vcdog
(Vcdog)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.0
【复现路径】tiflash加载的几张表,单张超1.5亿的表,进行数据查询时,执行计划走了tiflash,但是,查询比平时慢2倍以上
【遇到的问题:问题现象及影响】tiflash加载的几张表,单张超1.5亿的表,进行数据查询时,执行计划走了tiflash,但是,查询比平时慢2倍以上
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
tiflash的2个节点内存消耗也在50%以下,且日志里也没有异常信息。
这种情况,如何排查。当时的临时解决办法是,重启tiflash。
有猫万事足
5
hashagg都在tidb上做的。tiflash只做了scan当然还不如以前。
开mpp。想办法把hashagg放到tiflash上做。
https://docs.pingcap.com/zh/tidb/stable/use-tiflash-mpp-mode
vcdog
(Vcdog)
9
当时,也怀疑是不是IO的问题,但是,查看io监控也没有发现相关问题
有猫万事足
10
已经开了mpp的情况下,不走mpp,会有warning,
show warnings;
可以看到不走mpp的原因。
托马斯滑板鞋
(托马斯滑板鞋)
11
下次如果还慢,贴个 trace select xxxx 的耗时
wenyi
(Wenyi)
12
正常出结果的执行计划,麻烦贴一个,看一下hashagg在tiflash,还是在tidb上
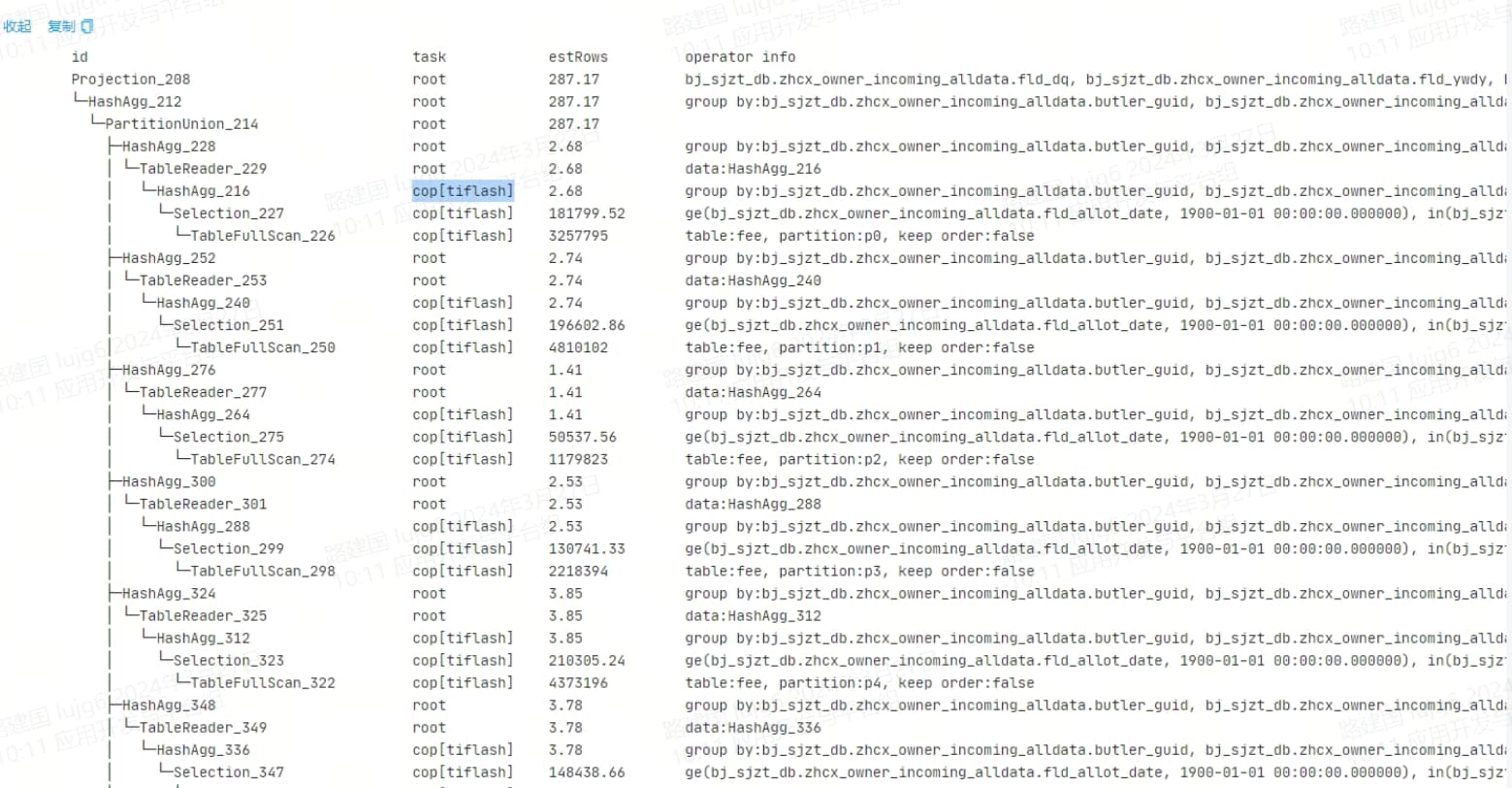
这个不是在tiflash上进行的hashagg吗?
有猫万事足
16
https://docs.pingcap.com/zh/tidb/stable/partitioned-table#动态裁剪模式
怀疑是没有打开动态分区裁剪,导致hashagg有一部分没有办法在tiflash上做。
可以看到执行计划里面有在 PartitionUnion后就分了很多段。
vcdog
(Vcdog)
17
是的,我看了下,还是在tiflash上进行的hashagg,但是,重启tiflash后,确实比原来快很多。我再看下大佬的那个文档,试试看能不能让hashagg到tidb上进行。
vcdog
(Vcdog)
18
如果把hashagg放到tidb上进行,压力是不是又给到tidb,会不会出现OOM呢
有猫万事足
19
说的好,如果是大表这就是风险点。
所以AP的sql最好的情况就是全部交给tiflash做。tidb直接拿结果。这样就算出问题,也不影响TP业务。
不,你现在等于是在tiflash上进行了hashagg,但是后面又在tidb上进行了一次hashagg,也就是没有启动mpp功能,如果启用mpp,应该通过tiflash能够直接hashagg出结果。但是我感觉,你现在的sql慢和mpp关系应该不大,即使开启mpp,效率不见得会提升很大,从你正常的执行计划看,也是没有启用mpp功能的。