点进去之后他是一个事物很多其他insert或者update,
看平均耗时,平均耗时不多 而且是一般insert的,这种问题不大,
你用平均耗时排序看看
ticdc都集中发给一个tidb server节点了吗

那看样子就不是这几个,看看TIP sql 累计CPU耗时有没有。再看看流量可视化,选择读取字节量,看看有没有特别亮的 读取数据多的表
ticdc配置的是负载均衡的地址,按理说应该是平衡的,没开启session
基本上我们读写最多的就一个表,做了按天分区的
负载均衡的是链接,某个链接执行sql多就会导致连的tidb节点负载高
grafana 里面看看 tidb的的链接数量 看看是不是都在这一台上面,
overview — TIDB----connection
以下是一些排查和解决步骤:
1. 检查内存使用情况
- 查询系统表:您可以通过查询
INFORMATION_SCHEMA.(CLUSTER_)MEMORY_USAGE和INFORMATION_SCHEMA.(CLUSTER_)MEMORY_USAGE_OPS_HISTORY系统表来查看当前实例或集群的内存使用情况。 - 监控内存使用:查看 TiDB 日志文件中关于内存使用量超过阈值的报警信息,了解当前正在执行的 SQL 语句中内存使用最高的语句和运行时间最长的语句。
2. 分析 CPU 使用情况
- 监控 CPU 负载:在 TiDB CPU 和 TiKV CPU/IO 面板中观察 TiDB 和 TiKV 的逻辑 CPU 使用率和 IO 吞吐,包含平均、最大和 delta(最大 CPU 使用率减去最小 CPU 使用率)。
- 分析慢查询:检查慢查询日志,看是否有异常 SQL 导致 CPU 使用率高。
3. 排查热点问题
- 热点查询:检查是否存在热点查询,这些查询可能会消耗大量资源,导致 CPU 和内存使用率升高。
- PD 调度:检查 PD 是否有热点调度,并且是否成功,如果没有,可能需要手动 split 并且调度开。
4. 检查配置和参数
- 内存配置:确认
tidb_server_memory_limit配置是否合理,这是单个 tidb-server 实例的内存使用阈值。 - DDL 操作:如果最近有新增索引等 DDL 操作,这可能会消耗大量资源,需要调整
tidb_ddl_reorg_worker_cnt和tidb_ddl_reorg_batch_size参数来动态调整索引创建速度。
5. 系统和硬件检查
- THP 设置:确认节点的 THP(内存大页)是否关闭,因为数据库的内存访问模式往往是稀疏的,当内存碎片化严重时,分配 THP 页面会出现较高的延迟。
- 磁盘性能:测试服务器的磁盘性能,使用工具如
sysbench或fio命令测试。
6. 调整和优化
- 配置调整:根据监控和日志信息,调整 TiDB 和 TiKV 的配置参数,如
scheduler-concurrency等,以优化性能。 - 扩容:如果资源使用接近瓶颈,考虑对 TiDB 或 TiKV 进行扩容。
如果方便的话,可以吧这个高CPU的节点关闭,然后观察看看另外两个会不会有其中一个CPU飙升。
会的,我重启过这台,然后变成另外一台高了,应该就是有个长链接,一直在跑?

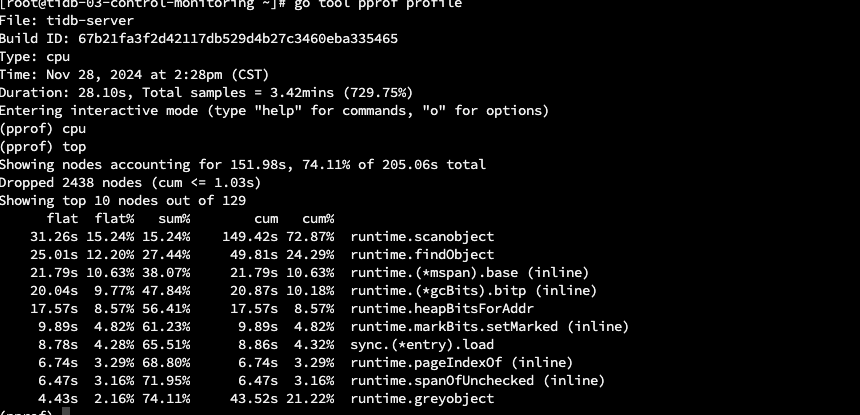
看 cpu 大部分时间消耗在 runtime 上,节点的内存压力比较大。估计 cpu 主要是用来做 gogc 了。
然后看内存大部分貌似都和创建 session 有关系,
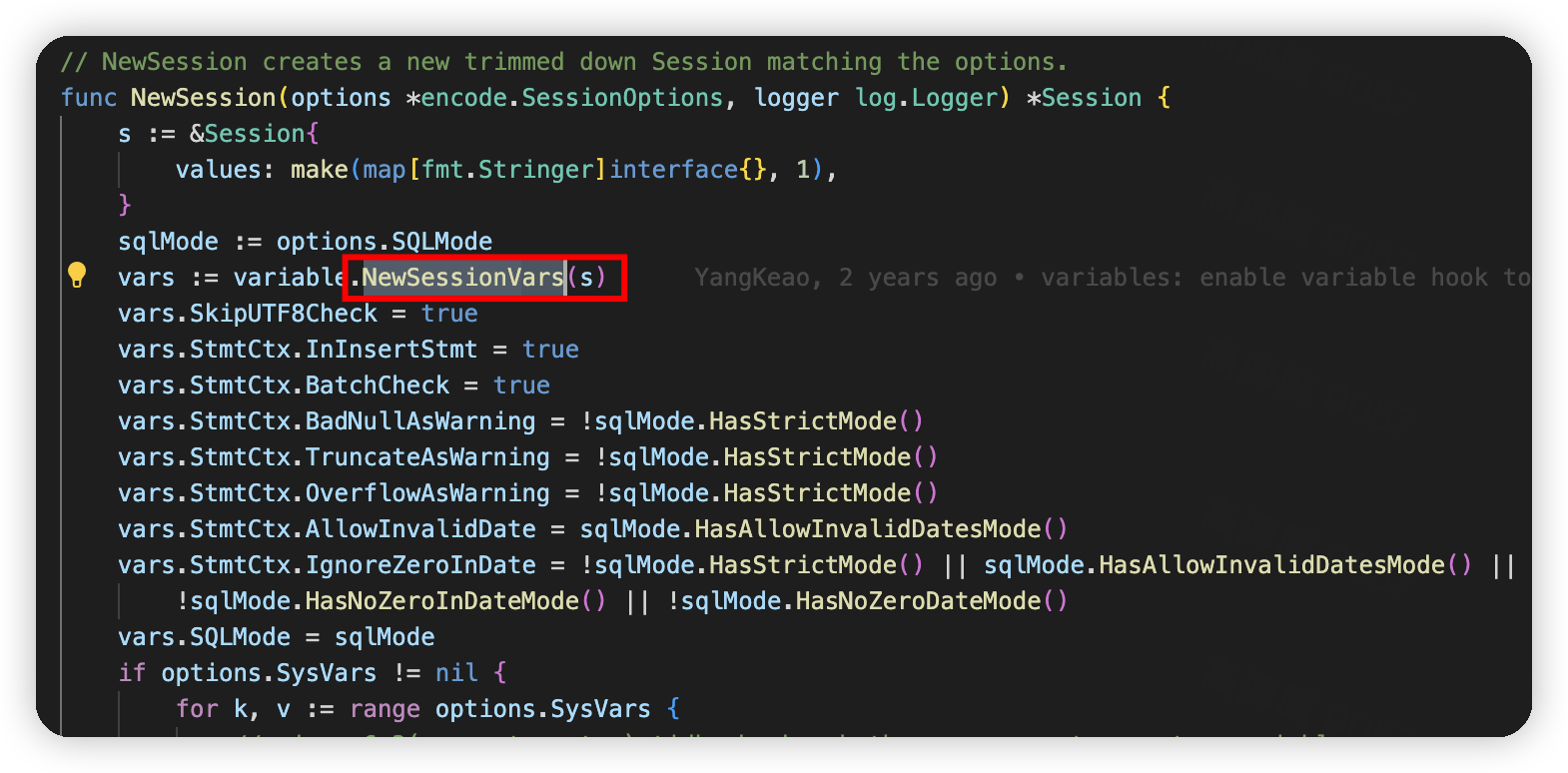
看下来应该主要是连接太多,包括内部会话和外部连接。
首先排查 show processlist或者监控 ,看下连接数是不是多于其他节点。其次排查一些内部会话情况,可能就像你前面说的 analyze , ttl 任务之类的。
还有一种可能,如果你的内存是持续缓慢上升且一直没有释放,那有可能是内存泄露了 ![]() 得找官方看一下了
得找官方看一下了
ttl任务快执行完成了,因为是从其他tidb同步过来的,ttl时间有差别,目前还有5E数据没删掉,估计还有3天才会删除感觉
如果是内存持续上升还好说,cpu也是这样,持续上升,几天就到阈值了
连接数的话其实还好,这台查询的程序不多,另一个tidb集群配置跟这个集群差不多,外部连接数每台有2000多,这个集群的外部连接数才300多,应该就是内部的连接,像我说的,ttl跟analyze,等ttl删除干净历史数据后我再测试一下
https://docs.pingcap.com/zh/tidb/stable/system-variables#tidb_ttl_running_tasks-从-v700-版本开始引入
可以尝试降低下并发看看
这种跑任务的独立出来,踢出负载均衡。等你任务跑完就正常了。
这个内存的文件能发一下吗?另外再确认一个事情,你集群是 8.1.1 版本?
我觉得你是遇到了内存泄露
https://github.com/pingcap/tidb/pull/56950 ![]()