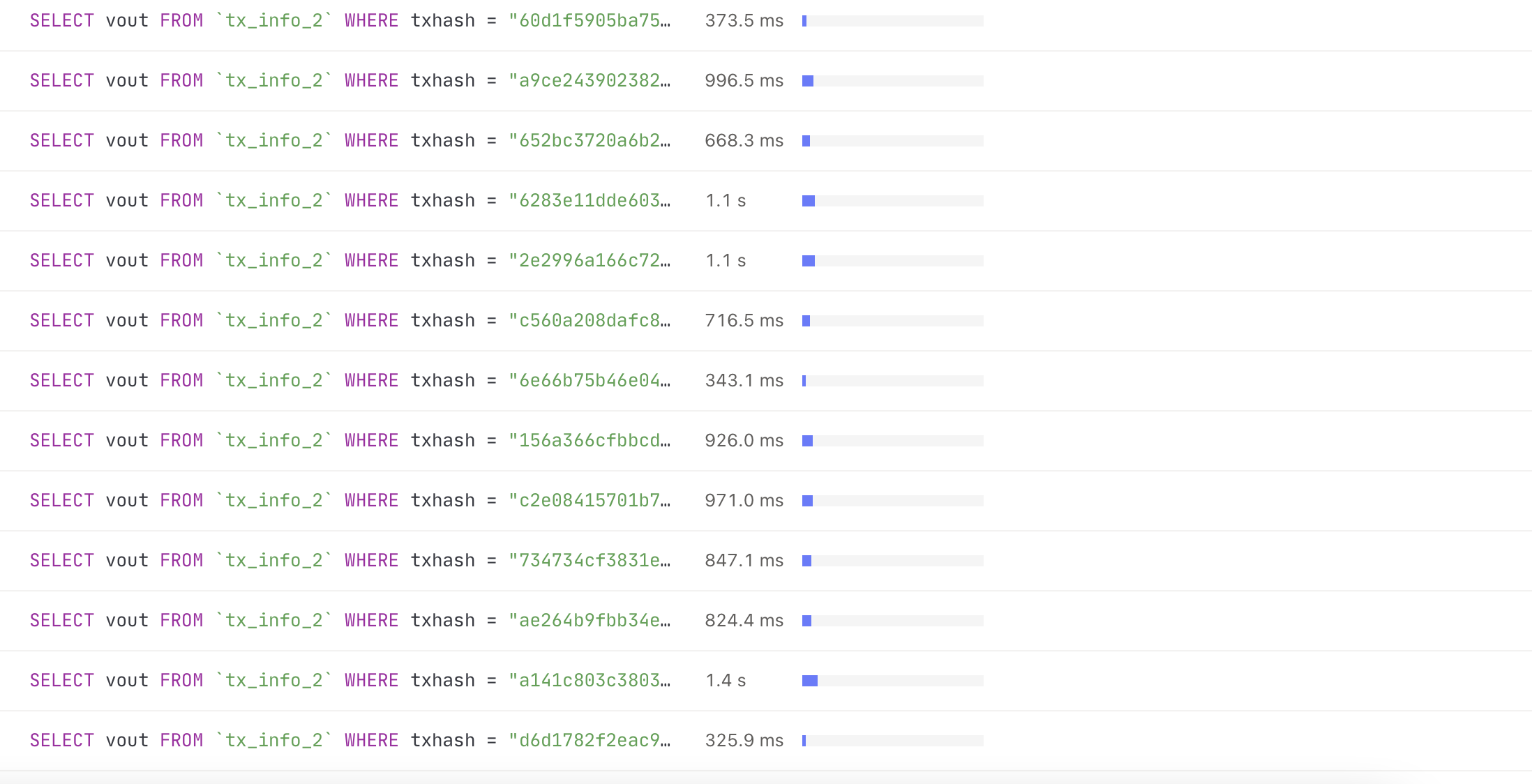
在dashboard中大量查询超时
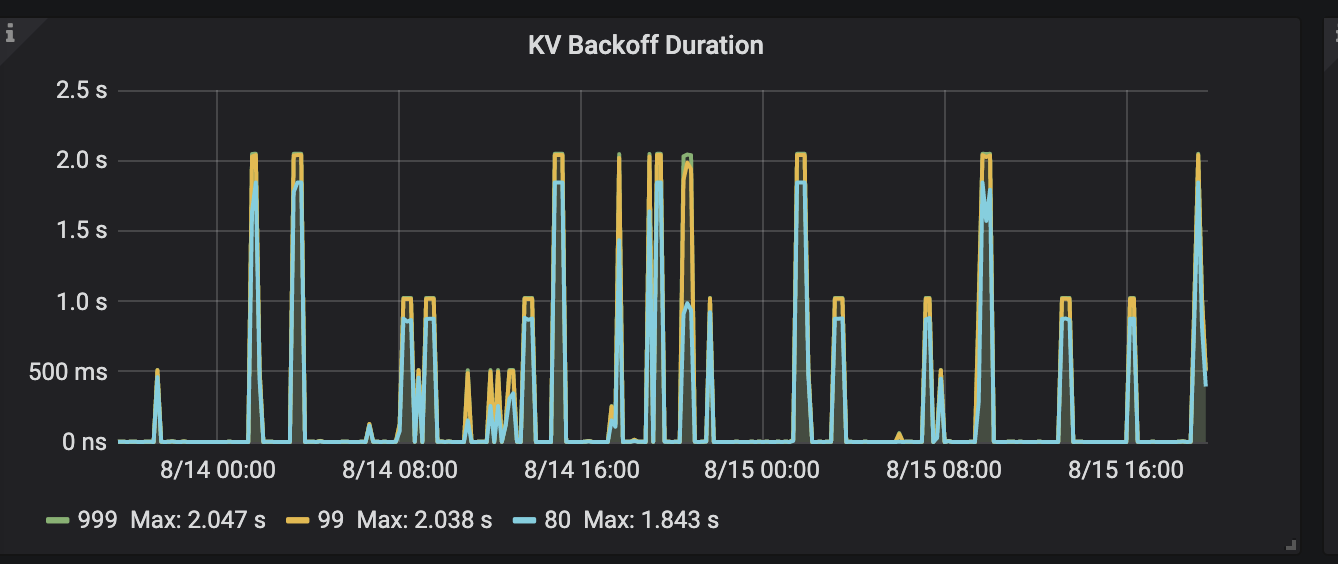
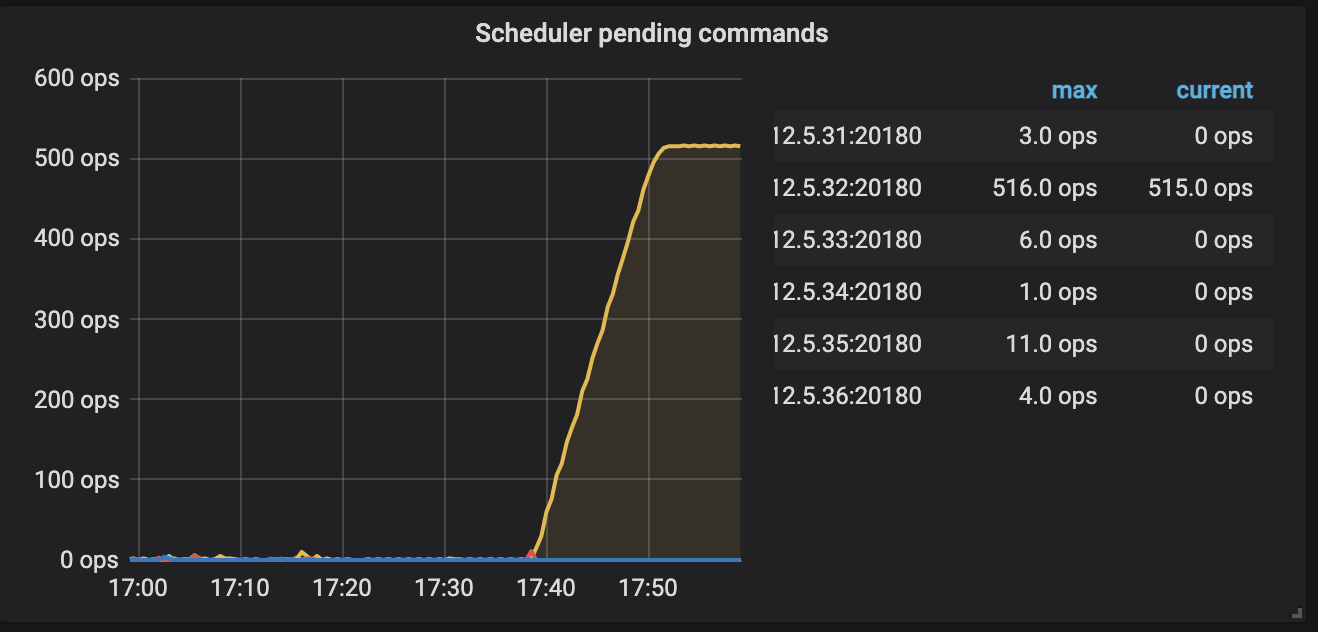
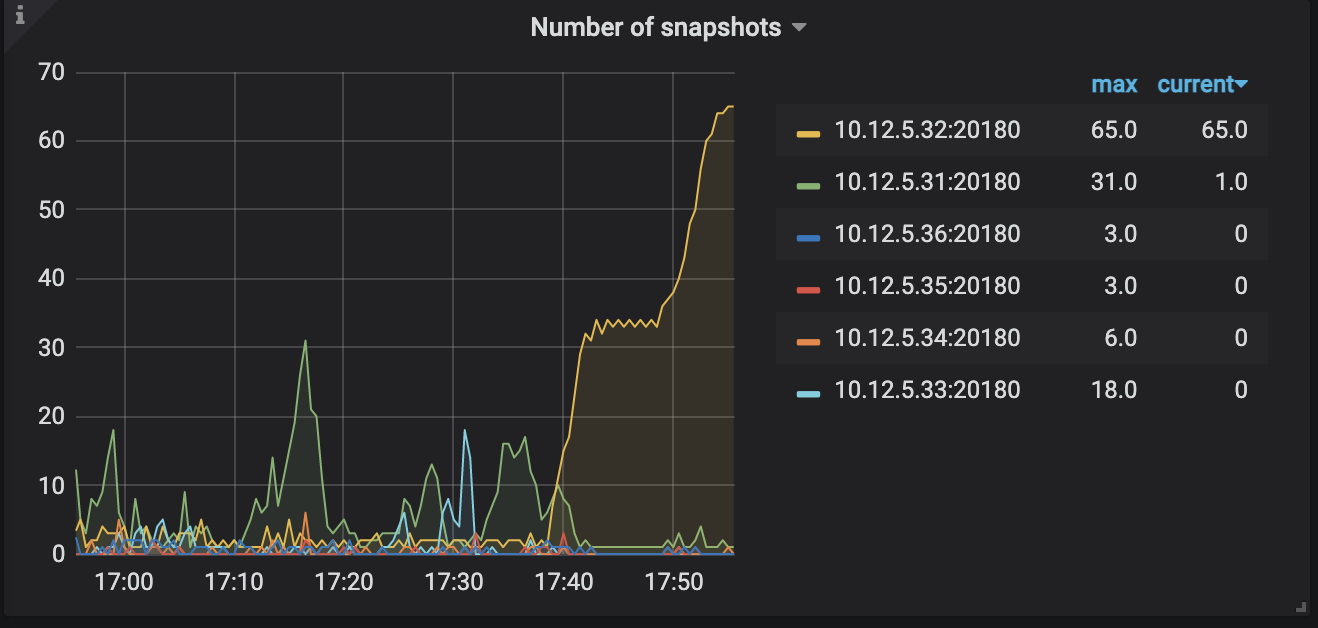
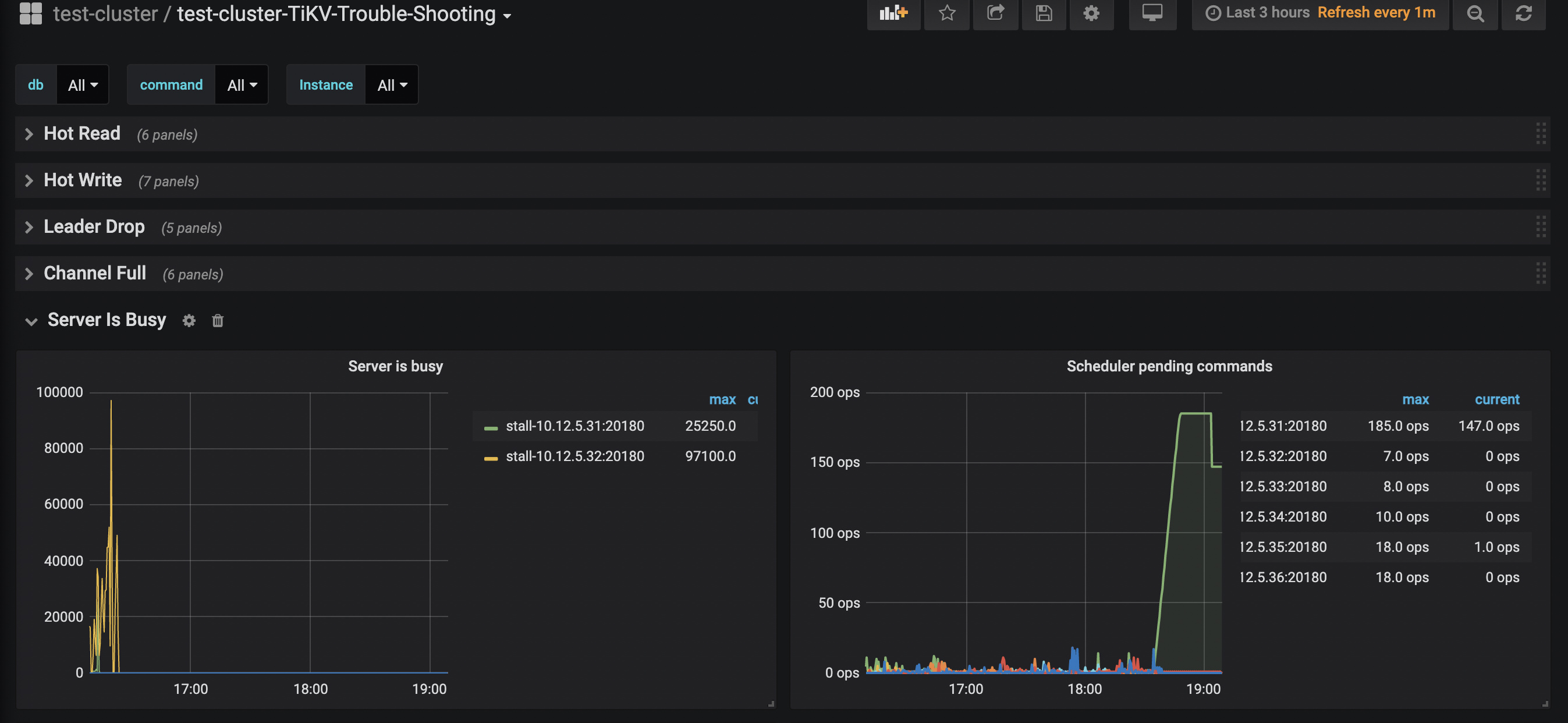
查看granafa server busy,可以看到某个节点大量pending,该时间点与查询超时吻合
以下是31节点日志,烦请帮忙分析一下问题发生原因及解决方案
链接: 百度网盘-链接不存在 密码: r2jj
集群状态全up
麻烦先按照下面这篇文档的方式排查下 server 和 scheduler busy 的问题:
https://docs.pingcap.com/zh/tidb/stable/tidb-troubleshooting-map#43-客户端报-server-is-busy-错误
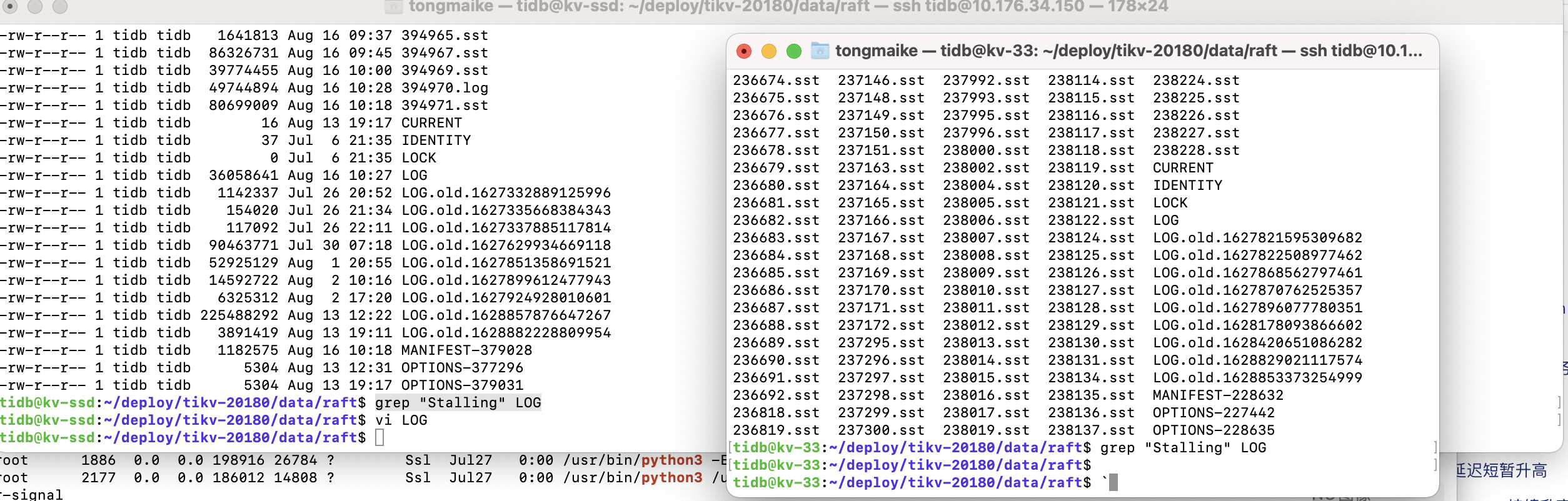
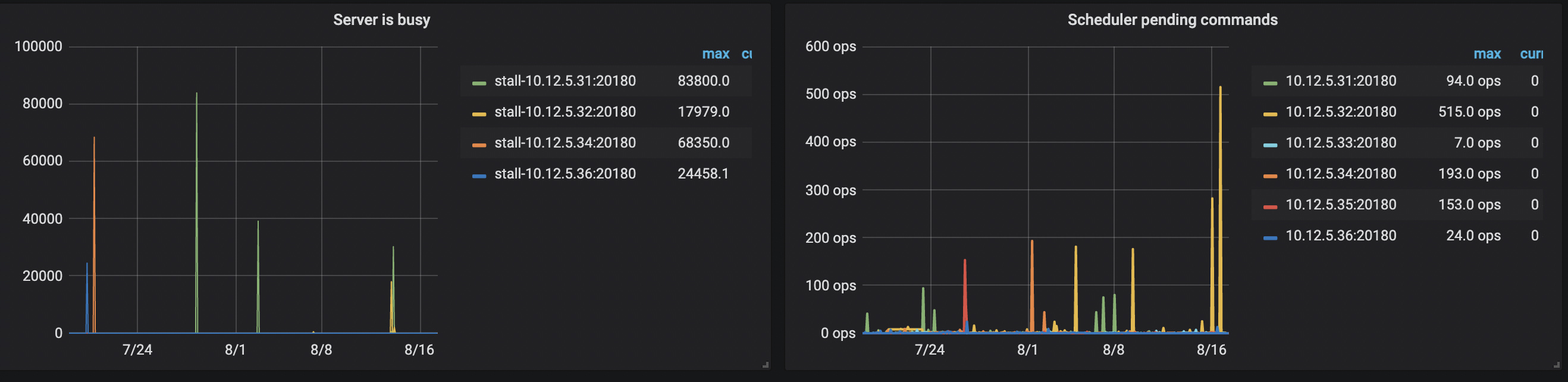
1、server is busy,通过grep命令在两个监控中出现过pending的机器31,33上查看raft日志结果如下
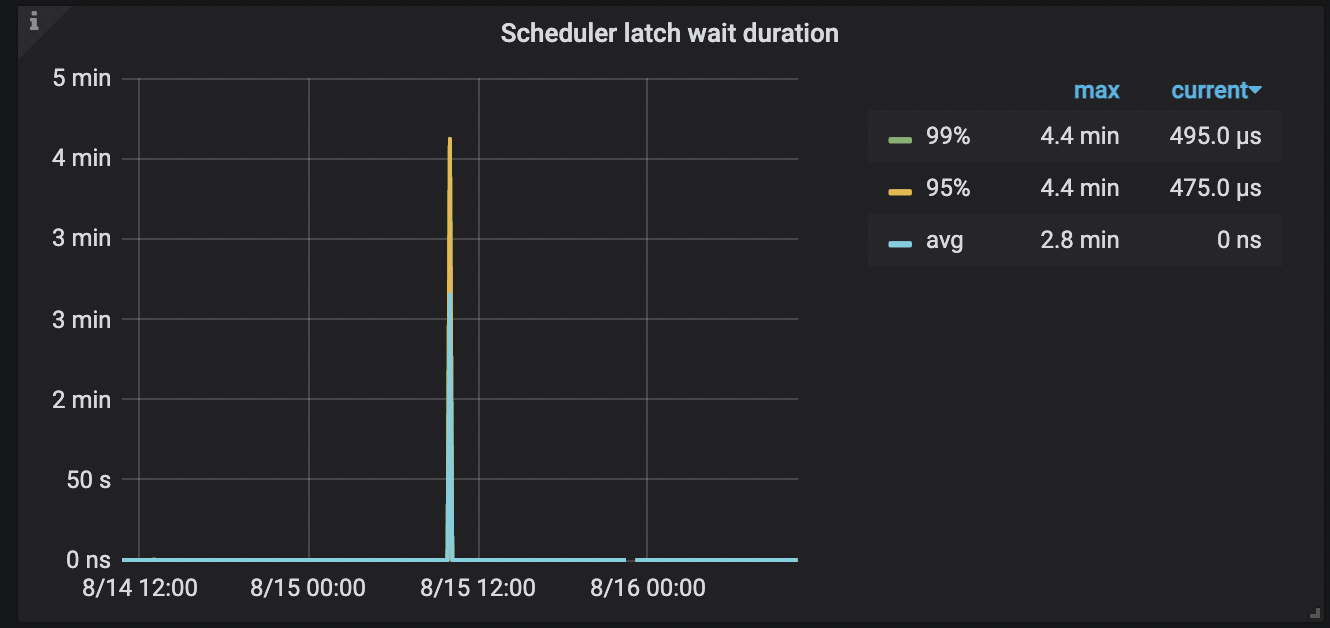
2、scheduler too busy, scheduler prewrite如下
scheduler commit如下
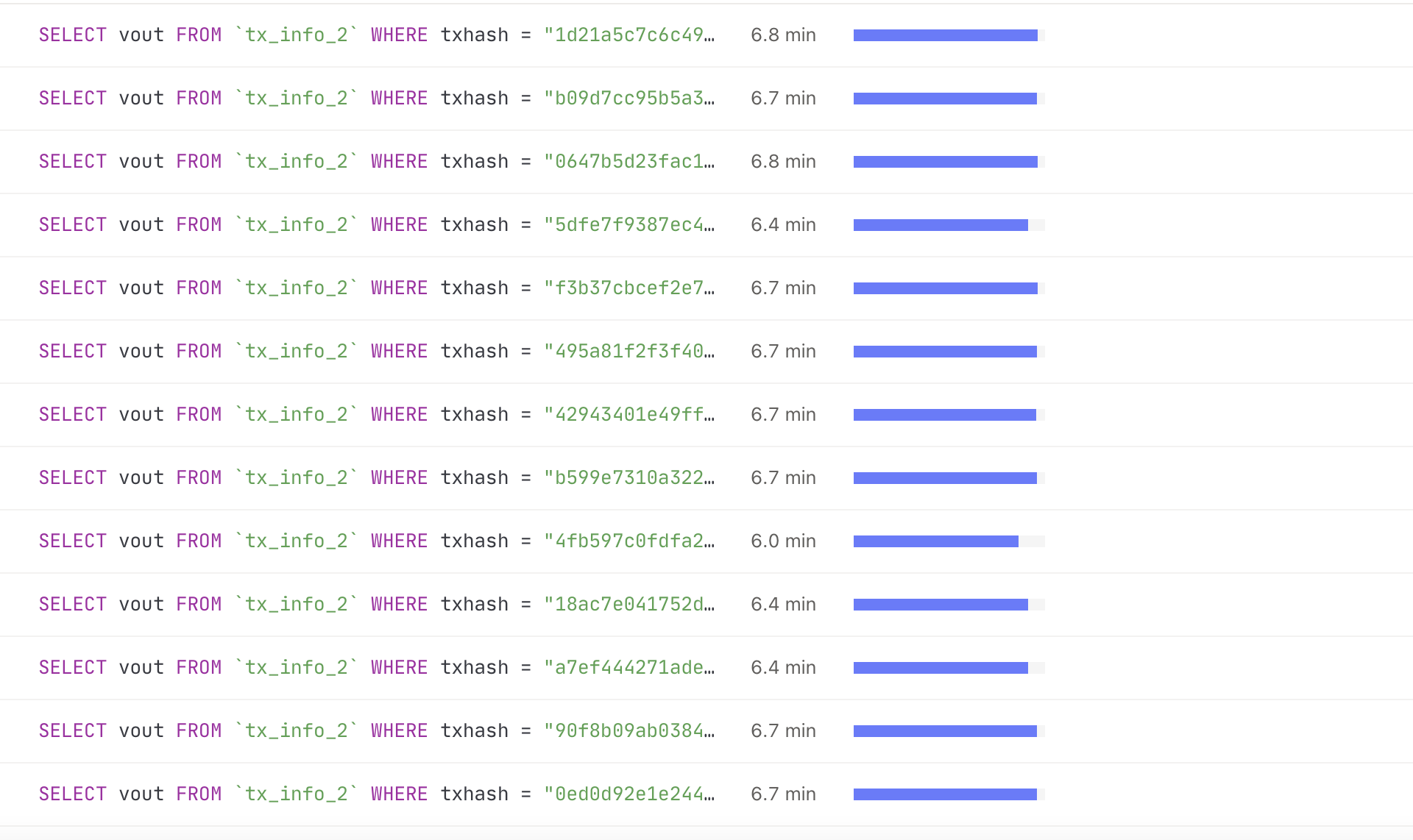
麻烦检查下集群中是否有大量慢 SQL ,如果有的话建议先优化下 SQL
麻烦参考 https://metricstool.pingcap.com/#backup-with-dev-tools ,导出集群 overview/tidb/pd/tikv-details 四个监控面板的数据,选择集群问题比较突出的时间段,并且等页面全部加载出来后导出。
归档.zip (4.3 MB) 归档.zip
选取了近两天内的数据,这其中应该有多次出现问题
从监控中发现 apply log duration/ append log duration 值较高,但相关线程的 CPU 使用率均不高,且 31 这个节点的 IO 使用率一直为 100% ,你这边集群 tikv 的磁盘类型和网络带宽是多少?
麻烦再提供下 31 和 33 这两个节点 Disk-Performance 的监控面板数据,谢谢
31:test-cluster-Disk-Performance_2021-08-16T08_24_49.622Z.json (159.3 KB)
33:test-cluster-Disk-Performance_2021-08-16T08_25_11.513Z.json (159.4 KB)
在31与33节点上进行了文档中的随机读与随机写的fio测试,结果如下
fio_result.zip (7.1 KB) fio_result.zip
将参数 max-snapshot-count 默认值 3 调整为 2 作用不大,目前看到的现象是磁盘性能不佳,请问下这个集群什么会后开始出现这个现象的?
1.建议再按照上面的文档排查下 tikv stall 的原因,根据报错的时间在 tikv 数据子目录 data/raft 和 data/db 分别检索下 LOG 相关日志;
2.如果按照方法 1 调整后还是没有效果,可以考虑扩容下 tikv 节点。
![]() 感觉不用查这么深, 听了dashboard 中 超过 几分钟以上的业务, 这种情况 90%都是慢SQL引起的
感觉不用查这么深, 听了dashboard 中 超过 几分钟以上的业务, 这种情况 90%都是慢SQL引起的
1、在db目录的log日志下有搜到stalling相关记录,而在raft下无相关记录,与https://asktug.com/t/topic/63868状况较为接近,但该帖为write,我们这便是default,请问处理方法是否应该是在edit中添加rocksdb.max-sub-compactions: 4 ?