kkpeter
(Upstream889)
1
【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.1
【操作系统】rockylinux 9
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)
【集群数据量】400
【集群节点数】3kv/3tidb
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
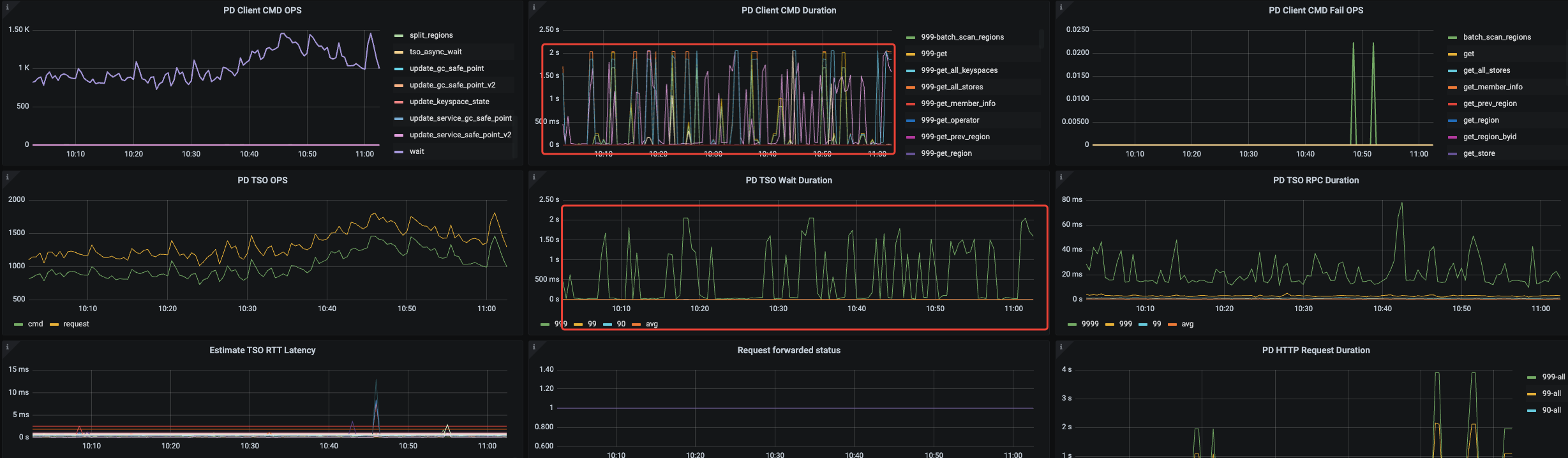
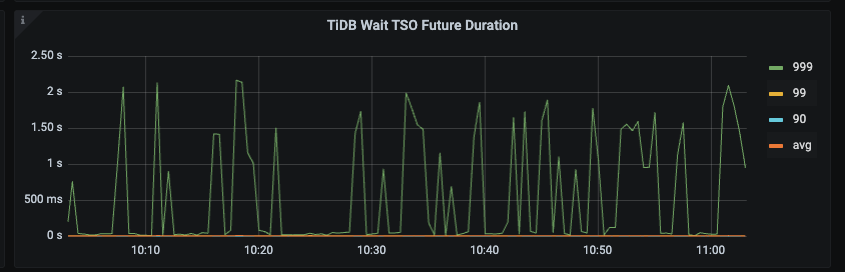
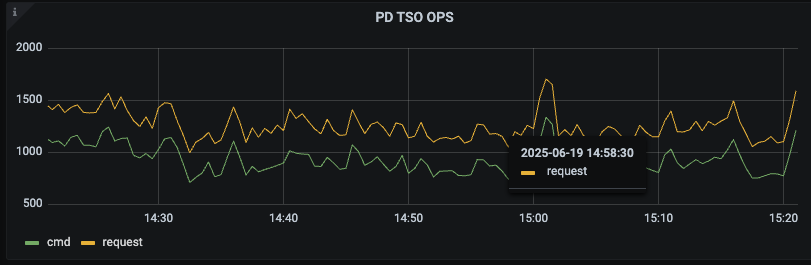
问题现象, TiDB 的 PD Client面板中(PD TSO Wait Duration)指标延迟很高
其他TiDB, PD,TiKV 的cpu/内存/网络/磁盘等等全都排查过没有什么异常
问题影响:
系统中有慢sql执行时间达到1s多,大部分耗时在获取pd tso
尝试过的操作:
- 调整TiDB set global tidb_tso_client_batch_max_wait_time = 2;
- 调整PD tso-update-physical-interval = 25ms
- 调整PD 打开 tidb_enable_tso_follower_proxy
- 依次重启了所有TiDB节点
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
TiDB 节点会有一些报错日志, 搜素历史最后都是说不影响集群就可以忽略。
【其他附件:截图/日志/监控】
nobody
(不定时出现)
3
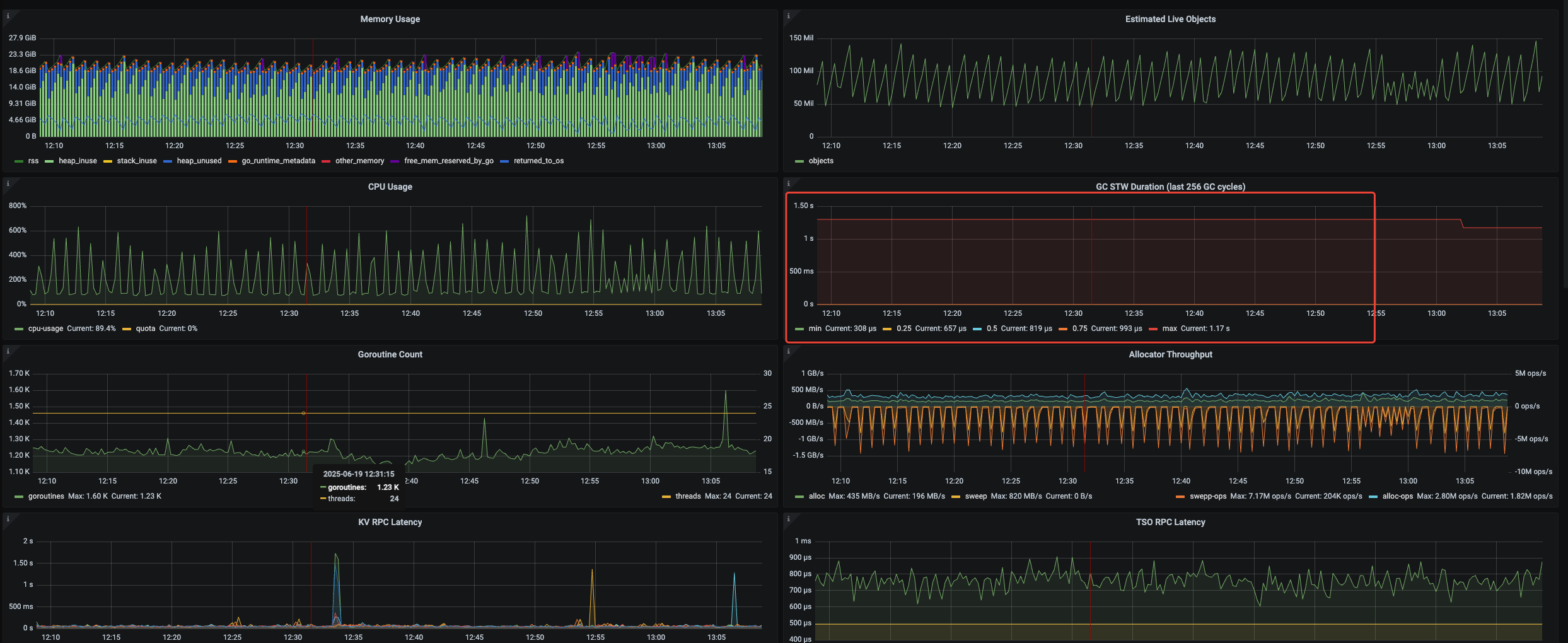
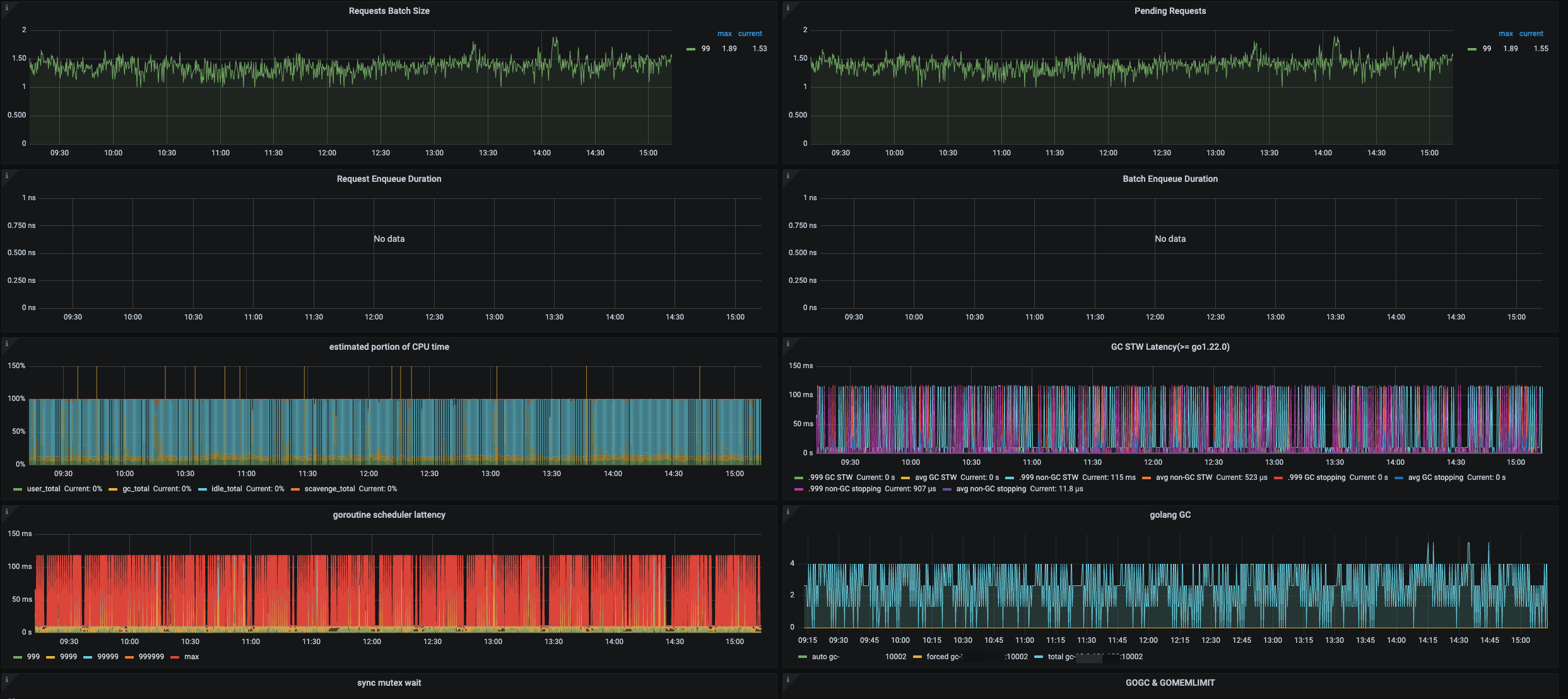
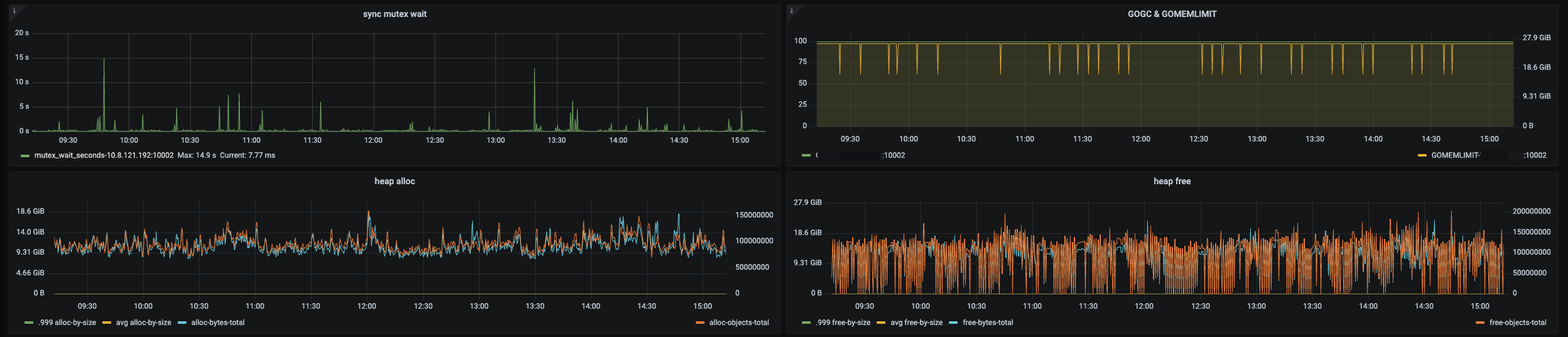
看下 grafana tidb-runtime 监控,tidb-server 内存看着不太正常
nobody
(不定时出现)
5
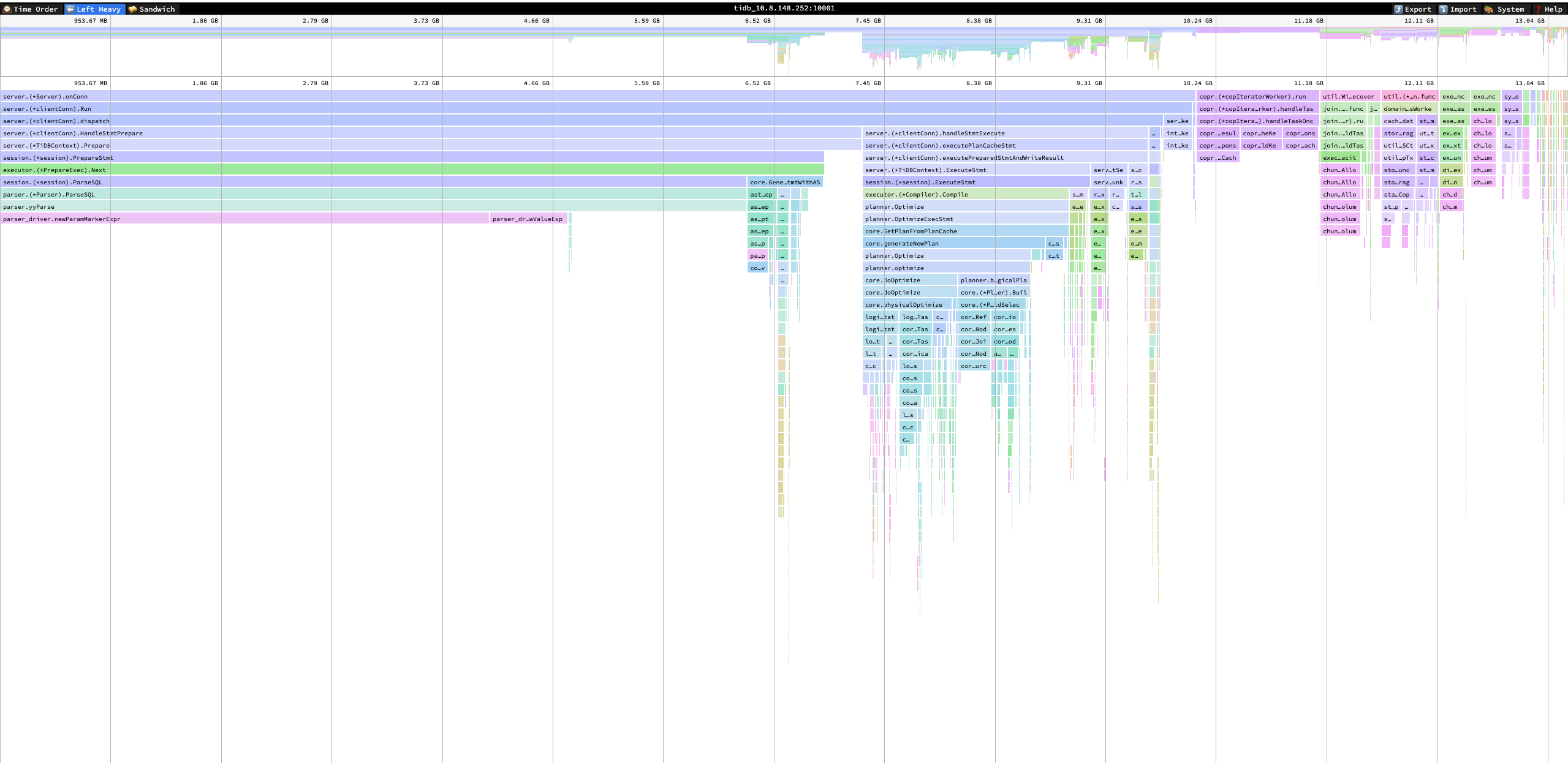
能抓个 tidb 内存 heap 出来吗?看起来 go gc 的压力非常大
kkpeter
(Upstream889)
7
nobody
(不定时出现)
8
你的业务里 sql 是带非常多值的,比如 in (…) 或者 insert multi values?看起来主要是解析 sql 的时候内存用的比较多
nobody
(不定时出现)
10
大概看下来是业务侧 sql 占用的内存比较多,然后导致内存使用率较高,持续触发 tidb 的 gogc 动作回收内存。gogc 类似 java gc ,gogc 延迟较大,进而影响了 tidb 侧 tso 的获取。
可以收集下如下信息:
curl 127.0.0.1:10080/metrics | grep -E “procs|gogc”
ps: 127.0.0.1:10080 替换成你的 tidb-server 的 ip:status_port
kkpeter
(Upstream889)
13
看了下监控,TiDB的GC耗时 是MAX 1s,并不是持续1s的耗时, 而且TiDB节点内存使用率只有70%,应该不是这个原因吧
nobody
(不定时出现)
14
那个指标是指最近 256 次 gogc 的最大延迟,这 256 次 gogc 的延迟有可能也会存在比较大的延迟的可能的
nobody
(不定时出现)
15
tidb runtime 监控的其他面板也发一下看看吧