【TiDB 使用环境】测试
每天入库数据量在1000万+,相比与小数据量的情况,发现tikv节点每天重启,上图是tikv的内存利用率,发现重启时间点和内存达到最高点时间点吻合,怀疑存在内存泄漏。
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
日志如下,-p的是重启前日志
log.zip (11.0 MB)
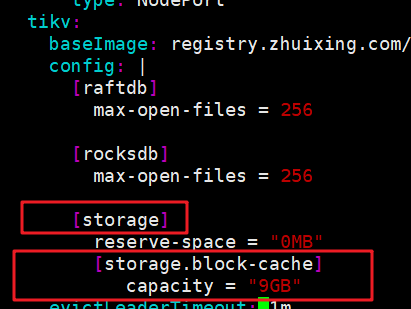
storage.block-cache.capacity 设置下tikv内存
2 个赞
tikv有和其他组件混布吗,如果独立部署应该不至于被OOM
xfworld
2025 年6 月 22 日 03:07
4
升级下小版本,会有一些问题的修复,升级完成之后会有明显改善了
在相同命名空间下只有tidb,同个服务器上还有部署milvs数据库,还有s3等其他组件
k8s安装的tidb集群,一定要注意,SHOW config WHERE NAME LIKE ‘%storage.block-cache.capacity%’;—这个tikv参数不指定的话,是根据你的宿主机物理内存来自动分配的,storage.block-cache.capacity= ‘9GB’;
2 个赞
lllzd
2025 年6 月 24 日 02:42
12
特别关注以下几个关键指标, ikv_thread_mem_profile 显示各个线程的内存使用情况,process_resident_memory_bytes 进程占用的物理内存大小。ikv_grpc_msg_duration_seconds_bucket{type=“kv_prewrite”} 和其他类似的gRPC请求延迟指标,以检测是否有异常增加的延迟可能暗示内存问题。
1 个赞
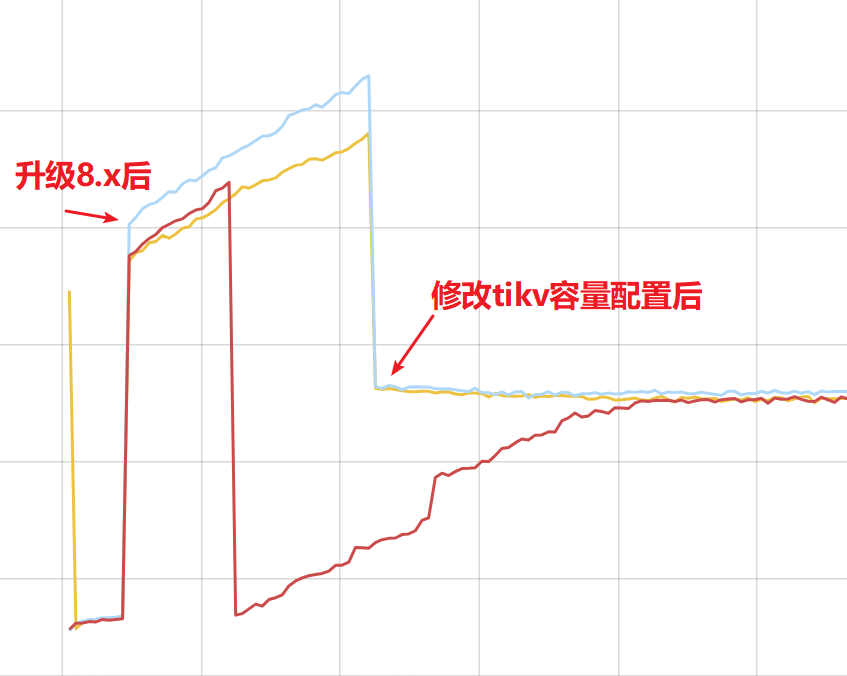
测试之后,升级8.x之后还是会内存利用率增长,但是修改配置之后就稳定了,目前观察一天没有出现pd重启现象,感谢
1 个赞
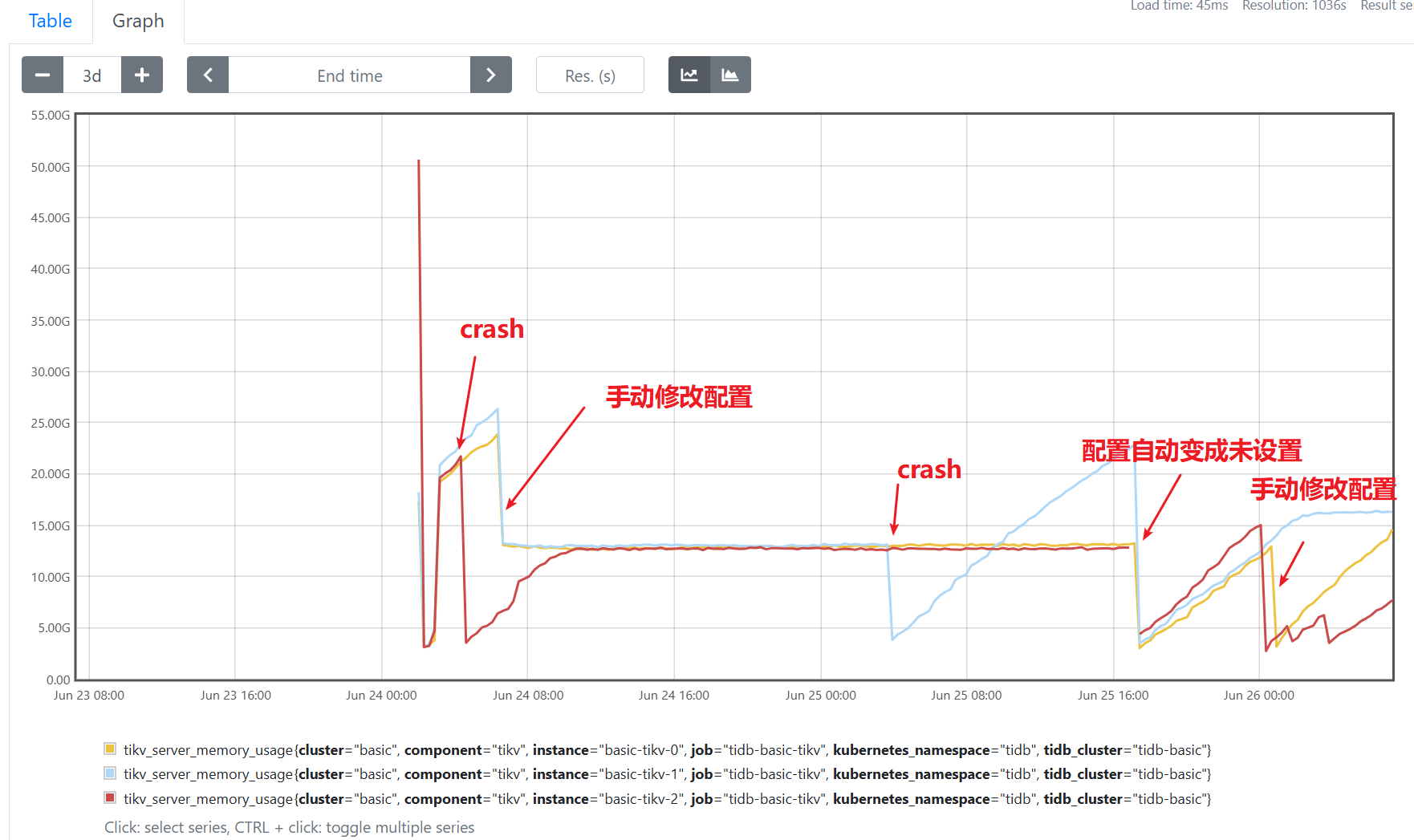
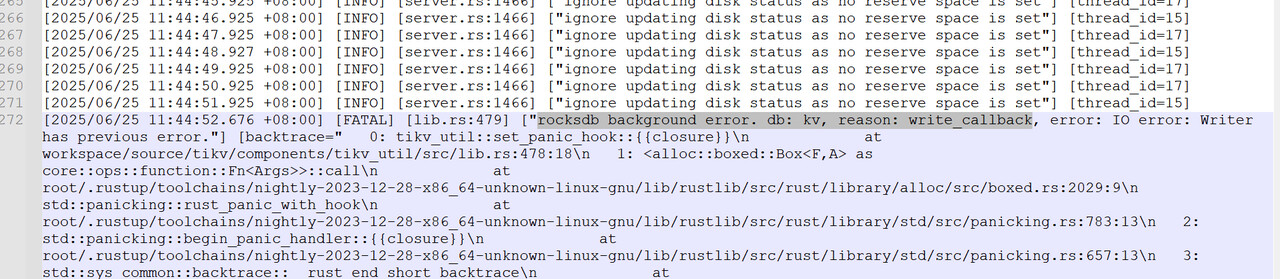
请教下,在修改后一天左右出现tikv组件crash报错,组件自动重启后看内存利用率又变为自动增长的,在26号凌晨0点52三个tikv组件都重启了,已重启多次看不到是否是crash,这个时间点后看配置恢复成不指定的情况了,有没有设置全局配置可以持续生效。另外crash的原因和这个设置有关吗?
上图内存利用率的时间轴为utc时间。
crash报错日志如下
basic-tikv-1-p.txt (3.0 MB)
system
2025 年7 月 4 日 03:53
20
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。