【背景】
我们构建了一套 juicefs + tikv + ceph 的分布式文件系统,其中 tikv 集群用于存放元数据,由 3 个物理节点构成,每个节点上都混部了一个 tikv 服务和一个 pd 服务。
【 TiDB 版本】
v 6.5.0
【复现路径】
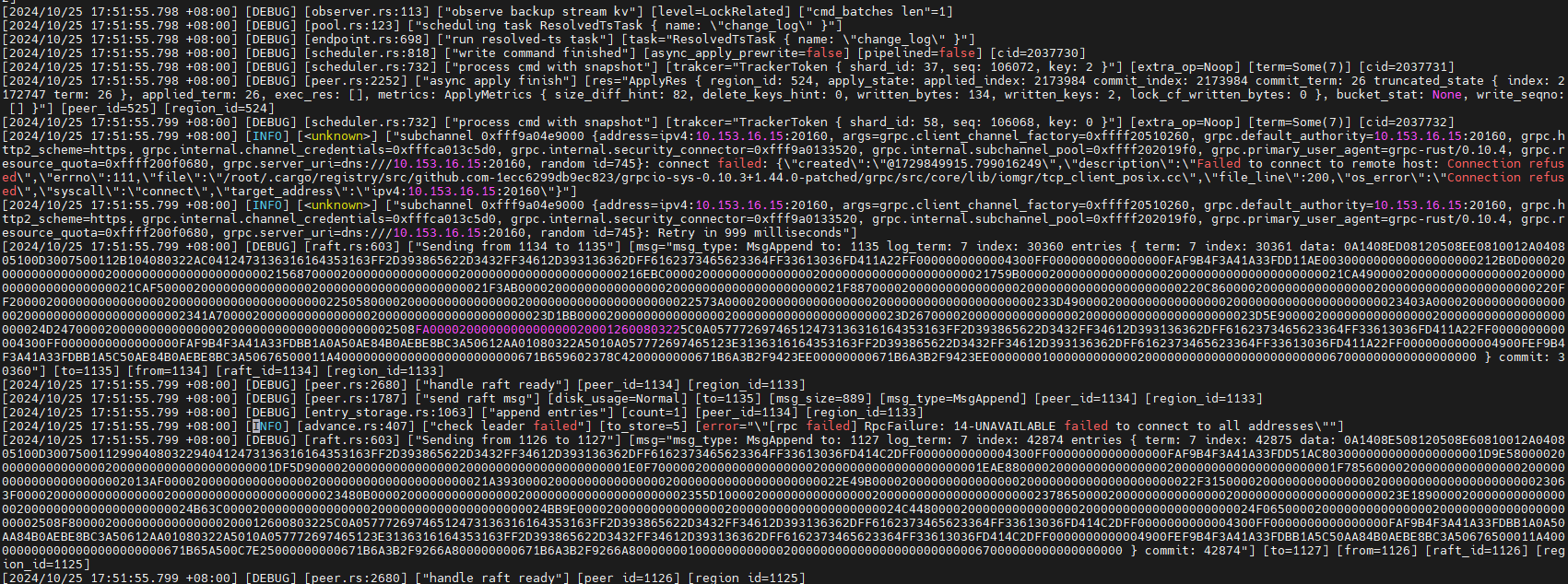
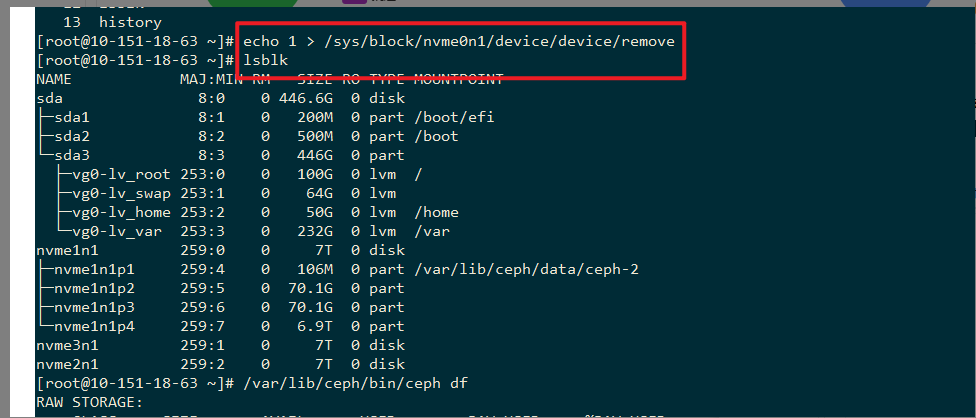
删除tikv的挂载盘
【遇到的问题:问题现象及影响】
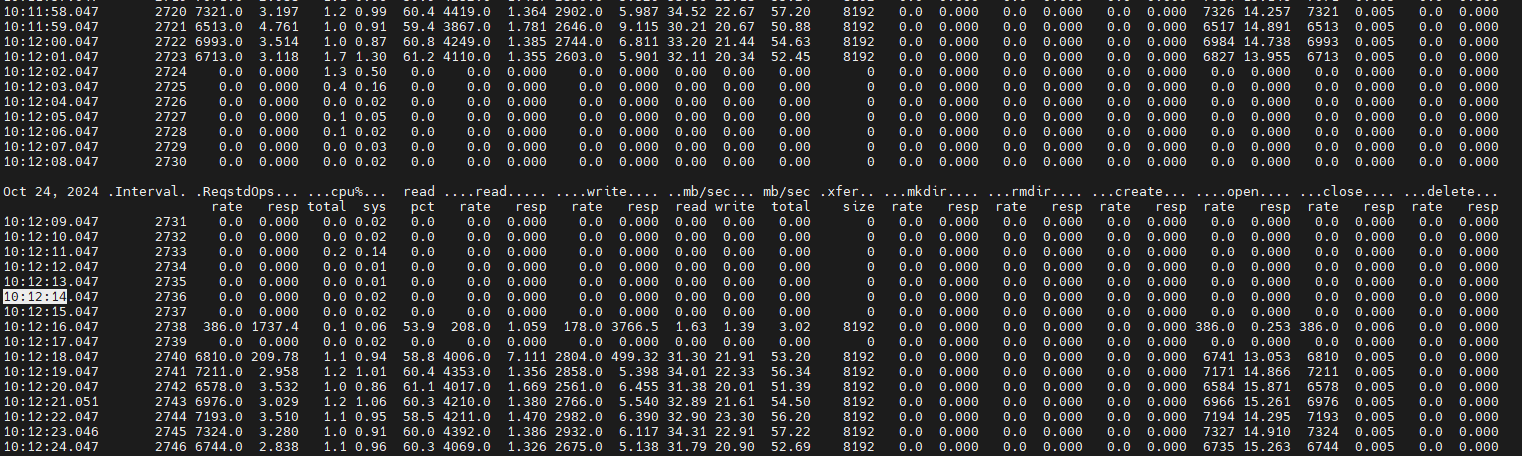
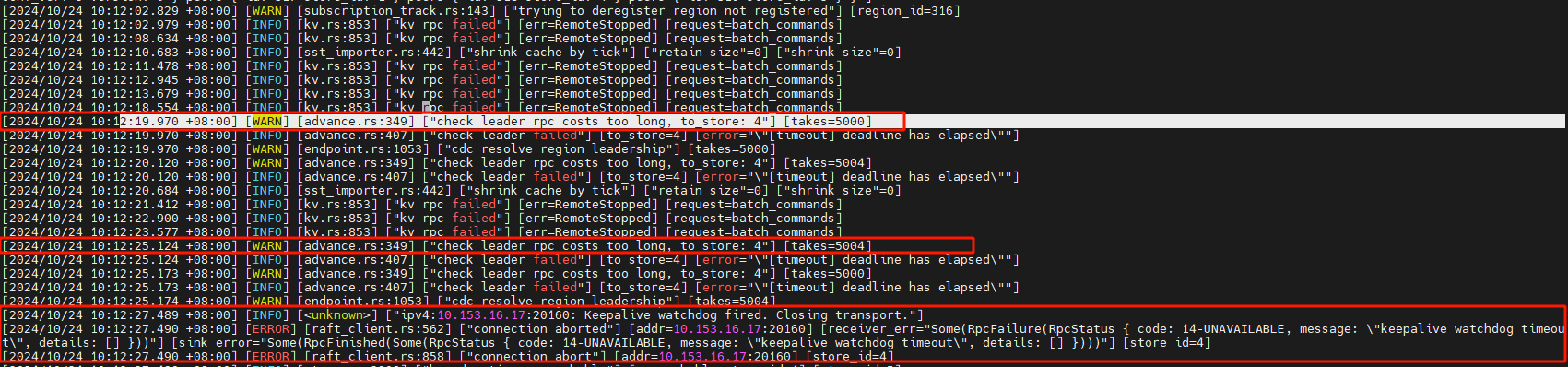
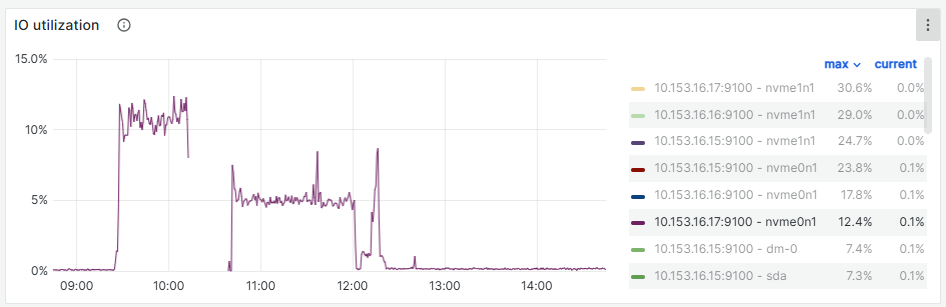
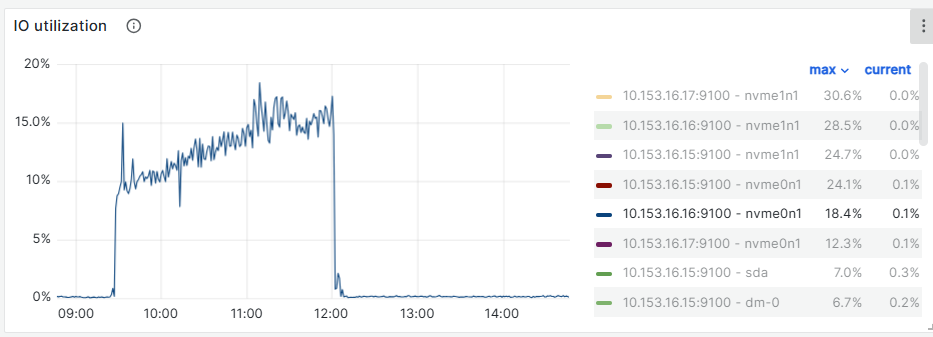
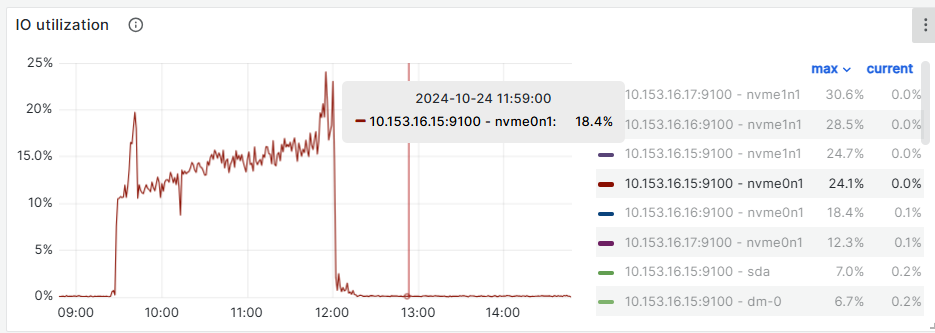
vdbench IO出现跌零15s,客户端和集群相差13~14秒左右
【附件:截图/日志/监控】
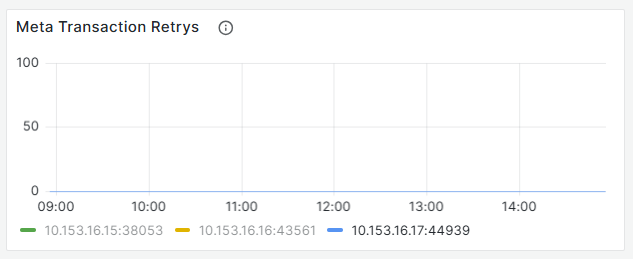
tikv日志


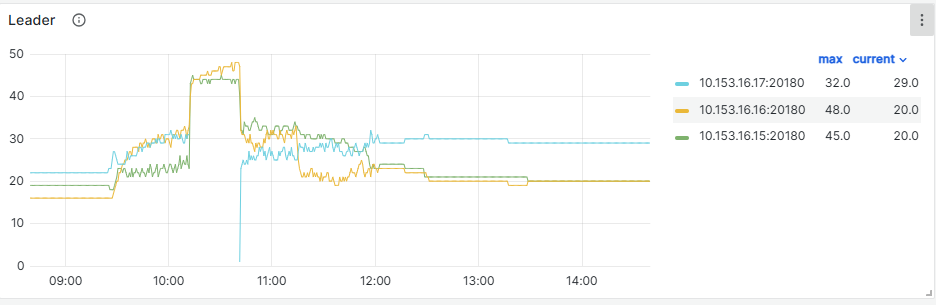
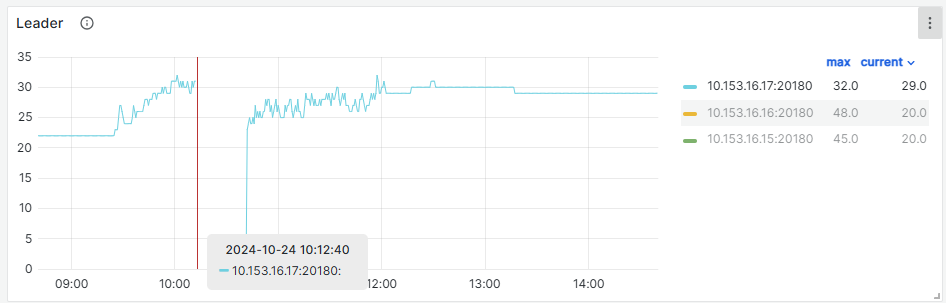
监控

【背景】
我们构建了一套 juicefs + tikv + ceph 的分布式文件系统,其中 tikv 集群用于存放元数据,由 3 个物理节点构成,每个节点上都混部了一个 tikv 服务和一个 pd 服务。
【 TiDB 版本】
v 6.5.0
【复现路径】
删除tikv的挂载盘
【遇到的问题:问题现象及影响】
vdbench IO出现跌零15s,客户端和集群相差13~14秒左右
【附件:截图/日志/监控】
tikv日志
监控
raft-election-timeout-ticks
这个参数设置的是多少?
我翻了下之前的帖子,总体感觉是原帖子里面那一套参数都要改的。
[raftstore]
raft-base-tick-interval = “1s”
raft-election-timeout-ticks = 3
raft-heartbeat-ticks = 1
pd-heartbeat-tick-interval = “5s”
raft-store-max-leader-lease = “2s”
如果你只改了pd-heartbeat-tick-interval,可能效果不明显。发起选举还是要10s左右。
raft-election-timeout-ticks默认是10.也就是无主状态10s后才会发起选举。
raft-store-max-leader-lease默认是9,也就是选为leader后最长9s内,不用选举,它都是leader。
raftstore.raft-election-timeout-ticks: 3
其他参数如下:
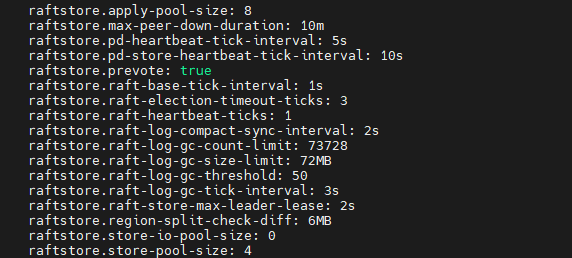
10:12:27左右才打印那个unreachable, 这个是不是发现故障的时间太久了,之后选举看差不多1~2秒的样子
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#grpc-keepalive-time
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#grpc-keepalive-timeout
我查了下,这个报错可能和上面这2个参数有关。
grpc-keepalive-time默认是10s。
grpc-keepalive-timeout默认是3s。
你之前的帖子写的是10:12:14出故障。
而10:12:27左右报这个错,确实是13s。和上面这两个参数的默认配置倒是能对的上。
如果真的是27报错之后才开始选举,可以考虑调低grpc-keepalive-time。timeout还是谨慎调整,怕出很多告警,半夜看到也挺吓人的。
从现有信息看,情况跟 kill 一个 tikv 节点后 IO 中断 10s 以上 类似
盘删除后 store 4 的 TiKV 挂掉了,但是 raft 未超时,因此部分 region 没有 leader,导致业务中断
可以参考 kill 一个 tikv 节点后 IO 中断 10s 以上 - #7,来自 pingyu 调整参数试试
[raftstore]
raft-base-tick-interval = "1s"
raft-election-timeout-ticks = 3
raft-heartbeat-ticks = 1
pd-heartbeat-tick-interval = "5s"
raft-store-max-leader-lease = "2s"
已经是这些参数了。我们还做了把tikv-server kill掉的用例,这个几秒就能恢复。从日志看区别在于下面这个打印的时间,kill tikv-server基本上马上就打印这个日志了。另外删盘操作这个,有时候跌零也只有6秒左右。
麻烦能给讲一下,这个报错之前都在干什么吗?这个报错是什么意思的?还有就是不是每次操作都是15秒,之前操作了两次,一次是12秒,一次是6秒。还有这个操作和直接kill tikv-server有什么不一样呢?kill tikv-server是恢复很快的,操作几次都是5秒以内。
采集一下 TiKV 和 PD 在删盘前后的监控和日志吧
听 @pingyu 的,他是专业的。