【 TiDB 使用环境】
生产环境 /测试/ Poc
【 TiDB 版本】
1.TiDB集群版本v5.4.0
2.TiCDC版本为v5.3.0 (v5.4.0不支持写s3,老版本v5.3.0支持)
/cdc version
Release Version: v5.3.0
Git Commit Hash: 8b816c9717a6d18430f93a6b212f3685c88d4607
Git Branch: HEAD
UTC Build Time: 2022-08-10 04:27:19
Go Version: go version go1.16.13 linux/amd64
Failpoint Build: false
【复现路径】做过哪些操作出现的问题
根据实践使用TiCDC在v5.4.0版本不支持写S3,使用V5.3.0旧版本支持同步到S3。
-
集群的基量数据在 TB级别,10万+ Region Leader,整个集群的写QPS在2k~3k左右,不算大。
-
启动TiCDC同步后,puller阶段一直在拉取数据,sorter 一直有数据进来但是没有出去,导致后续没有数据sink出去,即同步到S3的QPS观察到为0。任务拉起将近10个小时,看到sorter使用的内存逐渐升高并保持在16GB,当达到16GB后数据开始落盘,可以看到磁盘空间在不断上涨,当前磁盘已使用空间接近100GB,还有不断上涨的趋势。
-
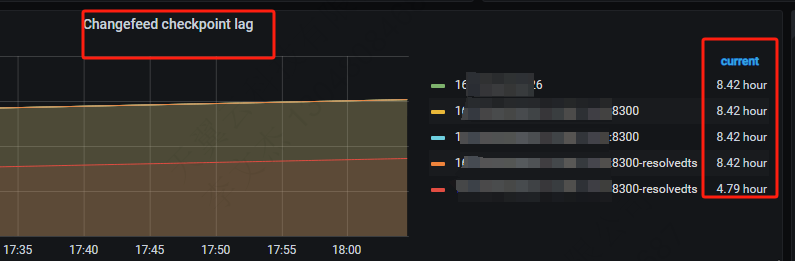
从 grfafna面板看到Dataflow各个阶段 event/s 为:
puller output(8300-kv为3k,8300-resolved为25万)–>> sorter output (event/s为0)–>> mounter output((event/s为0) -->> sink output(event/s为0) -
ticdc同步流的checkpoint一直卡在同步任务启动的时刻,没有推进过。对外就是一直有ticdc同步任务延迟告警。
-
运行过程中集群没有内存、CPU或IO的性能瓶颈,剩余资源充足。
-
集群有两个CDC节点,
一个节点不断有提示:[WARN] [schema_storage.go:733] [“GetSnapshot is taking too long, DDL puller stuck?”] [ts=449931778037383875] [duration=5h50m15.195304586s]。
另一个节点则不断刷出日志在磁盘上建立sorter的临时文件,文件名类似 sort-20197-33303.tmp,任务启动至今共创建了 3.5万个临时文件,且还在不断创建。 -
当前配置:
1)cdc-server的参数per-table-memory-quota配置为800MB,上游集群有80%的写流量集中在一个表。
2)当前同步任务配置:
{
"info": {
"sink-uri": "s3://tidb-backup/ixxxxx?endpoint=xxxx",
"opts": {},
"create-time": "2024-05-22T09:39:17.871399198+08:00",
"start-ts": 449928746197843972,
"target-ts": 0,
"admin-job-type": 0,
"sort-engine": "unified",
"sort-dir": "",
"config": {
"case-sensitive": true,
"enable-old-value": true,
"force-replicate": false,
"check-gc-safe-point": true,
"filter": {
"rules": [
"*.*"
],
"ignore-txn-start-ts": null
},
"mounter": {
"worker-num": 16
},
"sink": {
"dispatchers": null,
"protocol": "default"
},
"cyclic-replication": {
"enable": false,
"replica-id": 0,
"filter-replica-ids": null,
"id-buckets": 0,
"sync-ddl": false
},
"scheduler": {
"type": "table-number",
"polling-time": -1
},
"consistent": {
"level": "none",
"max-log-size": 64,
"flush-interval": 1000,
"storage": ""
}
},
"state": "normal",
"history": null,
"error": null,
"sync-point-enabled": false,
"sync-point-interval": 600000000000,
"creator-version": "v5.3.0"
},
该版本CDC之前在其他集群的优化经历:TiCDC双Sink同步增量备份到S3速度慢
在当前集群的这个场景下推测是有bug,按理来说应该是边拉取数据筛选,筛选结果直接输出给sorter及后续组件处理,即使数据量大,checkpoint也应该是缓慢更新的。
请问下大佬们有没有遇到过这种情况,如何处理?