tidb版本 4.0.13
最近半个月反复触发TiKV_scheduler_latch_wait_duration_seconds告警,跟业务确认,业务侧没任何改动变更。

根据上图的提示看了对应的监控,发现Scheduler command duration和Scheduler latch wait duration都好几秒,感觉有点不正常。

但是看了一下几个tikv节点的机器负载,几乎没啥负载。

最近一个月的io情况也没明显异常

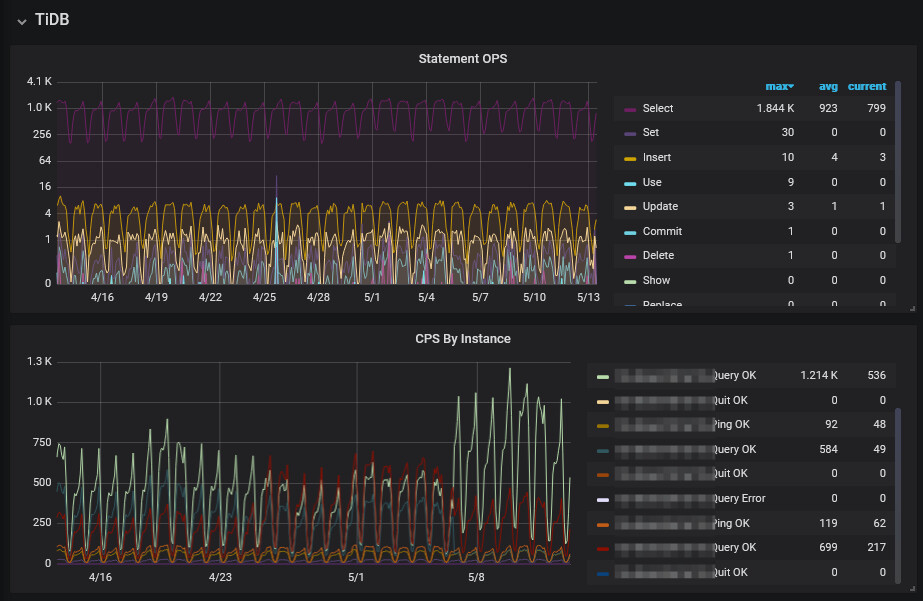
qps情况
tidb版本 4.0.13
最近半个月反复触发TiKV_scheduler_latch_wait_duration_seconds告警,跟业务确认,业务侧没任何改动变更。
根据上图的提示看了对应的监控,发现Scheduler command duration和Scheduler latch wait duration都好几秒,感觉有点不正常。
但是看了一下几个tikv节点的机器负载,几乎没啥负载。
最近一个月的io情况也没明显异常
qps情况
scheduler_latch 等待时间长,说明写入的慢,你看看 raft apply 的时间和 rocksdb 的 wal 写入时间。看看压力大不大?如果纯粹是latch等待时间长,后面没多大压力,可以试着调大 scheduler 线程池。
1、看下 gc 是否有异常
2、每个 tikv region 数量有没有很多。
latch wait 延迟抖动和告警,通常是 tikv 写入延迟(async write) 抖动的结果和现象。
建议参考 https://docs.pingcap.com/zh/tidb/stable/latency-breakdown/ 排查相应 tikv 写入延迟问题。
此外 v4.0 版本比较老,建议尝试最新 TiDB release 版本
也可参考这篇帖子进行tikv async write抖动的排查:TiDB 写入慢流程排查系列(四)— TiKV Server 写入流程 - #7,来自 GangShen