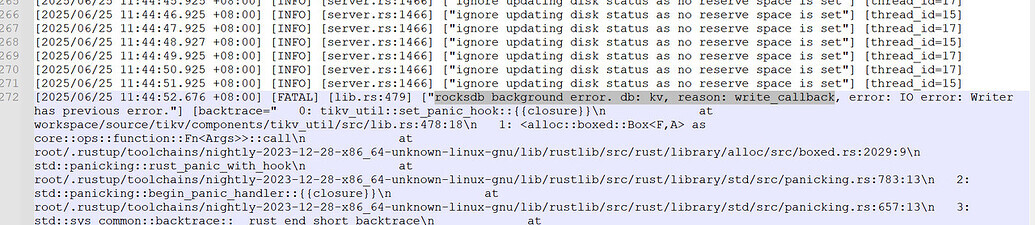
【TiDB 使用环境】测试tikv内存泄漏 - TiDB 的问答社区 】从6.5.0升级至8.5.0后,开始出现tikv的crash,日志如下
期间手动修改tikv配置控制内存增长 SET config tikv
storage.block-cache.capacity = ‘9GB’;
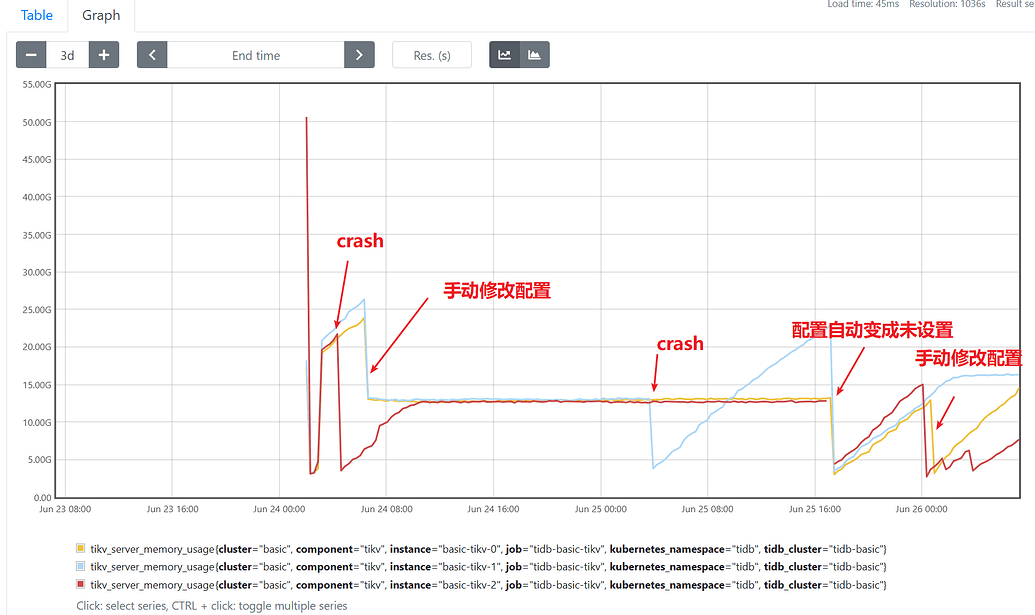
但crash重启后配置重新初始化,期间几次crash重启,在6.5.0版本中未出现crash现象,只是内存增长到一定阶段日志无异常重启
上图内存利用率的时间轴为utc时间
【遇到的问题:问题现象及影响】
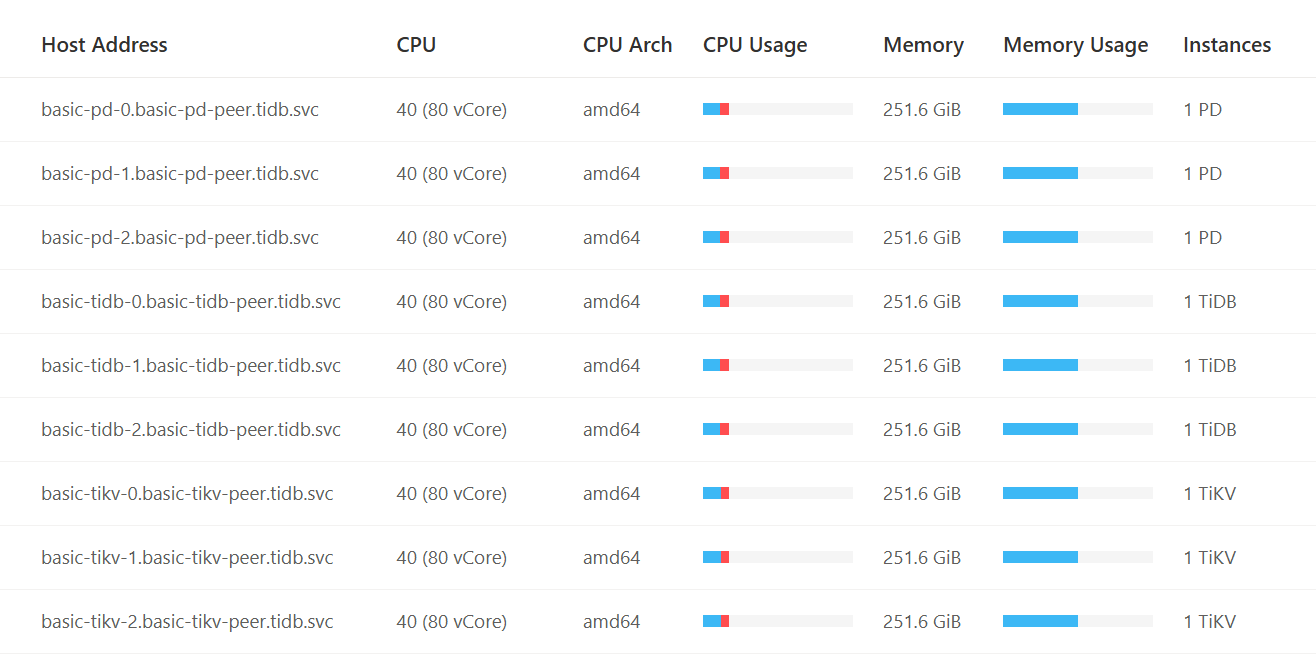
【资源配置】
【复制黏贴 ERROR 报错的日志】
log0626.zip (8.2 MB)
【其他附件:截图/日志/监控】
为什么不升级到8.5.2了,8.5.2修复了很多bug
另外 你这case大概率也是bug,可以完整的把panic日志贴出来,让大佬们分析分析是哪个bug
basic-tikv-0-p.txt (48.3 MB)
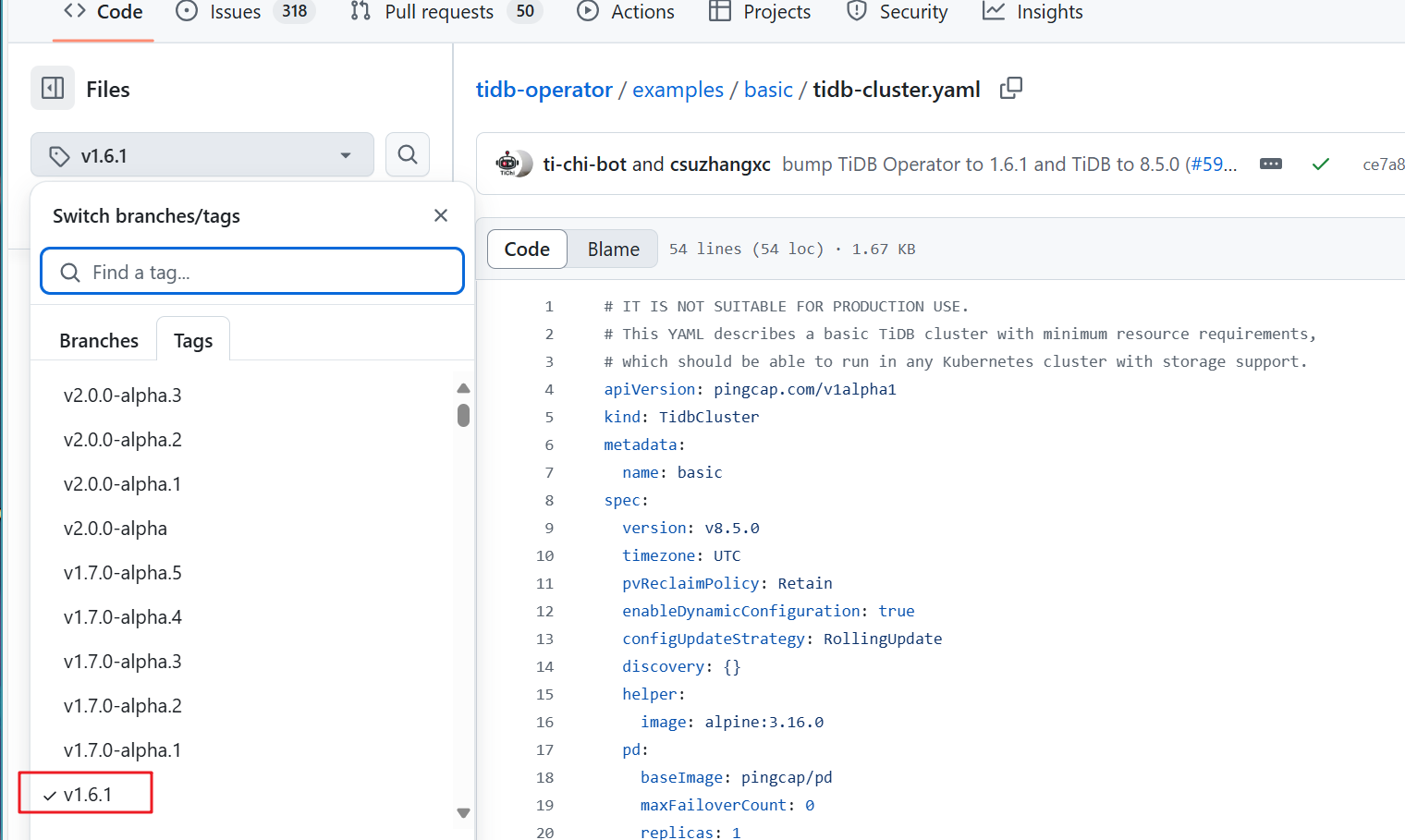
因为我用的是k8s集群,看官网上
yaml例子中1.6.1正式版本中组件镜像是8.5.0,因此升级了这个版本,我试试升级8.5.2
请问下要升级8.5.2的话,这些组件对应的镜像版本要在哪里查询?
lllzd
2025 年6 月 27 日 03:35
7
rocksdb background error. db: kv, reason: write_callback, error: IO error: Writer has previous error. 这表明RocksDB在后台执行写操作时遇到了IO错误。
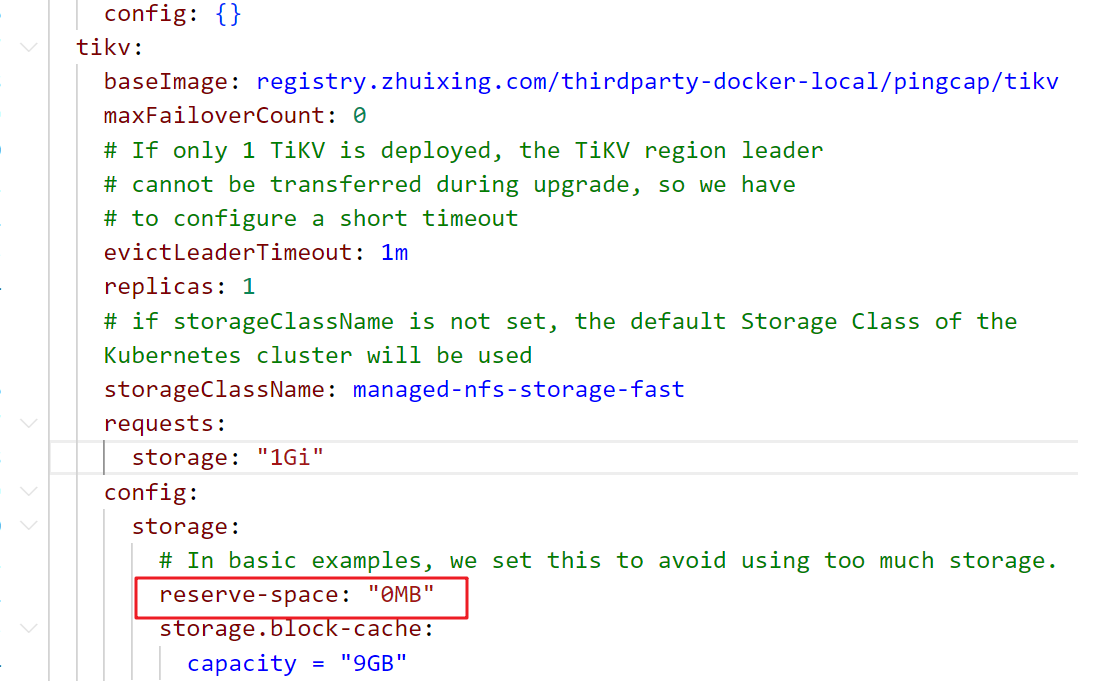
和配置里这个reserve-space: "0MB"有关吗?如果有关正确的值是要怎么设置?
当时看了服务器总的磁盘空间,挂载盘使用了70+%左右
请问下怎么升级到8.5.2
有猫万事足
2025 年6 月 30 日 09:21
12
cur_kv_disk_status,
separated_raft_mount_path,
available,
snap_size,
kv_size,
raft_size,
capacity
);
}
// Update disk status if disk space checker is enabled.
if reserve_space == 0 && reserve_raft_space == 0 {
info!("ignore updating disk status as no reserve space is set");
} else {
disk::set_disk_status(cur_disk_status);
}
// Update disk capacity, used size and available size.
disk::set_disk_status(cur_disk_status);
disk::set_disk_capacity(capacity);
disk::set_disk_used_size(used_size);
disk::set_disk_available_size(available);
只有resever-space=0是不会显示这个日志的,还需要reserver_raft_space=0。
但是你的日志里面有,config的完整配置,可以搜到
"reserve-space":"0KiB","reserve-raft-space":"1GiB"
所以,你单独配置reserver-space=0并不是疯狂显示这条日志的原因,起码是因为
reserver-space=0而且reserve-raft-space=0.
有猫万事足
2025 年7 月 1 日 02:22
14
有几个特别奇怪的地方。
首先是你说磁盘其实没满,只有70%的用量。但是日志上的提示,给我的感觉一直是没法写入了。
[2025/06/26 09:31:59.431 +08:00] [INFO] [server.rs:1466] [“ignore updating disk status as no reserve space is set”] [thread_id=16]
这个就不说了。最后tikv0,tikv1那个fatal错误也是io错误。
我感觉这个磁盘不像是本地盘,可能是依赖网络的存储,比如nfs/s3这种。当网络卡的时候,可能导致短时的不能读写。就有上面这种报错。而且tikv0,tikv1的日志都提到,当他们出现fatal错误前,已经不能通过网络访问tikv2的。所以我感觉是当时tikv2因为某些原因已经是没法访问了。(tikv2的日志时间不包括1点左右的,所以具体我也不清楚tikv2当时发生了什么)。
顺着这个思路得到的结论就是网络有问题,导致tikv2不能访问,nfs/s3这类存储也不能访问了。然后tikv0和tikv1就报fatal错误退出了。
确实是使用的nfs,挂载的本服务器上的固态硬盘,当时是看的固态盘磁盘利用率大概70%左右,可能nfs存在网络问题导致写入失败了,目前已经回退至6.5.0版本,然后清理了磁盘空间(利用率在50%)在观察中
1 个赞
数据库对网络和硬件要求较高,尤其是真正的分布式数据库