【 TiDB 使用环境】生产环境
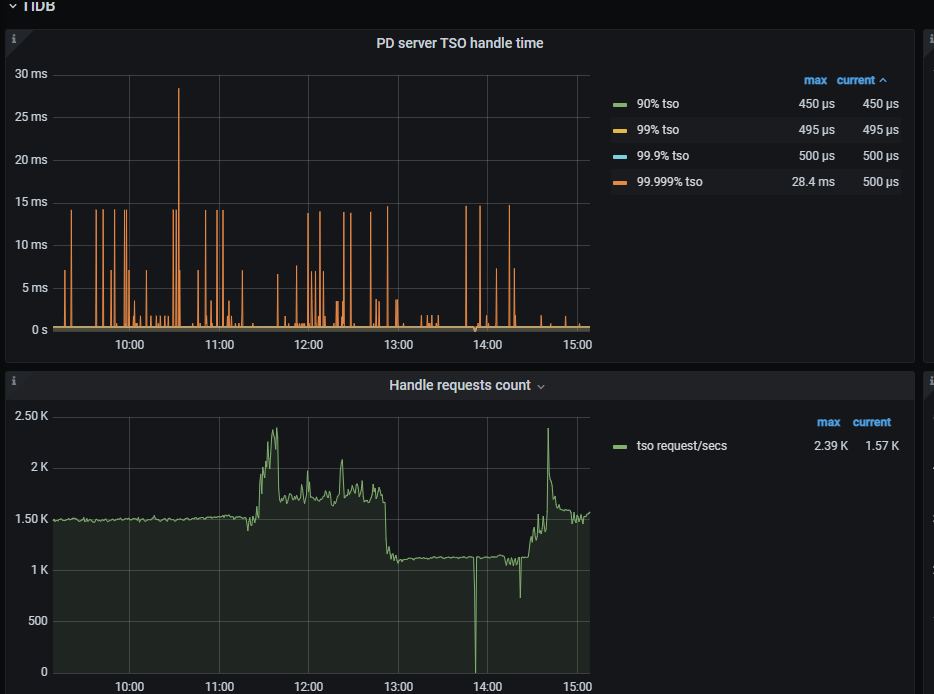
现在集群消费不动上油信息,下图是相关的延迟参数和监控,想询问下,如此状态时否是正常的 ,只是单纯的到达了机器的瓶颈


tso_wait 有点高,可以看看 PD 侧监控以及 tidb 侧 tso获取时间是否正常。
1 个赞
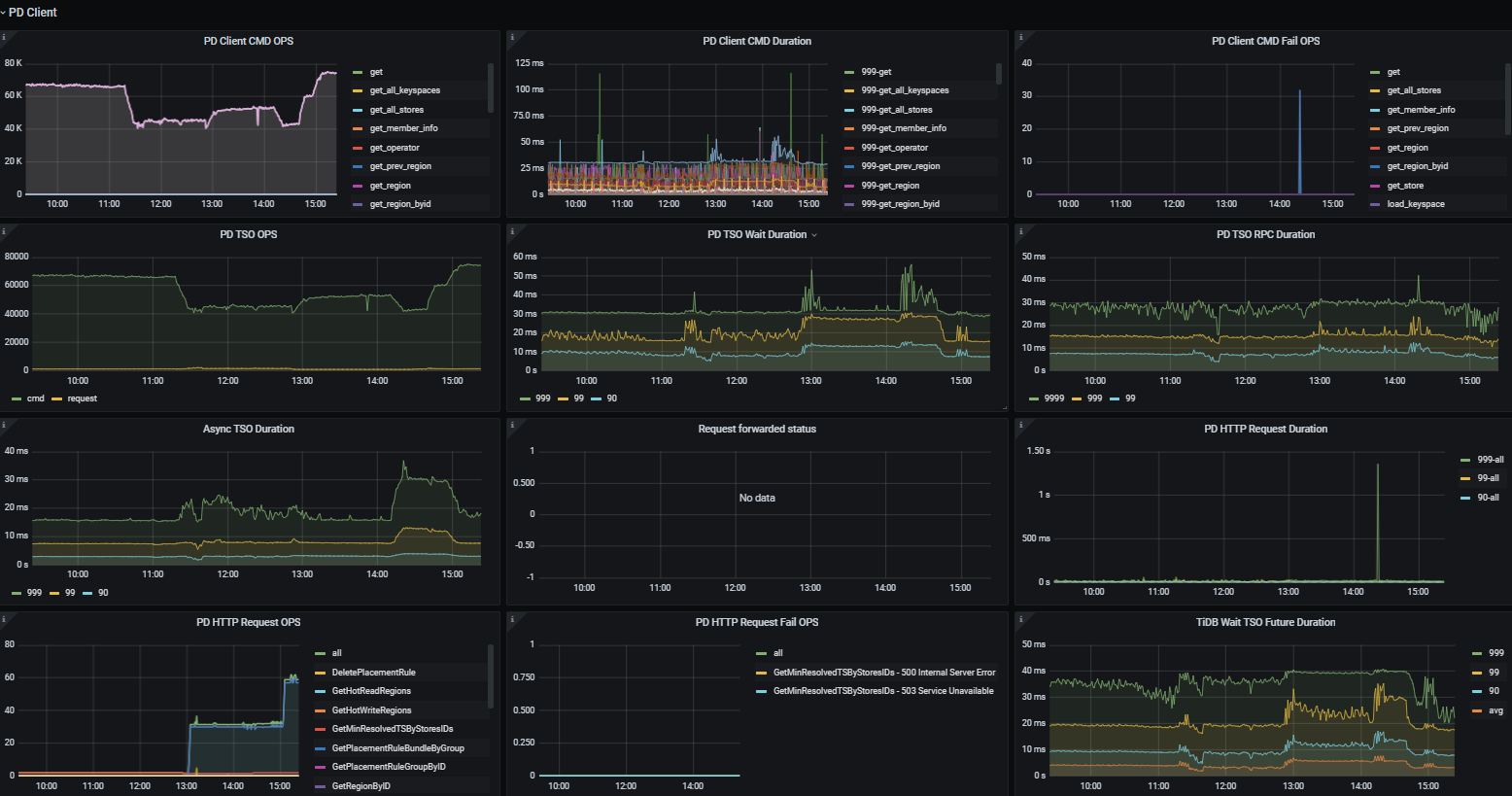
再看下 tidb 侧 pd-client 的监控。
另外看到 compile 时间较高,可以考虑使用 prepare + plan cache。
1 个赞
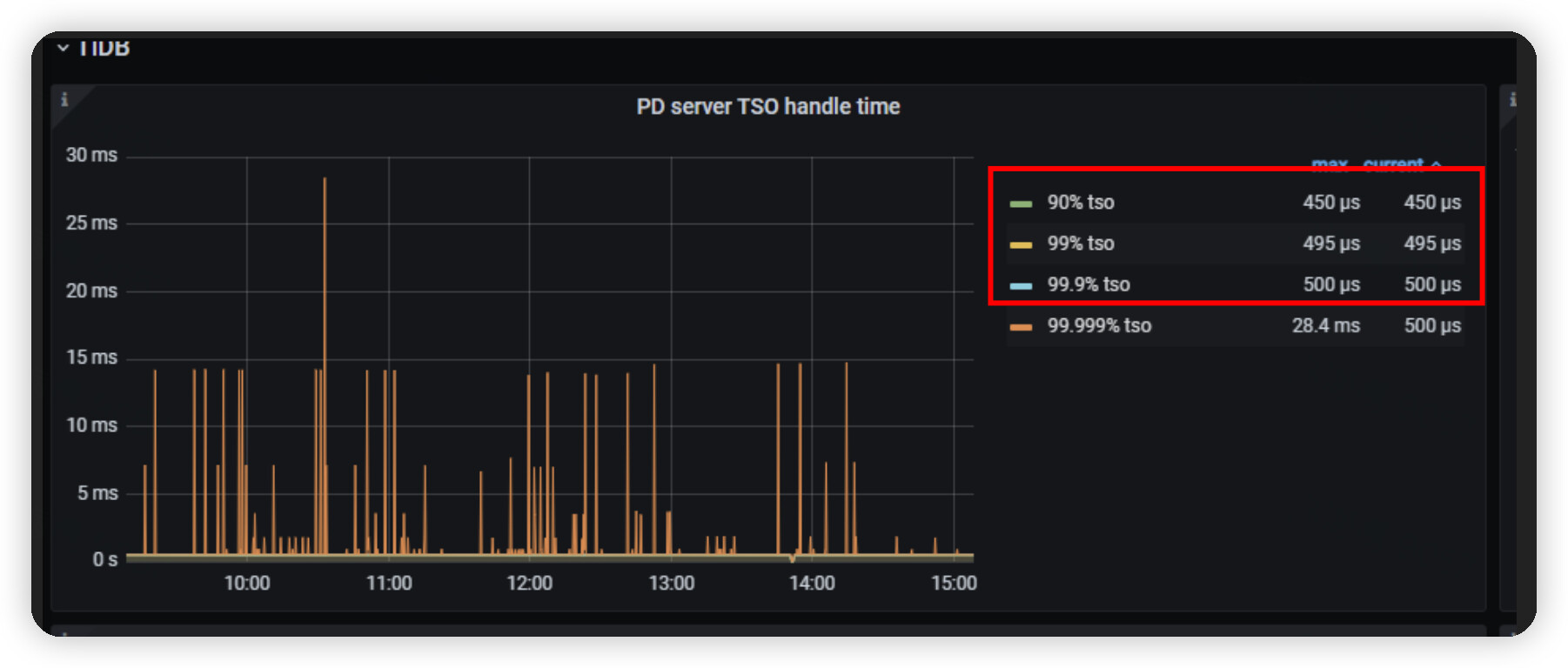
tidb 侧 tso 耗时要比 pd 侧处理时间高很多。要不是网络有问题,要不是 tidb 压力过大。
建议排查下网络情况,如果网络正常,同步检查下 tidb-server 资源情况,如果资源使用很多,可以尝试增加下 tidb-server 的机器数量。
现在tidb确实cpu百分之90了
1 个赞
是看哪个指标得出的结论呢

好我这边减少业务量 参数上有推荐吗
总感觉参数不是很合理
tidb:
log.file.max-days: 15
log.slow-threshold: 3000
prepared-plan-cache.capacity: 1000
prepared-plan-cache.enabled: true
tidb_enable_tmp_storage_on_oom: true
tidb_enforce_mpp: true
tidb_mem_quota_query: 1073741824
tikv-client.copr-cache.capacity-mb: 3000
tmp-storage-path: /tidb
tmp-storage-quota: 8589934592
tikv:
coprocessor.region-split-size: 256MiB
log.file.max-days: 15
raftdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
raftdb.max-background-jobs: 48
raftstore.raft-base-tick-interval: 2s
raftstore.store-io-pool-size: 4
raftstore.store-pool-size: 8
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
rocksdb.defaultcf.block-size: 64KB
rocksdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
rocksdb.defaultcf.titan.blob-file-compression: zstd
rocksdb.defaultcf.titan.level-merge: true
rocksdb.defaultcf.titan.min-blob-size: 16KB
rocksdb.max-background-jobs: 32
rocksdb.titan.enabled: true
rocksdb.writecf.block-size: 128KB
rocksdb.writecf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
server.grpc-concurrency: 8
storage.block-cache.capacity: 60GB
storage.enable-async-apply-prewrite: true
pd:
log.file.max-days: 7
replication.enable-placement-rules: true
replication.location-labels: - az
- rack
- host
schedule.hot-region-cache-hits-threshold: 2
schedule.hot-region-schedule-limit: 8
tso-update-physical-interval: 1ms
抱歉。参数调优得结合着业务特征和数据库表现综合来看,基于目前的信息没法给出太多建议。
1 个赞
好的 谢谢
可以看看dashboard里的top sql,看看cpu占用高的sql,分析有没有优化的可能。
可以看看慢日志中的SQL,以及tidb dashboard中的top sql 5,看看SQL层面是否可以先进行优化,如果没有,可以考虑扩容一个tidb节点
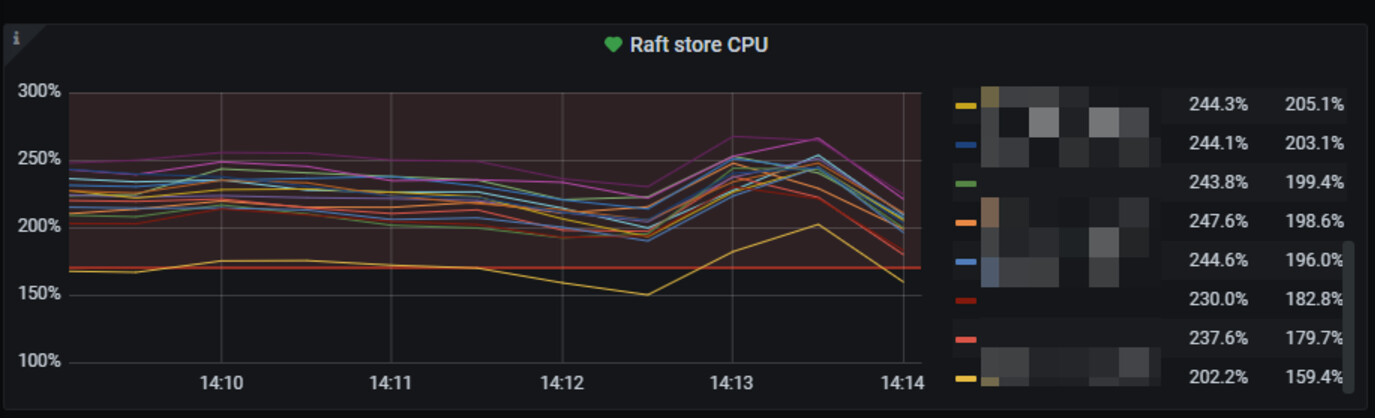
raft store cpu超过红线比较多。tikv的cpu占用如何?
如果tikv的cpu资源有富裕,可以调整一下raftstore的cpu。
具体看
https://docs.pingcap.com/zh/tidb/stable/tune-tikv-thread-performance#tikv-线程池调优
- Raftstore 线程池是 TiKV 中最复杂的一个线程池,默认大小 (由
raftstore.store-pool-size控制) 为 2。StoreWriter 线程池的默认大小 (由raftstore.store-io-pool-size控制) 为 1。
- 当 StoreWriter 线程池大小为 0 时,所有的写请求都会由 Raftstore 线程以 fsync 的方式写入 RocksDB。此时建议采取如下调优操作:
- 将 Raftstore 线程的整体 CPU 使用率控制在 60% 以下。当把 Raftstore 线程数设为默认值 2 时,将 Grafana 监控上 TiKV-Details、Thread CPU、Raft store CPU 面版上的数值控制在 120% 以内。由于存在 I/O 请求,理论上 Raftstore 线程的 CPU 使用率总是低于 100%。
- 不建议为了提升写性能而盲目增大 Raftstore 线程池大小,这样可能会适得其反,增加磁盘负担,导致性能变差。
- 当 StoreWriter 线程池大小不为 0 时,所有写请求都由 StoreWriter 线程以 fsync 的方式写入 RocksDB。此时建议采取如下调优操作:
- 仅在整体 CPU 资源比较充裕的情况下启用 StoreWriter 线程池,并将 StoreWriter 线程和 Raftstore 线程的 CPU 使用率控制在 80% 以下。与写请求在 Raftstore 线程完成的情况相比,理论上 StoreWriter 线程处理写请求能够显著地降低写延迟和读的尾延迟。然而,写入速度变得更快意味着 Raft 日志也变得更多,从而导致 Raftstore 线程、Apply 线程和 gRPC 线程的 CPU 开销增多。在这种情况下,CPU 资源不足可能会抵消优化效果,反而还可能比原来的写速度更慢,因此若是 CPU 资源不充裕则不建议开启 StoreWriter 线程。由于 Raftstore 线程把绝大部分的 I/O 请求交给 StoreWriter,因此 Raftstore 线程的 CPU 使用率控制在 80% 以下即可。
- 大多数情况下将 StoreWriter 线程池的大小设为 1 或 2 即可。这是因为 StoreWriter 线程池的大小会影响 Raft 日志数量,所以该值不宜过大。如果 CPU 使用率高于 80%,可以考虑再增加其大小。
- 注意 Raft 日志增多对其他线程池 CPU 开销的影响,必要的时候需要相应地增加 Raftstore 线程、Apply 线程和 gRPC 线程的数量。
现在调整了 其他都在红线下了 但是rocksdb还是不太正常
coprocessor.region-split-size: 256MiB
log.file.max-days: 15
raftdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
raftstore.raft-base-tick-interval: 2s
raftstore.store-io-pool-size: 1
raftstore.store-pool-size: 2
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
rocksdb.defaultcf.block-size: 64KB
rocksdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
rocksdb.defaultcf.titan.blob-file-compression: zstd
rocksdb.defaultcf.titan.level-merge: true
rocksdb.defaultcf.titan.min-blob-size: 16KB
rocksdb.max-background-jobs: 32
rocksdb.titan.enabled: true
rocksdb.writecf.block-size: 128KB
rocksdb.writecf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- “no”
- lz4
- lz4
- zstd
- zstd
server.grpc-concurrency: 4
storage.block-cache.capacity: 60GB
storage.enable-async-apply-prewrite: true
具体感受是哪里不太正常。如果用眼睛看的话
raftdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
rocksdb.defaultcf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
- zstd
rocksdb.writecf.compression-per-level:
- “no”
- “no”
- “no”
- lz4
- “no”
- lz4
- lz4
- zstd
- zstd
这几个压缩算法配置的都挺怪的。因为一共就6层,你这3个cf的配置层数都超过6. ![]()
现在处境很尴尬 15台kv了,业务场景是消费消息插入tidb,但是总是消费速度起不来,有种写不进的感觉。业务上的插入sql就是 insert ,values 这样的。但是平均延时也就29ms,max:29s 感觉有点迷茫了 不知道猫哥 第一感觉是什么问题 还是说tidb本身对这种情况不太支持,现在业务已经将查询需求全部切走了,只留下写入的。
那我这变调整为
- “no”
- “no”
- “no”
- lz4
- lz4
- zstd
这样是否合适些呢