【TiDB 使用环境】生产环境
【TiDB 版本】v8.5.1
【操作系统】Linux
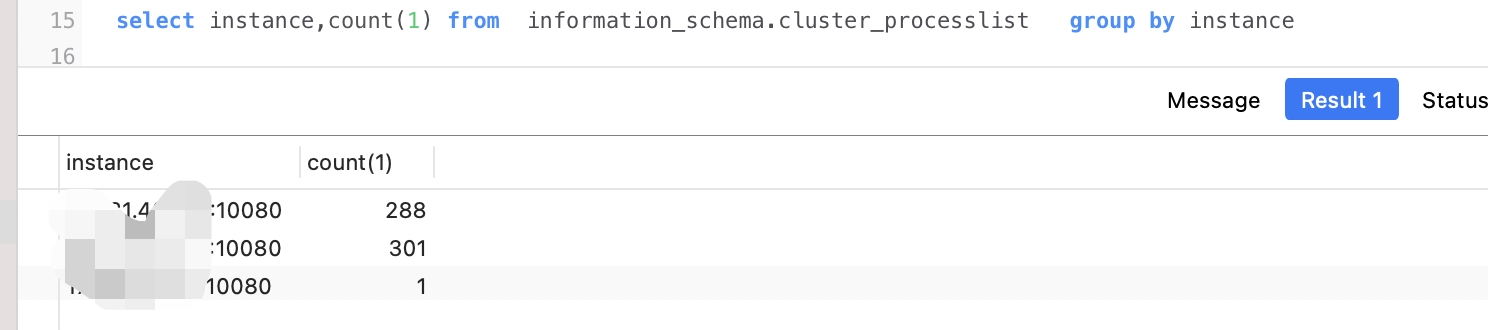
【部署方式】AWS tiup部署,使用LB负载转发给3个tidb 4000端口,负载方式是: 轮询。
【集群数据量】300~500G
【集群节点数】3个tidb/pd(tidb与pd在一个节点)、3个tikv、3个tiflash
【问题复现路径】曾经5个tidb/pd节点,下线两个节点。看图表是下线后出现某个tidb内存会不断增高,一直到当前机器的80%被OOM。后来剩下的3个tidb节点内存、CPU都升级过一波(目前16C 64G)。
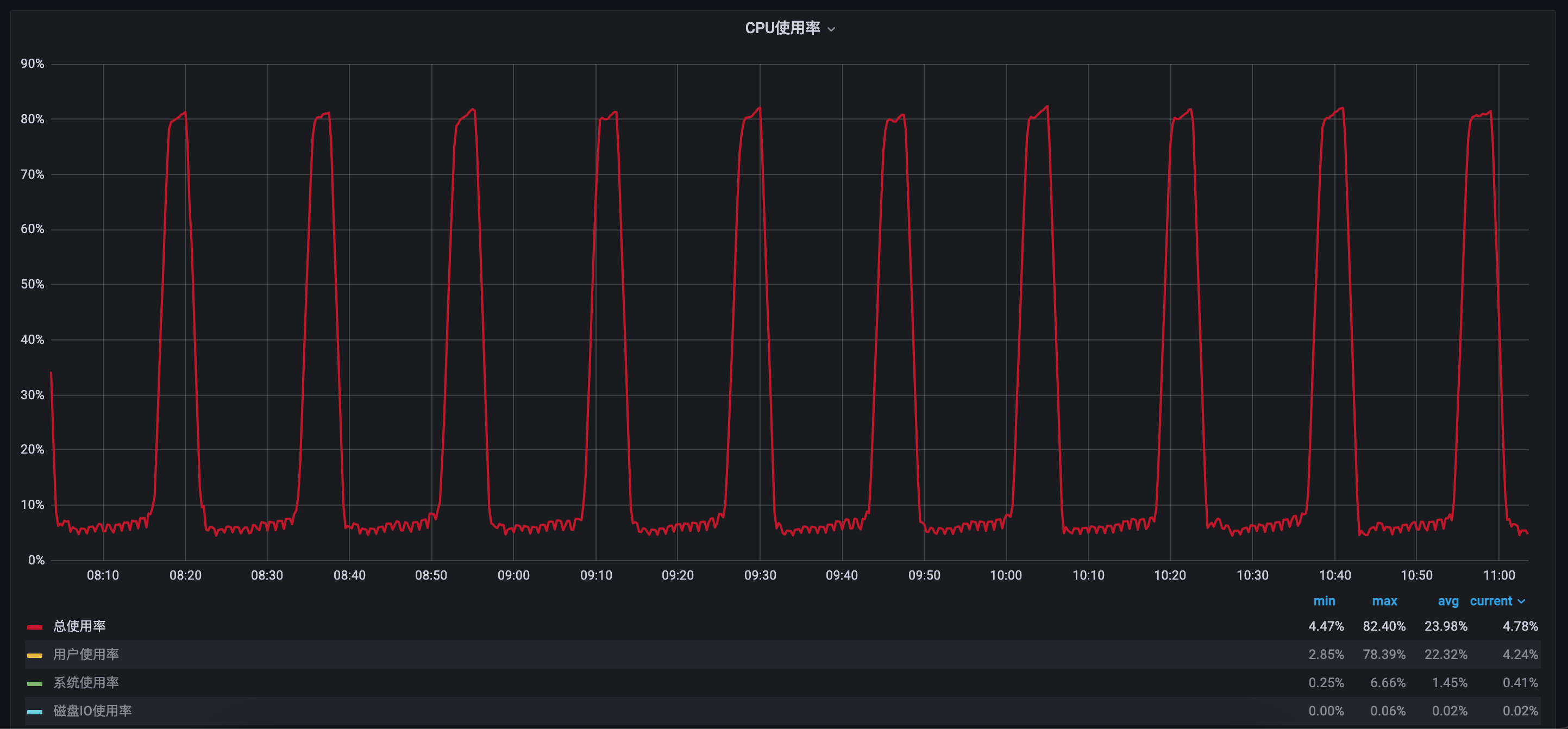
【遇到的问题:问题现象及影响】3个tidb节点,总会出现一个tidb节点内存飙升的现象。重启该tidb节点后,又会在另外一台机器上出现内存飙升的现象。循环往复,如果这个内存异常的tidb节点运行一天左右,此时CPU会在25%~100%之间稳定波动。
【资源配置】

【复制黏贴 ERROR 报错的日志】
[2025/04/16 02:59:12.511 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.677 +00:00] [ERROR] [distsql.go:1567] ["table reader fetch next chunk failed"] [conn=1562326922] [session_alias=] [error="context canceled"]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [distsql.go:1567] ["table reader fetch next chunk failed"] [conn=1562313788] [session_alias=] [error="context canceled"]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [distsql.go:1567] ["table reader fetch next chunk failed"] [conn=1562313788] [session_alias=] [error="context canceled"]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.679 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [distsql.go:1567] ["table reader fetch next chunk failed"] [conn=1562326936] [session_alias=] [error="context canceled"]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [distsql.go:1567] ["table reader fetch next chunk failed"] [conn=1562326936] [session_alias=] [error="context canceled"]
[2025/04/16 02:59:12.693 +00:00] [ERROR] [select_result.go:562] ["invalid cop task execution summaries length"] [expected=1] [received=0]
【其他附件:截图/日志/监控】

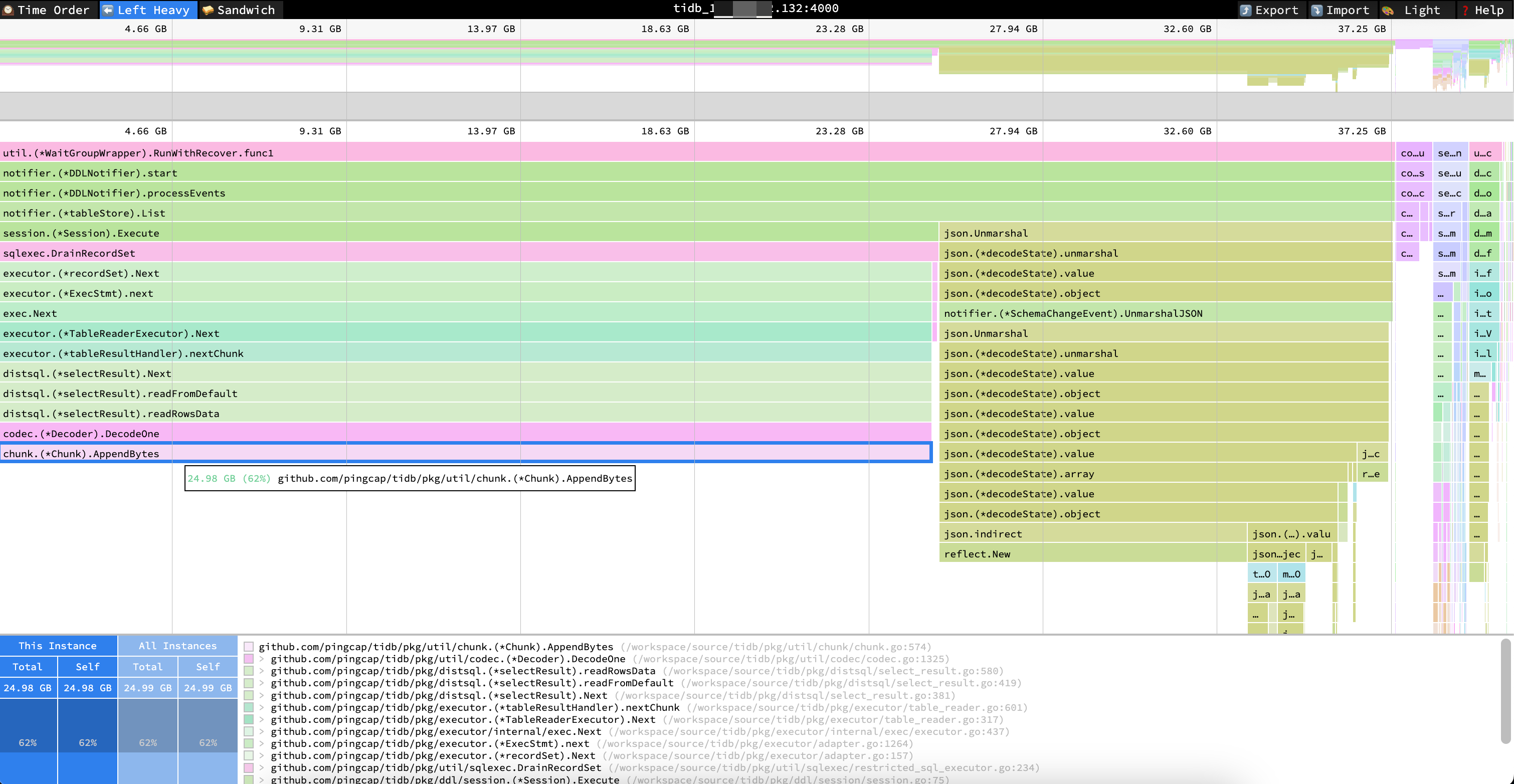

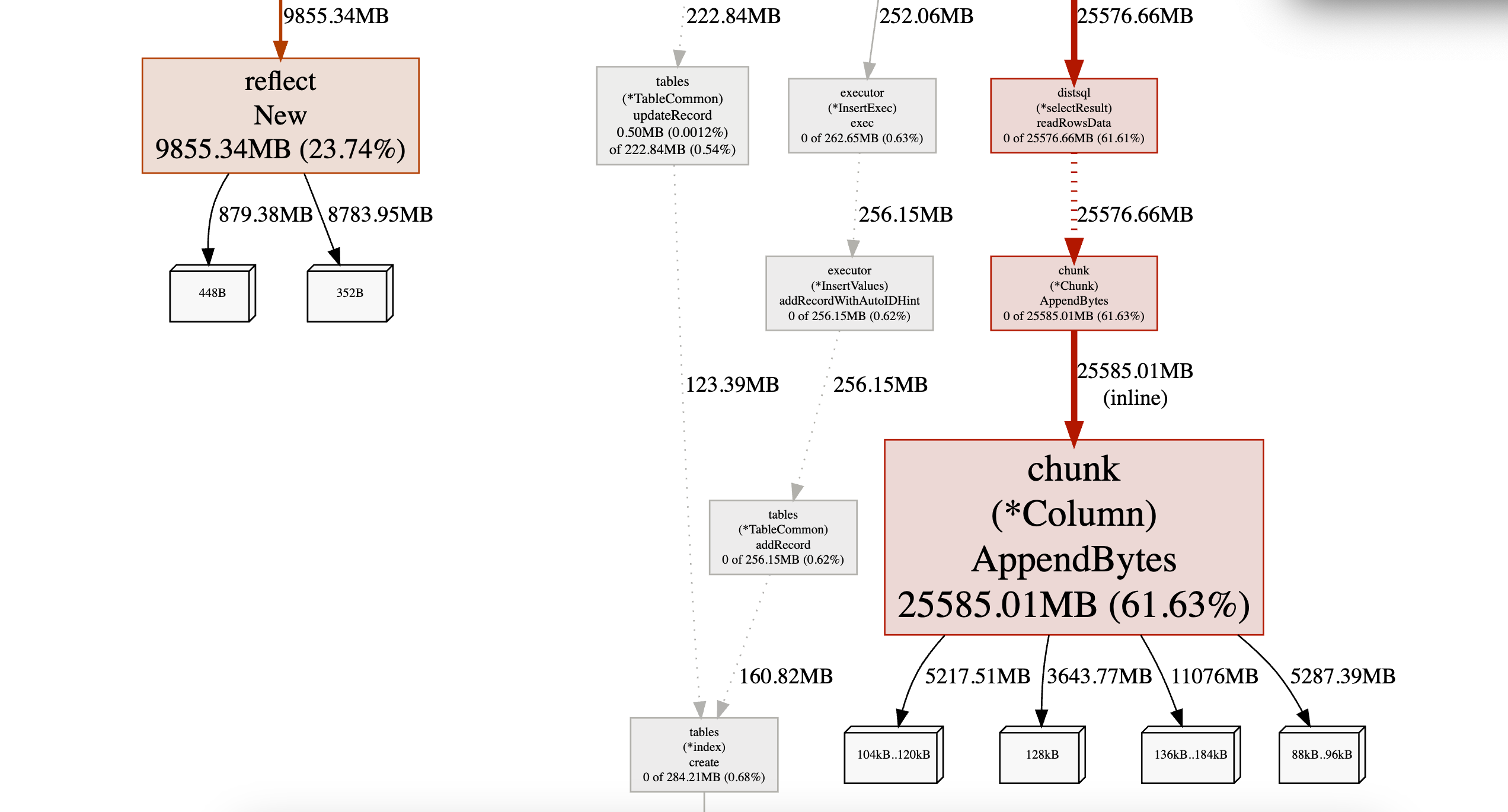
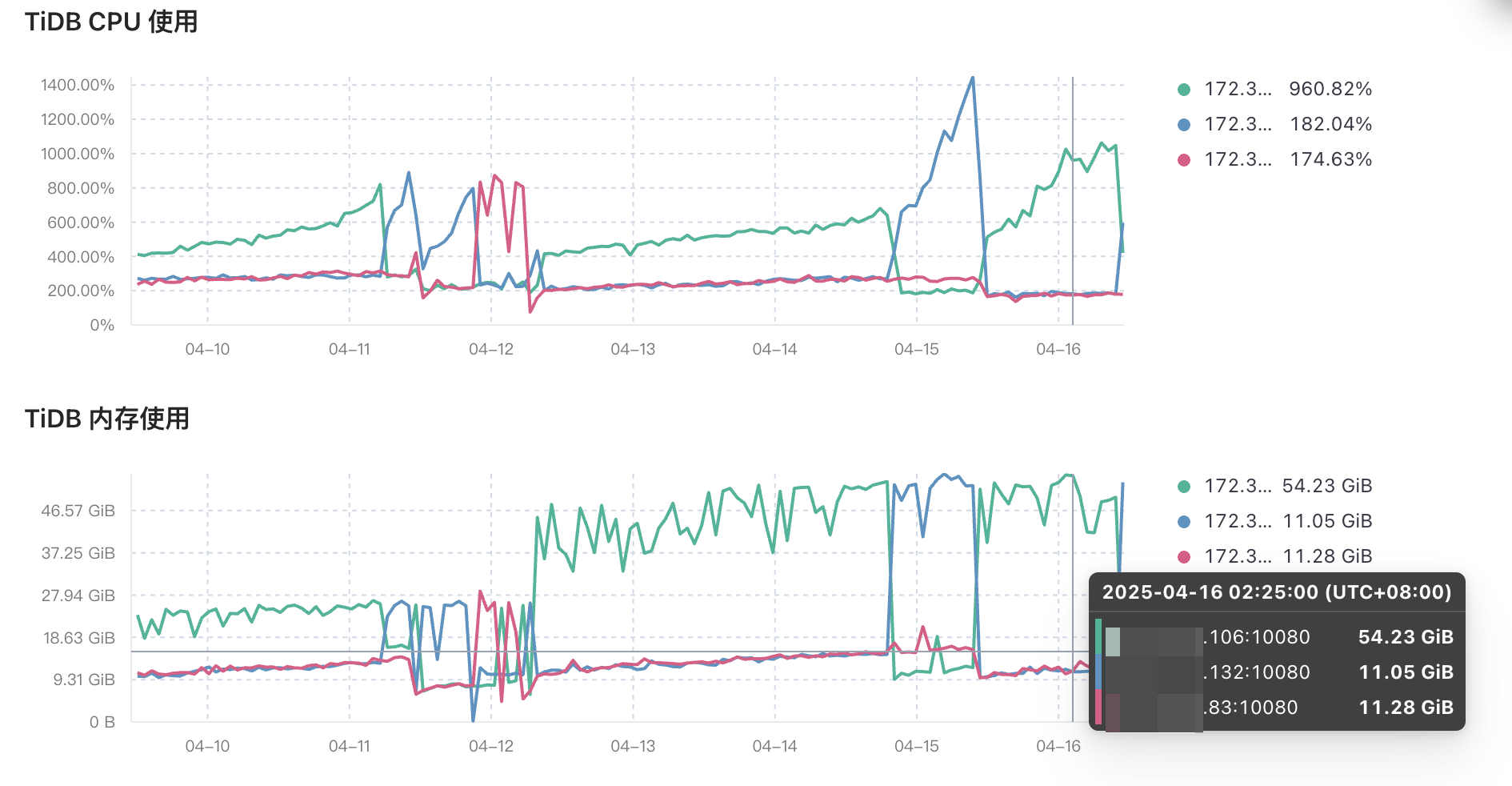
这边通过趋势图可以看到,始终有个tidb节点内存飙升,跑挂或重启后又会换成其他tidb节点复现该问题。排查处理过程:
- 短暂停过大并发的业务,看不到效果。
- kill长连接进程,看不到效果。
- 调整auto_analyze相关配置,看不到效果。
- 重启故障节点的tidb后,把最新的故障节点的tidb剔除负载(持续一段时间后,kill该节点的数据库连接,此时该节点基本没有外部连接了),看不到效果。
这个问题困扰好几天了,实在找不到解决方案了,论坛里的要么版本和我们差很多,要么问题类型不一样,麻烦好心大佬帮忙看看吧 在此感谢 ![]() 。
。