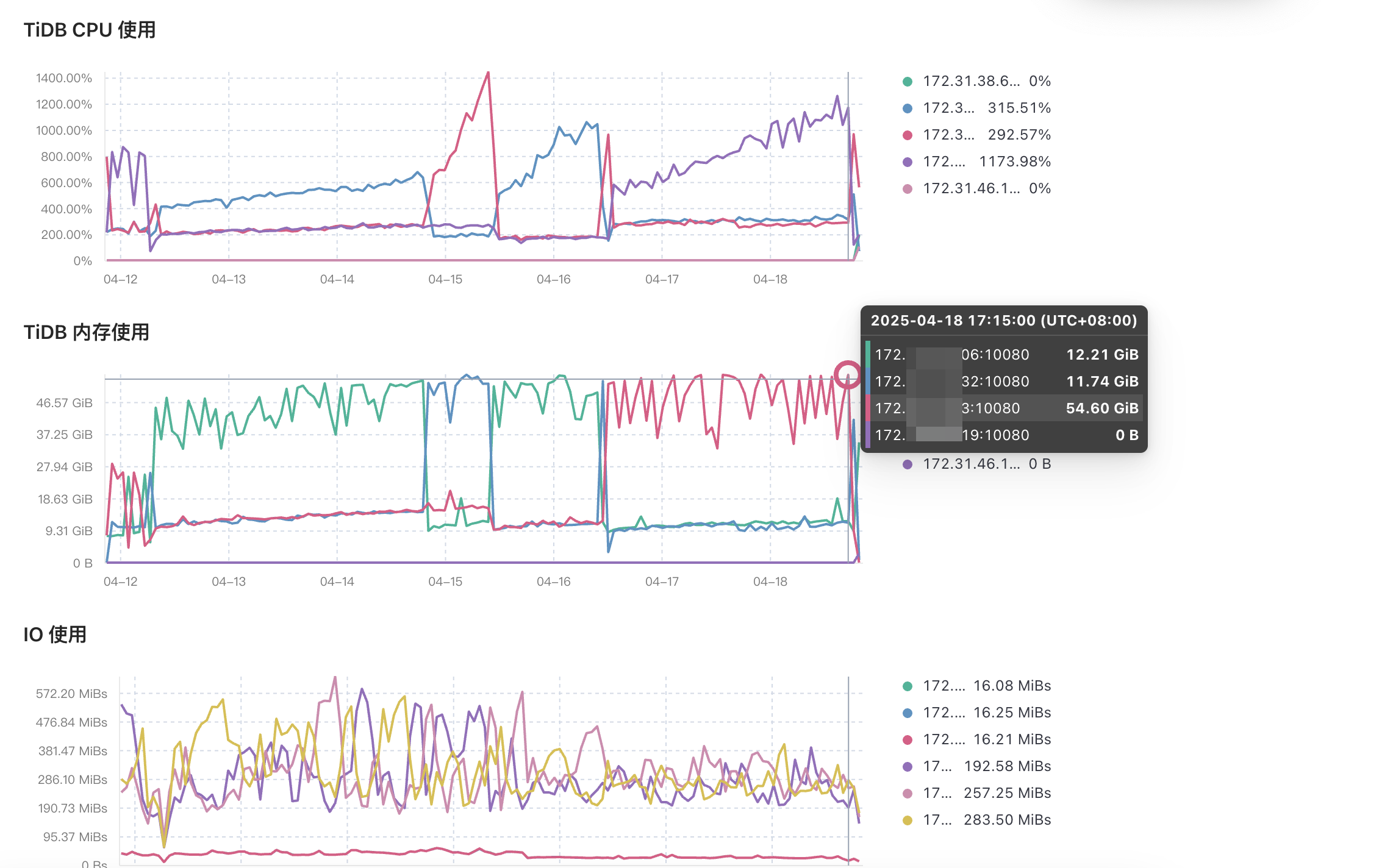
开始就是分析的慢查询,没有占用内存大的。analyze是很频繁,但是之前测试过停业务、调整auto analyze相关配置,其中某个tidb内存还是会不断增长。
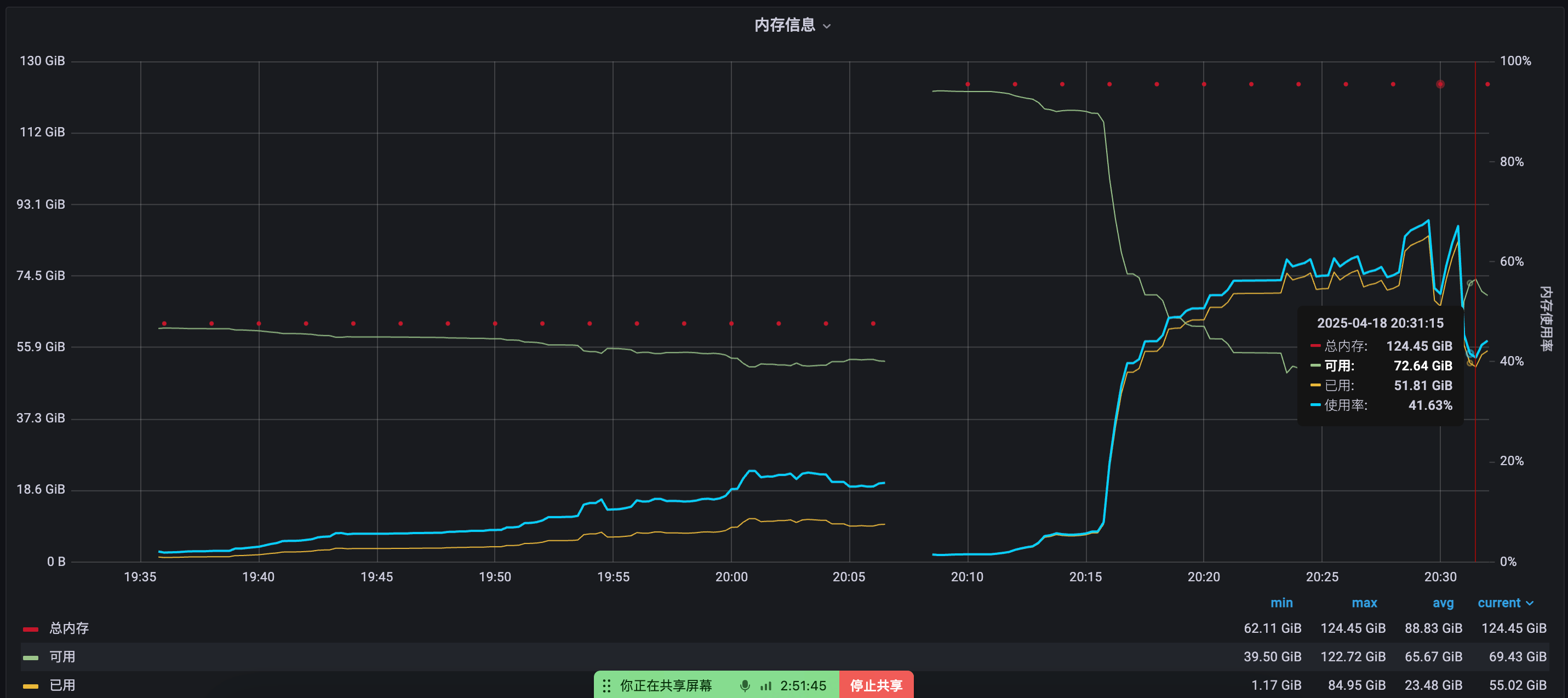
最开始机器占用20G内存,然后30G内存、30G内存,刚刚直接跑崩了。迫不得又已升级了下机器,目前128G的机器
开始就是分析的慢查询,没有占用内存大的。analyze是很频繁,但是之前测试过停业务、调整auto analyze相关配置,其中某个tidb内存还是会不断增长。
最开始机器占用20G内存,然后30G内存、30G内存,刚刚直接跑崩了。迫不得又已升级了下机器,目前128G的机器
你们集群里面 ddl 操作会很频繁吗?能查一下 mysql.tidb_ddl_notifier 这张表有多少数据吗?看着像这个问题:TiDB OOM after created about 6.5M tables · Issue #58368 · pingcap/tidb · GitHub
一个简单的 workaround:如果查询 mysql.tidb_ddl_notifier 里面的记录很多,可以尝试定期 truncate 一下这个表。理论上这个问题就解决了(它是个内部机制,不会对 ddl 本身的执行和正确性产生任何影响)。
我们会在 8.5.2 修复该问题。这个问题会在 ddl 事件非常多的场景下出现。另外能检查下日志里面有 ddl notifier 相关的处理错误吗?
刚刚查询了下,mysql.tidb_ddl_notifier 有2124506条数据。我看内存分析图很像我们这个情况,我们这边确实会频繁操作DDL。请问ddl notifier错误是在什么组件的日志中查看呢?
你们主要是啥 DDL 操作?在 tidb 的日志里面搜一下 Error processing events 相关的日志
能找一下早期的日志吗?找找非 context canceled 的错误。再看下 profile 看看内存占用在哪个地方呢?
之前日志太多了,我们只保留了7天的,已经自动清理没了。
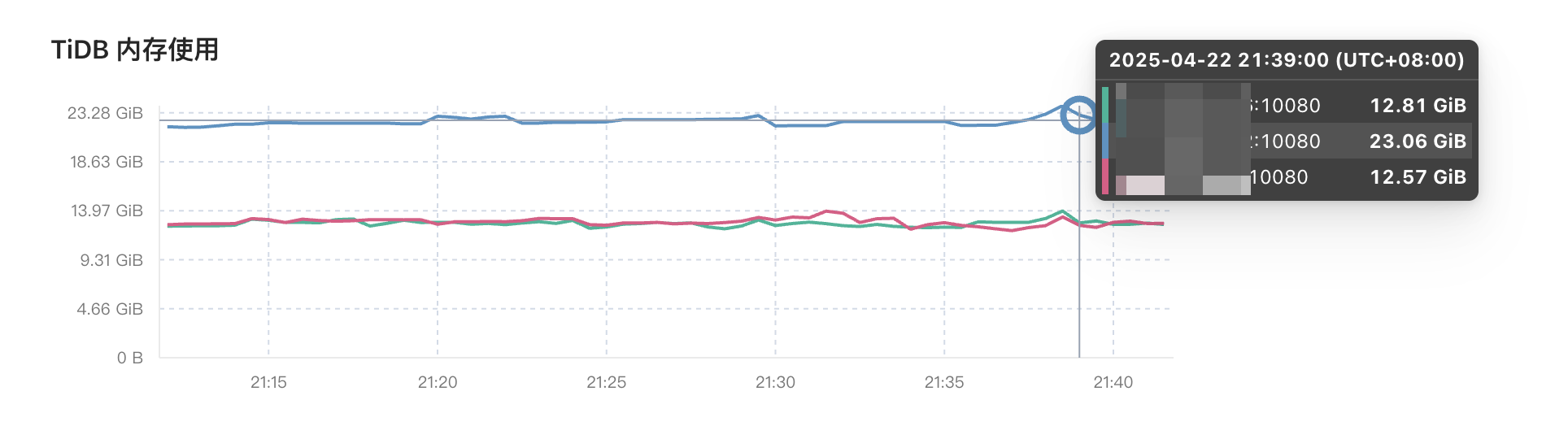
刚才降级、重启了下tidb,现在内存基本恢复平均的负载状态。
感谢大佬!帮忙解决了困扰两周多的问题! ![]()
不客气,你们可以再观察下这个表的数据增长。如果能发现新的错误信息可以跟我们分享下。我们定位下为啥这个表的数据会积累。理论上这个表里面的数据会被处理完之后清理。不确定为啥能积攒到 200 万条。另外你们 ddl 大概是个什么频率?
现在看起来这个表数据是会自己清理,如果有错误我还在这里通知你吧。目前业务已经降低了DDL的频率,出现了十几条很快就减小了。
自动清理才是符合预期的
降低lsm合并时间呢?
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。