tikv的cpu和io的监控有嘛?这两个总该有一个是瓶颈。
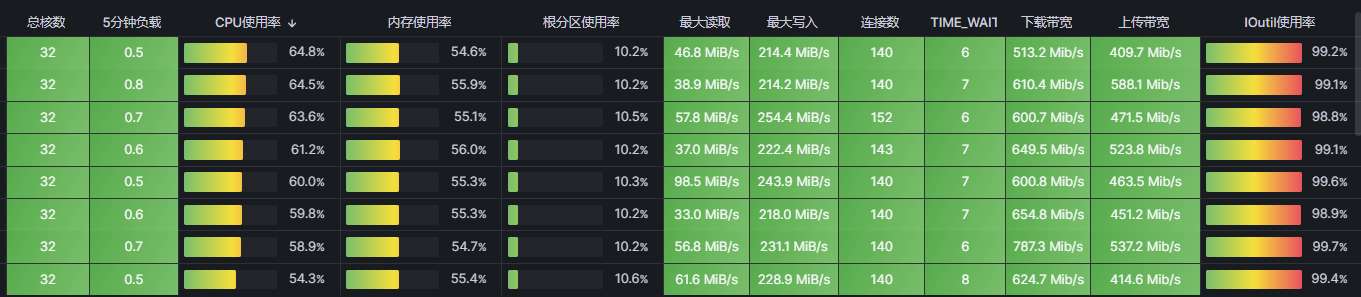


这个是参考文档 文档是七层
你这一堆参数,我不知道是基于什么原因调整的,如果没有什么根据,不如整个去掉。
rocksdb.titan.enabled: true
特别是你还把titan打开了
https://docs.pingcap.com/zh/tidb/stable/titan-overview#titan-介绍
Titan 适合在以下场景中使用:
- 前台写入量较大,RocksDB 大量触发 compaction 消耗大量 I/O 带宽或者 CPU 资源,造成 TiKV 前台读写性能较差。
- 前台写入量较大,由于 I/O 带宽瓶颈或 CPU 瓶颈的限制,RocksDB compaction 进度落后较多频繁造成 write stall。
- 前台写入量较大,RocksDB 大量触发 compaction 造成 I/O 写入量较大,影响 SSD 盘的寿命。
开启 Titan 需要考虑以下前提条件:
- Value 较大。即 value 平均大小比较大,或者数据中大 value 的数据总大小占比比较大。目前 Titan 默认 1KB 以上大小的 value 是大 value,根据实际情况 512B 以上大小的 value 也可以看作是大 value。注:由于 TiKV Raft 层的限制,写入 TiKV 的 value 大小还是无法超过 8MB 的限制,可通过
raft-entry-max-size配置项调整该限制。- 没有范围查询或者对范围查询性能不敏感。Titan 存储数据的顺序性较差,所以相比 RocksDB 范围查询的性能较差,尤其是大范围查询。在测试中 Titan 范围查询性能相比 RocksDB 下降 40% 到数倍不等。
- 磁盘剩余空间足够,推荐为相同数据量下 RocksDB 磁盘占用的两倍。Titan 降低写放大是通过牺牲空间放大达到的。另外由于 Titan 逐个压缩 value,压缩率比 RocksDB(逐个压缩 block)要差。这两个因素一起造成 Titan 占用磁盘空间比 RocksDB 要多,这是正常现象。根据实际情况和不同的配置,Titan 磁盘空间占用可能会比 RocksDB 多一倍。
用这个的条件比较多。
合理的,我忘了,内存中的还有一层。
调整是尝试的吧 我整个去掉吧 tian需要保留吗
你看看这个介绍,如果不符合这些前置条件可以去掉。
另外我看了下你磁盘写入现在只有500k/s。cpu也没打满,像是热点。
https://docs.pingcap.com/zh/tidb/stable/dashboard-key-visualizer#tidb-dashboard-流量可视化页面
看看这个图,确定一下是不是热点问题。
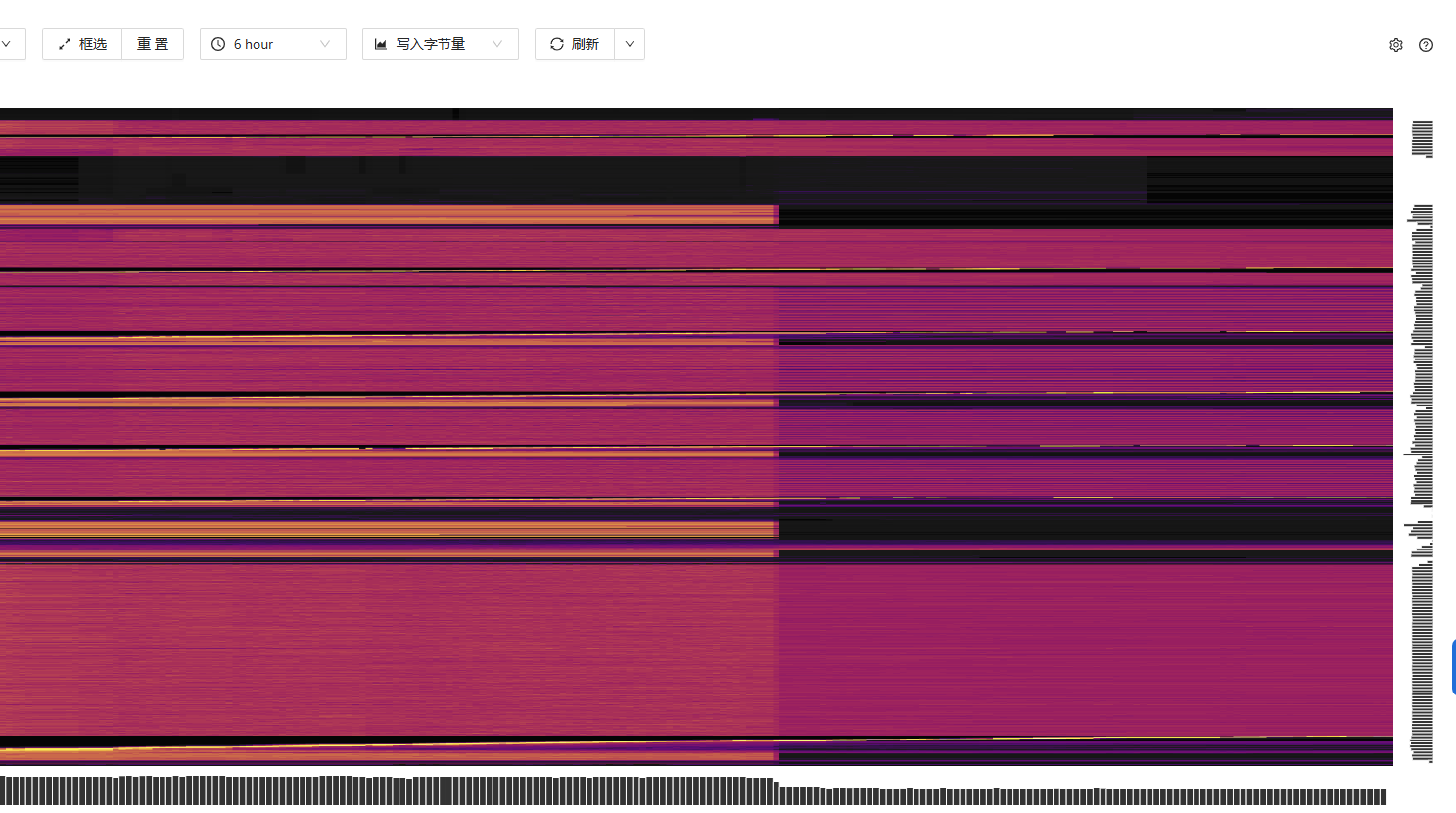
确实比较均匀。
我自己的实践是,纯导入的情况下,tikv的cpu是很容打满的。
你上面提到tidb的cpu到90%+了。
现在看更像是瓶颈在tidb的cpu上。感觉可以扩容一些tidb节点。随着tidb节点的扩容,tikv的cpu也会整体升高。
如果资源已经确定,可以考虑缩容掉一些tikv,再扩容一些tidb。
好 我这边多加tidb节点试试

如果应用没有异常跟报错,偶发的这个错误可以忽略。这是读取网络传输的 tikv 数据失败,可能是偶发的网络问题,检查tikv和PD之间的网络状态
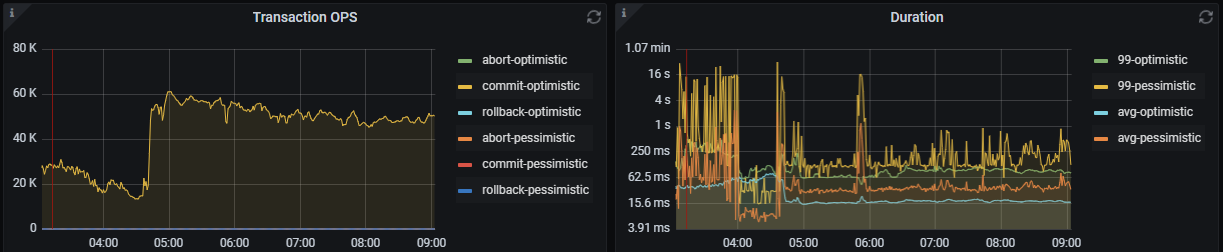
事务的延迟大部分取决于 sql 你可以通过 dashboard 的 top sql 先看看是否可以有优化的点
还是得看 top sql , 看具体的执行计划而定吧, 比如你 sql 瓶颈是在 root task, 还是 cop task 针对性分析。