CREATE TABLE ServiceFlowKpiRecords (
node_id_str varchar(100) NOT NULL COMMENT ‘设备的hostname,为设备在网络中的唯一标识’,
subscription_id_str varchar(100) NOT NULL COMMENT ‘订阅名称’,
collection_id bigint(20) unsigned NOT NULL COMMENT ‘标识采样轮次’,
collection_start_time datetime NOT NULL COMMENT ‘标识采样轮次开始时间’,
name varchar(100) DEFAULT NULL COMMENT ‘//vlan id’,
channel varchar(100) DEFAULT NULL,
index int(10) unsigned DEFAULT NULL,
downstream_flow_drop_cnt bigint(20) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流丢包总数’,
downstream_flow_pass_cnt bigint(20) unsigned DEFAULT NULL COMMENT ‘//下行方向入业务流通过的总包数’,
downstream_flow_drop_max int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流秒级丢包最大数’,
downstream_flow_drop_min int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流秒级丢包最小数’,
downstream_flow_drop_rate_max int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流秒级丢包最大丢包率,单位:10^-5’,
downstream_flow_drop_rate_min int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流秒级丢包最小丢包率,单位:10^-5’,
downstream_flow_drop_seconds_cnt int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流发生丢包的秒数的累加’,
downstream_flow_pass_bytes bigint(20) unsigned DEFAULT NULL COMMENT ‘//下行方向业务流通过的字节数’,
downstream_mfr_avg int(10) unsigned DEFAULT NULL COMMENT ‘//下行方向平均速率,kbps’,
upstream_pass_bytes bigint(20) unsigned DEFAULT NULL COMMENT ‘//上行方向通过的字节数’,
upstream_pass_cnt bigint(20) unsigned DEFAULT NULL COMMENT ‘//上行方向通过的总包数’,
upstream_drop_cnt bigint(20) unsigned DEFAULT NULL COMMENT ‘//上行方向丢包总数’
)
PARTITION BY RANGE COLUMNS (collection_start_time) INTERVAL (60 SECOND) FIRST PARTITION LESS THAN (‘2024-02-21 00:00:00’) LAST PARTITION LESS THAN (‘2024-02-28 00:00:00’);
按照以上的建表语句,写入的数据是按照collection_start_time时间递增的
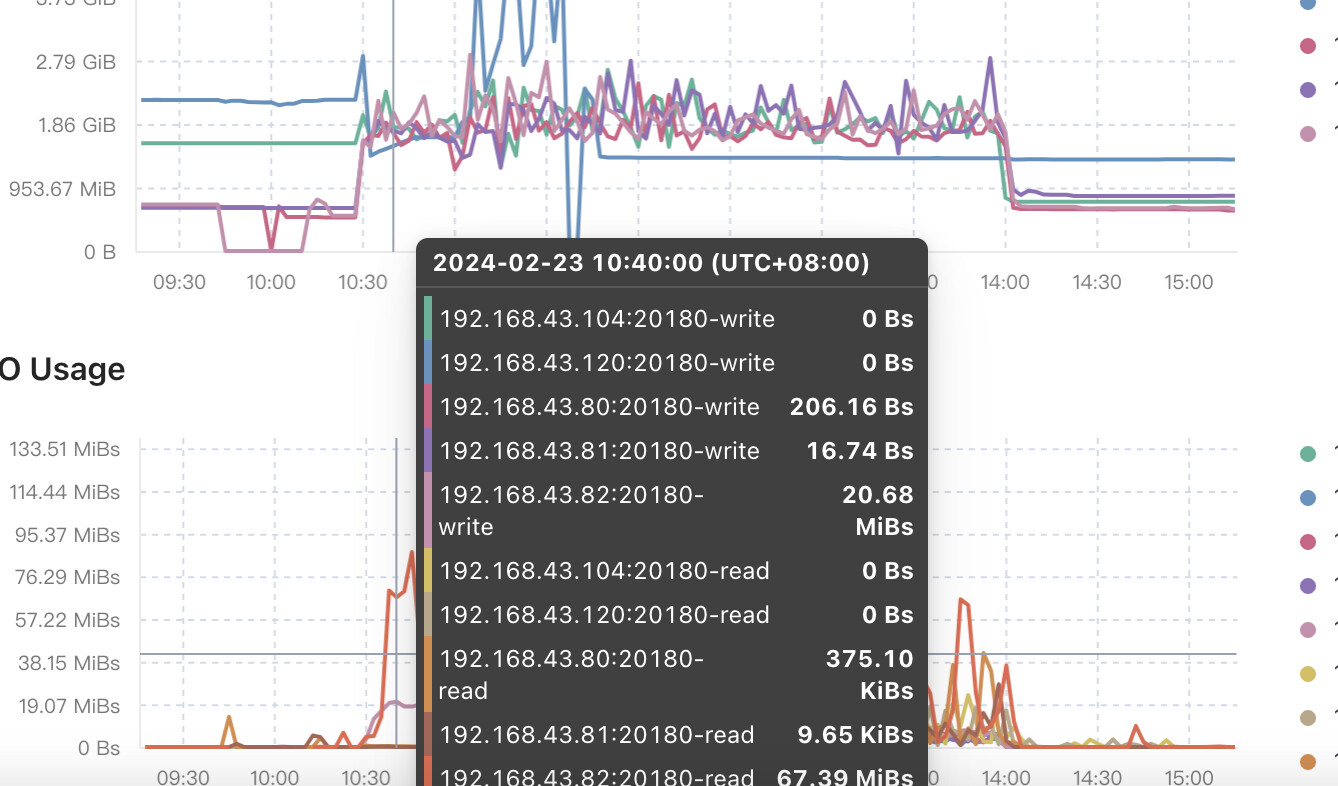
这个很正常,要写的region主要分布在其中一个tikv上。
多写一些,当region分裂以后,再迁移到其他节点,逐渐就不会有热点了。
可以预先增加region数吗,提前让region分裂
可以试试这个,不过你这个tikv的压力会很大吗?有必要这样做吗?
https://docs.pingcap.com/zh/tidb/v7.1/shard-row-id-bits?_gl=1*18nruq9*_ga*MTQ4NzE5MDkyOC4xNzA4MjUwODAw*_ga_3JVXJ41175*MTcwODY3NDY2Ni4xMy4xLjE3MDg2NzQ2NzYuNTAuMC4w#shard_row_id_bits
像你这种非聚簇索引表,会默认生成_tidb_rowid,这个默认确实会造成写热点,可以设置SHARD_ROW_ID_BITS 来缓解
https://docs.pingcap.com/zh/tidb/v7.1/high-concurrency-best-practices#更复杂的热点问题
如果表没有主键或者主键不是整数类型,而且用户也不想自己生成一个随机分布的主键 ID 的话,TiDB 内部有一个隐式的 _tidb_rowid 列作为行 ID。在不使用 SHARD_ROW_ID_BITS 的情况下,_tidb_rowid 列的值基本也为单调递增,此时也会有写热点存在(参阅 SHARD_ROW_ID_BITS 的详细说明)。
要避免由 _tidb_rowid 带来的写入热点问题,可以在建表时,使用 SHARD_ROW_ID_BITS 和 PRE_SPLIT_REGIONS 这两个建表选项(参阅 PRE_SPLIT_REGIONS 的详细说明)。
SHARD_ROW_ID_BITS 用于将 _tidb_rowid 列生成的行 ID 随机打散。PRE_SPLIT_REGIONS 用于在建完表后预先进行 Split region。
有尝试增加了上面的2个参数,还是存在数据热点问题。我看了官网文档,shard_row_id_bits = 4 PRE_SPLIT_REGIONS = 4只适用于非分区表吧。你看我的表结构是按照时间做range分区的。
这表没主键吗,没主键在7.5.0这个版本应该比有主键的写入速度慢不少
官方应该没有说分区表不能预分配region吧,你在哪里看的,可以贴个连接吗?
没有,只是我看的官网取得例子shard_row_id_bits /PRE_SPLIT_REGIONS建表都是非分区表
我尝试增加主键,再验证下
按最佳实践,加个AUTO_RANDOM主键
我加了主键的话,提示分区信息中必须包含主键。但是我业务中只需要按照时间分区就可以了。
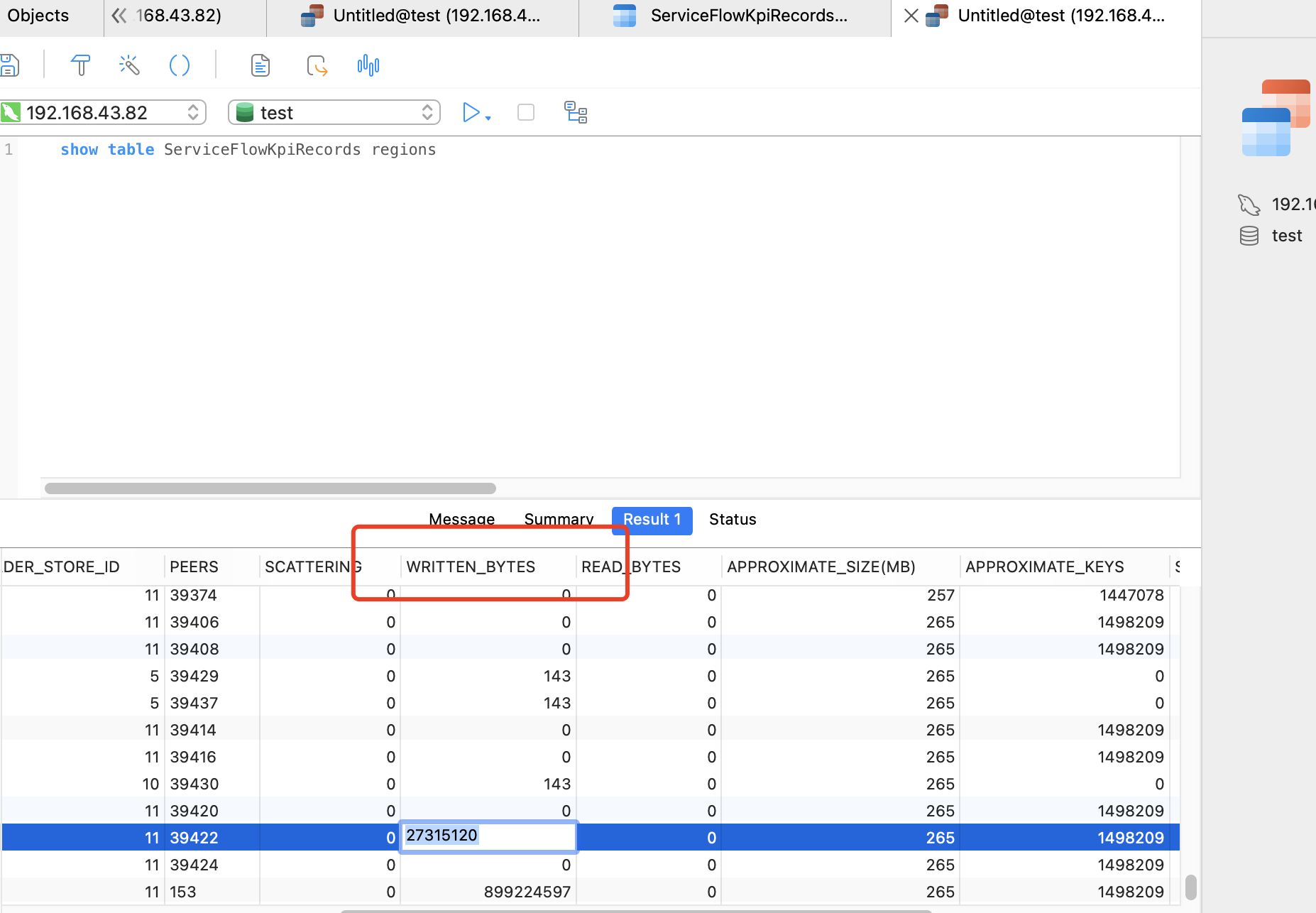
分区表是麻烦一些,自增和分区键都必须放主键,你有加其他索引吗
没有,可以看下我问题描述主干的ddl语句。一个key/索引都没加。
我们分区主要是因为数据量太大了,所以分成了1分钟的单位。不然查询又会很慢。
我建议是创建一个collection_start_time的索引,然后改成每月一个分区。
