现在删除了部分历史数据,空间使用了比较少,准备收缩掉几台tikv服务器, 收缩1个服务器1.4T数据需要多久完成这个怎么计算?
你先要看节点的Region数量,根据一定的时间范围减少的数量去进行计算,倘若觉得下线速度慢可以适当调整

1t怎么也得8小时左右吧。不怕影响性能的话 store limit 搞大一些,弄个200
“store-limit-mode”: “manual”, 这个吗?
这是当前的参数值:
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 3,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 2048,
“replica-schedule-limit”: 64,
“scheduler-max-waiting-operator”: 5,
“split-merge-interval”: “1h0m0s”,
“store-limit-mode”: “manual”,
“tolerant-size-ratio”: 0
每个Region有默认大小,Region的调度是PD进行的,当这个Store(TiKV节点)所有的Region和Leader被驱逐后,成为TomeStone状态才可以进行prune进行清理
store limit all 200,完事儿。
如果影响性能比较多,就 store limit 15 改回默认值。
先保存下当前的配置,在不影响集群性能的前提下
一方面可以更改下面的参数(你可以理解为消费者):
leader-schedule-limit、max-pending-peer-count、max-snapshot-count、max-snapshot-count、replica-schedule-limit、merge-schedule-limit
eg: config set 参数名 xxx
另一方面:(相当于生产者)
pd-ctl 输入 store limit ,调整 add-peer、remove-peer,
eg:store limit all 200
2 个赞
mark 一下,不着急还是等它慢慢来吧,仍在后台
悠着点,找个测试环境,测试一下默认情况下的速度。别把带宽都吃满了。稳字当头。
这个取决于服务器硬件吧,我们一般是开始缩容,然后看看监控,根据下降曲线大概就知道需要多久,如果时间太久,就调参数,加快缩容进度。
1 个赞
设备硬件是主要因素,但也包括调优
这个store limit all 200 是指的哪一部分? 是对应的 “store-limit-mode”: “manual”,这个吗?
你说的看下降曲线是哪个?tikv的对应缩容的ip的存储空间曲线图??
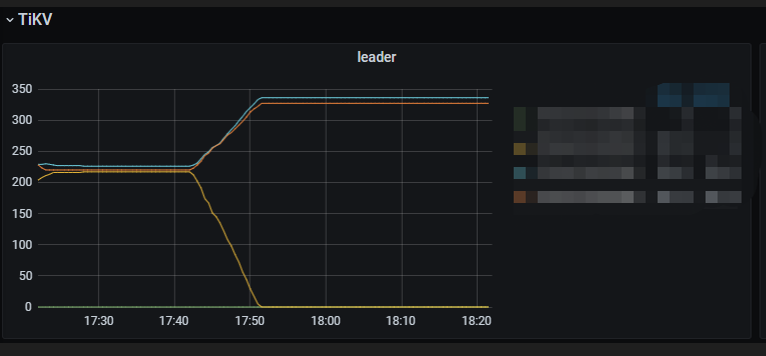
2 个赞
Store Limit | PingCAP 文档中心
store limit 看下这里的文档
leader下降为0 说明里面没有leadder了可以直接下线了吗?我刚看到我这边有一个tikv节点是 0 leader,region是和其他tikv一样的。这个意思是说这个节点没有一个region是leader是吗?都是副本是这个意思吗?
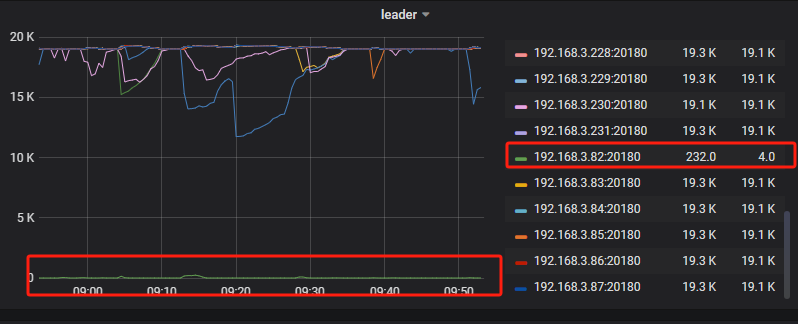
谢谢我去看看
大概多久求分享
不是不是,这个只是我当时的图没有了,找了个网图。应该是看leader和region都没有了。如果驱逐leader,节点的leader也可能为0。
1 个赞