

我要怎么知道他在做什么事
感觉不是在执行某个大sql导致的,这个内存跟一直在缓慢上升,大概3天就满了
像是内存泄露问题,版本是8.1.1

select * from INFORMATION_SCHEMA.CLUSTER_PROCESSLIST t where t.COMMAND<>‘Sleep’ and t.HOST=‘172.27.0.29:10080’ and time>0
查下正在执行的sql,具体干啥的,多执行一会儿一直看
1 个赞

有日志吗?tidb.log看一下,看看执行的SQL,有没有全表的操作,长时间不释放的连接有吗?
看下统计信息收集任务是不是都跑在这一个节点上
1、看tidb dashboard的top sql,可以查看到这个tidb节点的消耗cpu最高的top 5的SQL语句
2、也可以通过弄一个crontab,不断的记录这些信息到一个日志文件中,看下CPU和内存高的时候,有哪些SQL语句在跑,建议在每次执行的时候,输出下时间点的信息
select * from INFORMATION_SCHEMA.CLUSTER_PROCESSLIST t where t.COMMAND<>‘Sleep’ and t.HOST =‘172.27.0.29:10080’ and time>0
3、查看下这个tidb节点的慢日志里面有没有一些执行慢的SQL
1.看监控看tidb dashboard的top sql和慢查询。
2.看下流量可视化,看看哪一块最亮,分别看看读和写。看看哪个影响的。
如果负载相同的情况下,内存使用高于其他节点不太正常。最直接的方案可以通过 dashboard 抓一下内存火焰图或者手工收集 curl http://{TiDBIP}:10080/debug/zip?seconds=30 --output debug.zip(debug.zip 需要使用 go tool pprof 分析)。看下当前内存占用情况。
内存高的话我记得有个 issue https://github.com/pingcap/tidb/issues/52826
可以 check 下 internal sql 有没有时常运行这个 sql

是的话应该就是命中了上述 issue ;
执行了1分钟,都是空的
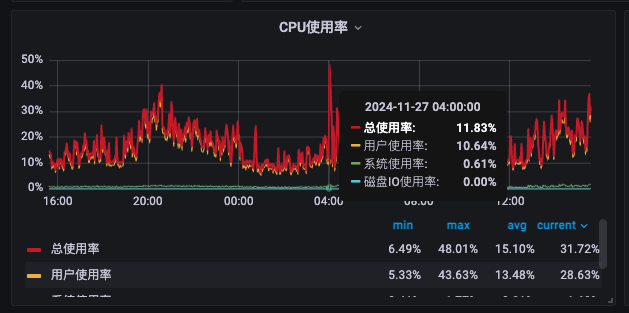

根据我设置的analyze时间跟定期删除三个月前的数据的执行时间,还有业务时间,我大概知道哪里有问题了,analyze跟ttl job都是凌晨四点执行,业务高峰期是下午2点到凌晨2点左右,cpu内存都是从凌晨4点开始升高的,目前我重启了该节点,后有跑到另一个节点高了 ![]()
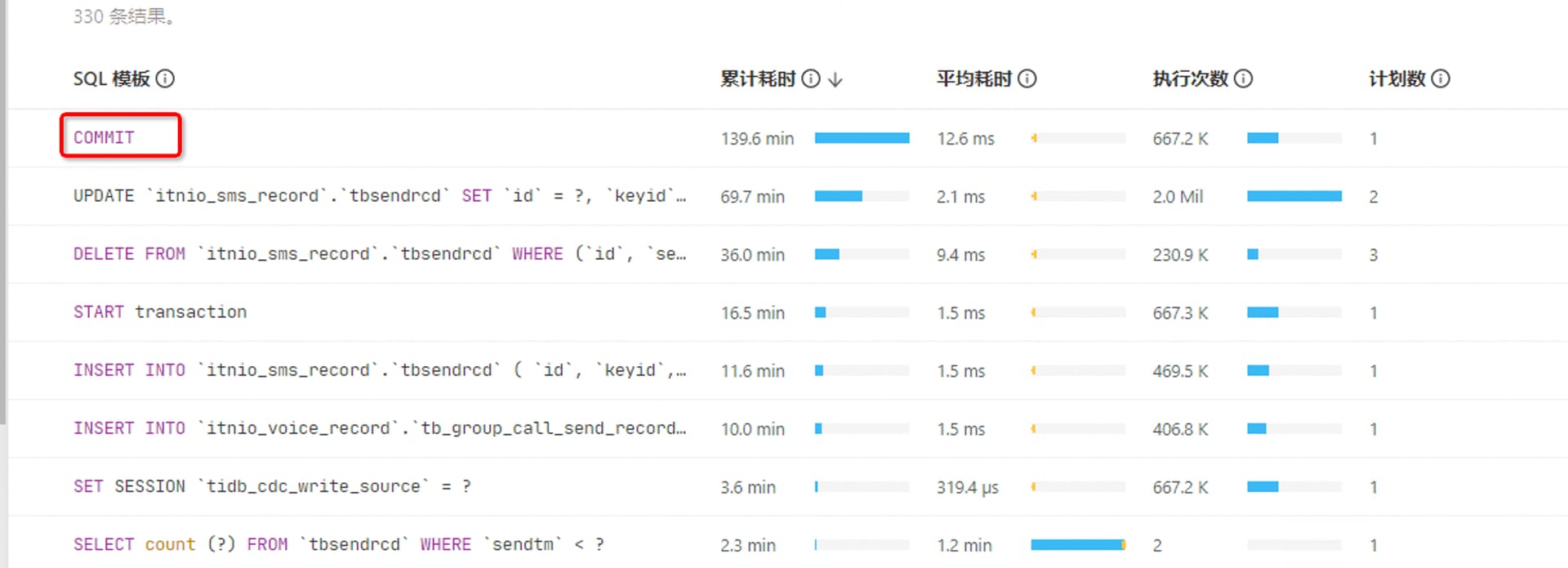
应该是所有事务的 COMMIT 都聚合到一起了,所以看起来总时间最高。
看下日志有什么报错么
你把time条件去掉总有值吧,确定下不是条件写错了
有了,把host改成instance就行了,看了下全都是从ticdc同步过来的语句,目前高峰期的话就同步的数据比较多,这个tidb主要用来分流查询的,避免大查询导致业务的tidb出问题,中间也会执行ttl job的delete 语句