![]()
![]()
![]()
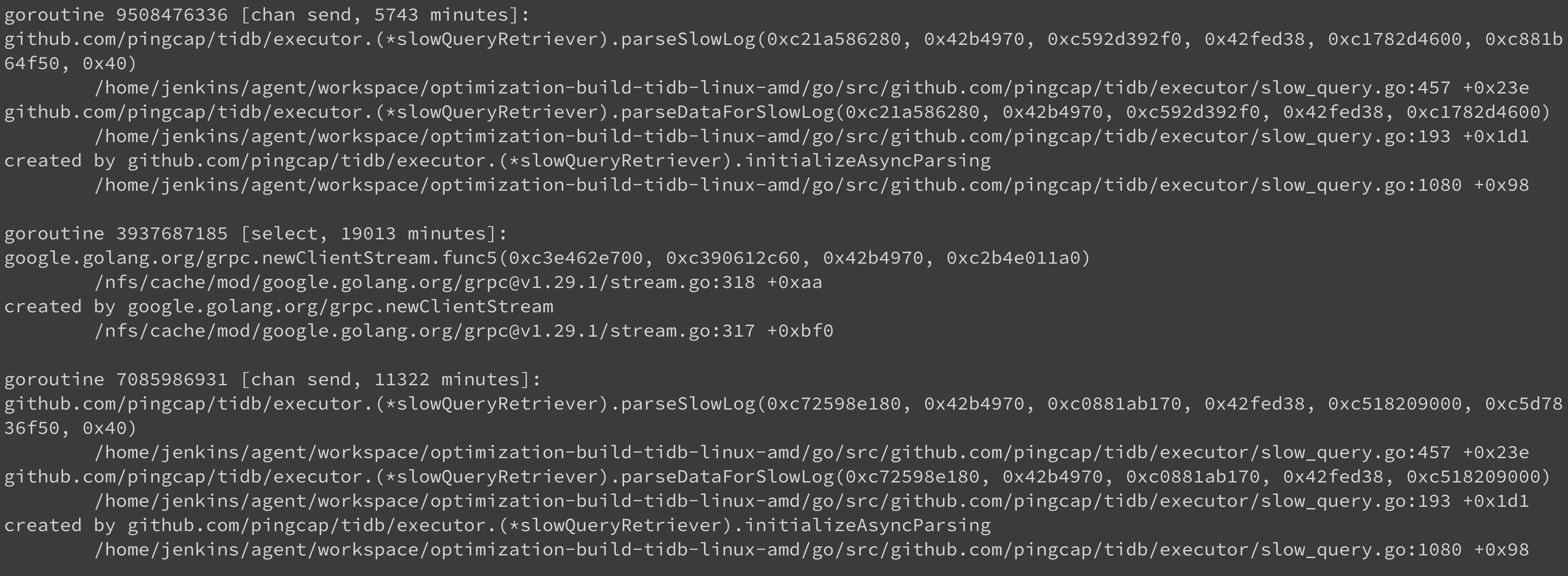
我们仔细分析后,感觉这个 goroutine 应该不正常,里面有数万的运行中的 grpc 连接,部分如下:

图上的时间长的一千多分钟, 短的一两分钟的也有, 完整 groutine 上面 profile.zip 有,这里再单独上传一下:
goroutine.zip (2.2 MB)
这应该是 TiDB 与 TiKV 的 grpc 连接发生了线程泄漏的问题,我们目前没有找到如何配置超时时间,暂时也不清楚触发条件
麻烦再收集一下业务高峰期 7-9 点内存高位时的 profile 信息,另外TiDB 监控中的 Server - Goroutine Count 面板有没有看到持续增长的情况
goroutine 在监控中也是在持续上升:
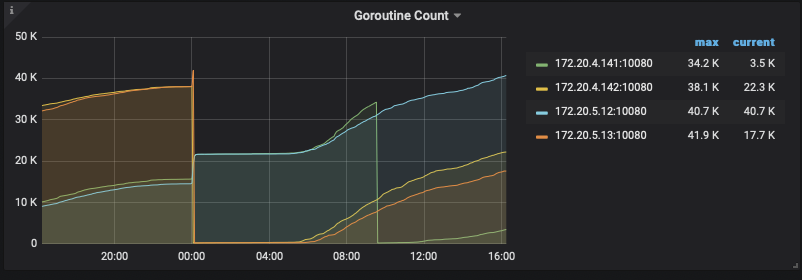
我们目前分析 goroutine,发现卡住的 goroutine 最终都到了 grpc 这里:
goroutine 32574899 [select, 346 minutes]:
google.golang.org/grpc.newClientStream.func5(0xc000792000, 0xc02e28b9e0, 0x38d3be0, 0xc05116b680)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/pkg/mod/google.golang.org/grpc@v1.26.0/stream.go:319 +0xd7
created by google.golang.org/grpc.newClientStream
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/pkg/mod/google.golang.org/grpc@v1.26.0/stream.go:318 +0x9a5
而 stream.go:319 是这样的:
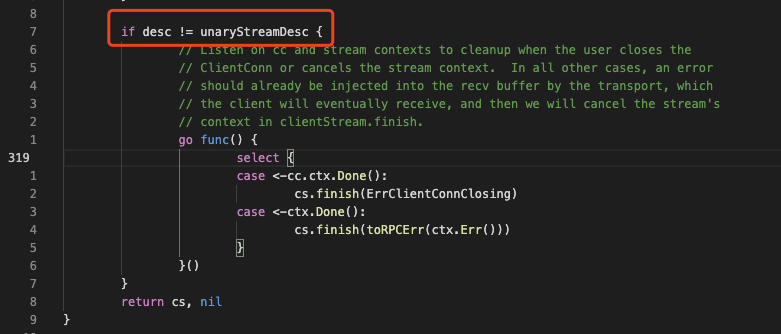
即流式 grpc 才会触发,而这个grpc调用方应该来自 store/tikv/coprocessor.go:
goroutine 32711125 [select, 344 minutes]:
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).sendToRespCh(0xc03d40b5f0, 0xc0a7ff8e10, 0xc0954cd560, 0xc057f17401, 0xc0e3936400)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:687 +0xd2
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).handleCopResponse(0xc03d40b5f0, 0xc02221e080, 0xc0a6be2cd0, 0xc0a7ff8e10, 0x0, 0x0, 0x0, 0x0, 0xc03d3b36c0, 0xc0954cd560, ...)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:1201 +0x60d
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).handleCopStreamResult(0xc03d40b5f0, 0xc02221e080, 0xc0a6be2cd0, 0xc0557326c0, 0xc03d3b36c0, 0xc0954cd560, 0x1008e0, 0x0, 0x0, 0x0, ...)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:1055 +0x16e
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).handleTaskOnce(0xc03d40b5f0, 0xc02221e080, 0xc03d3b36c0, 0xc0954cd560, 0x0, 0xc0e36a0608, 0x11baeab, 0xc038414508, 0x0)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:902 +0x676
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).handleTask(0xc03d40b5f0, 0x38d3be0, 0xc053231aa0, 0xc03d3b36c0, 0xc0954cd560)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:808 +0x1aa
github.com/pingcap/tidb/store/tikv.(*copIteratorWorker).run(0xc03d40b5f0, 0x38d3be0, 0xc053231aa0)
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:538 +0xeb
created by github.com/pingcap/tidb/store/tikv.(*copIterator).open
/home/jenkins/agent/workspace/optimization-build-tidb-linux-amd/go/src/github.com/pingcap/tidb/store/tikv/coprocessor.go:580 +0x99
但在 coprocessor.go 我们没有找到初始化 rpc 调用的代码,怀疑的代码来源: store/tikv/client.go 392-427:
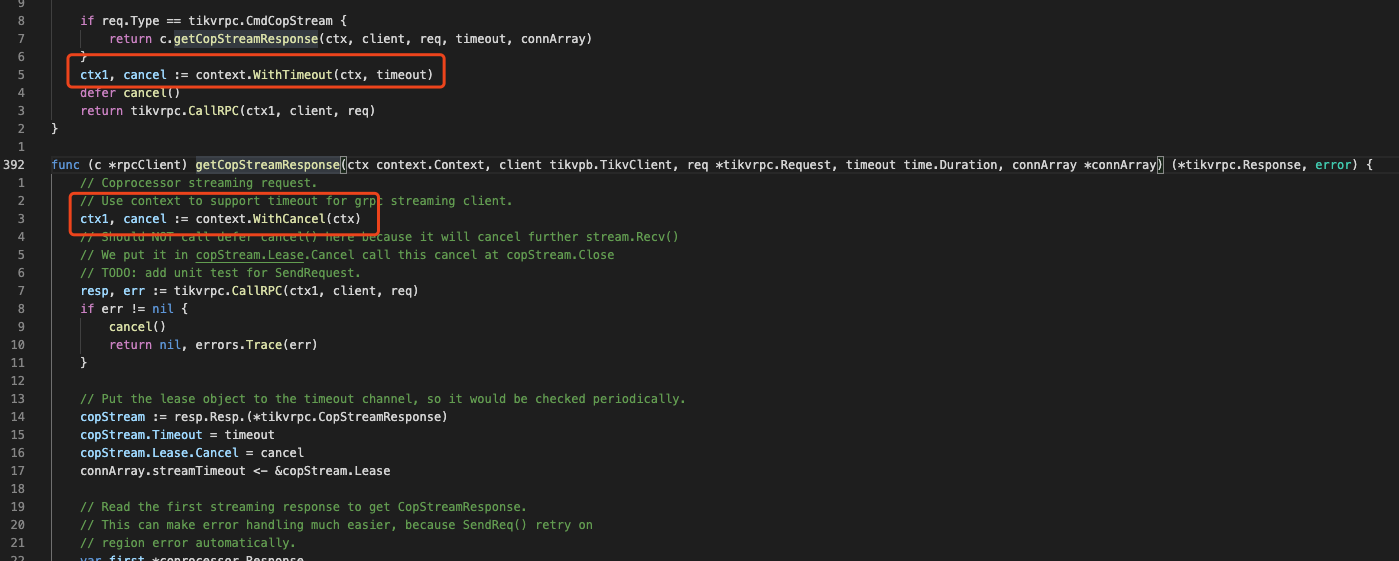
如图所示, getCopStreamResponse 没有像普通 unary 一样使用 context.WithTimeout, 而是没有超时时间的 context.WithCancel, 而 timeout 参数则用在了下面的 copStream 对象,这个对象的作用我们目前还搞不清楚。
以我们目前的能力再深入分析难度就很大了,我不清楚这里有没有 PingCAP 的 QA或研发人员? 这个问题应该是可重现的,只要我们设置较小的内存并多次执行 Stream 统计就可以复现。
2 个赞
@OldJack 您好,方便发下您第一次开这个问题抓 profile 时,那一天(24小时 )的 TiDB 日志吗?如不方便公开,您可以发我邮箱 chenshuang@pingcap.com 或者加我微信发我: crazycs2015
多谢回复, 我们在分析确认是 streaming 导致的问题后, 发现我们有在配置文件中开启 enable-streaming: true, 把这个选项关闭到现在差不多30多小时,内存占用基本在300M以内,现在看来效果还不错。
但这个 enable-streaming 选项在文档中好像找不到了,不再支持了吗?那是不是要考虑忽略配置文件这个参数?
关于日志,因我们tidb部署在k8s集群中,目前只做了 slowlog 日志收集,tidb应用日志在重启后就会丢失,所以我只下载到重启后一段时间的日志, 如有需要我发您邮箱。
2 个赞
麻烦发我邮箱我查下吧
@OldJack. 您好,已经定位到问题了。确定是因为在设置 enable-streaming = true 后, 如果查询使用的内存超过 mem-quota-query 被 cancel 后,就可能会导致 goroutine 以及 内存泄漏。
临时绕过的方案是设置 enable-streaming = false。
enable-streaming 这个配置再 master 上已经是废弃状态了,不建议开启。
master已经废弃,是指5.0及之后的版本都废弃了么?
准确来说,是从 5.2 版本开始,enable-streaming 配置开始是废弃状态。
收到![]()
这个坑有点深 ![]()
等5.5以后再上车吧~
1 个赞
goroutine/memory leak when streaming query been cancelled · Issue #27353 · pingcap/tidb (github.com)
您好 请问一下 5.4版本 的怎么办?
这个看上去是另一个查询 cluster_slow_query 导致的问题
5.4 版本应该没有 enable-streaming 导致内存泄漏的 bug 了
我发现我的4.0.6版本,在做dumpling的时候,tidb.log里面有如下报错: [“wait response is cancelled”] [to=xxx.xxx.xxx:20161] [cause=“context canceled”]
是不是就是你说的bug呢?