【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
无
【遇到的问题:问题现象及影响】
集群运行中,突然挂了一台tikv
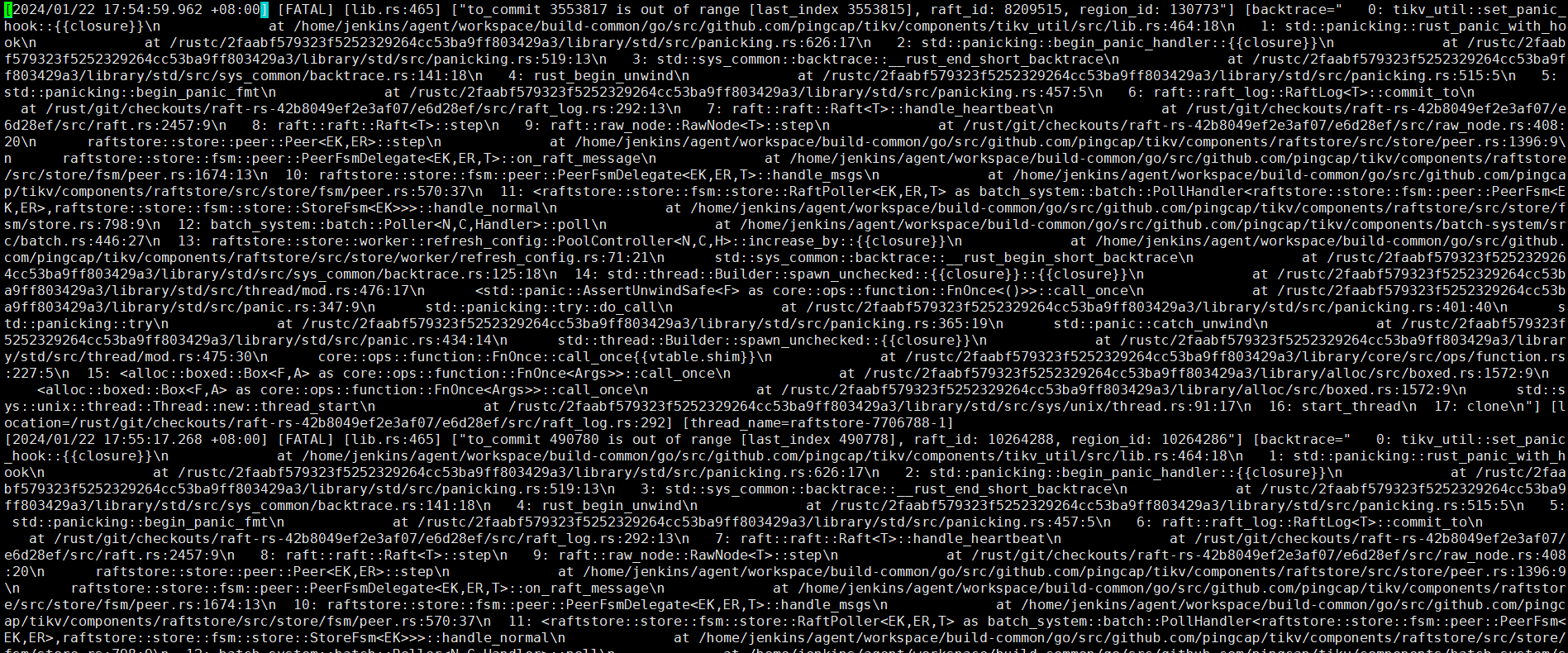
[2024/01/22 17:54:59.962 +08:00] [FATAL] [lib.rs:465] [“to_commit 3553817 is out of range [last_index 3553815], raft_id: 8209515, region_id: 130773”] [backtrace=" 0: tikv_util::set_panic_hook::{{closure}}\n at /home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tikv/components/tikv_util/src/lib.rs:464:18\n
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
这种八成是bug,去github查查是不是bug,你的集群版本也挺老了
稍微感觉懵逼。不明白什么情况,感觉自己拉取的代码,打的包部署的坏境?
集群是正常运行状态突然掉了一个节点吗,还是其他情况下出现的问题?
tidb 的打包也是集成在了jenkins
跟这个没关系,这个是2年不重启的bug,题主这个应该是其他bug
v5.4.2感觉 不老啊。生产环境不好升级。我看到有别的贴子有同样问题。
官方,tiup安装部署的生产环境
跟这个 周五的暴击:TiKV 节点宕机无法正常启动之后
还有这个有点像 Tikv节点挂掉后,启动报错“[region 32] 33 to_commit 405937 is out of range [last_index 405933]”
集群正常运行状态下突然掉了一个tikv节点,起不来。查看节点的tikv_stderr.log日志有此报错。
直接缩容然后再扩容呗,省的纠结
region 130773 有问题了,删掉这个peer修一下吧。
pd-ctl>> operator add remove-peer <region_id> <store_id>
然后再用 tikv-ctl 在那个 TiKV 实例上将 Region 的副本标记为 tombstone 以便跳过启动时对他的健康检查:
tikv-ctl --data-dir /path/to/tikv tombstone -p 127.0.0.1:2379 -r <region_id>
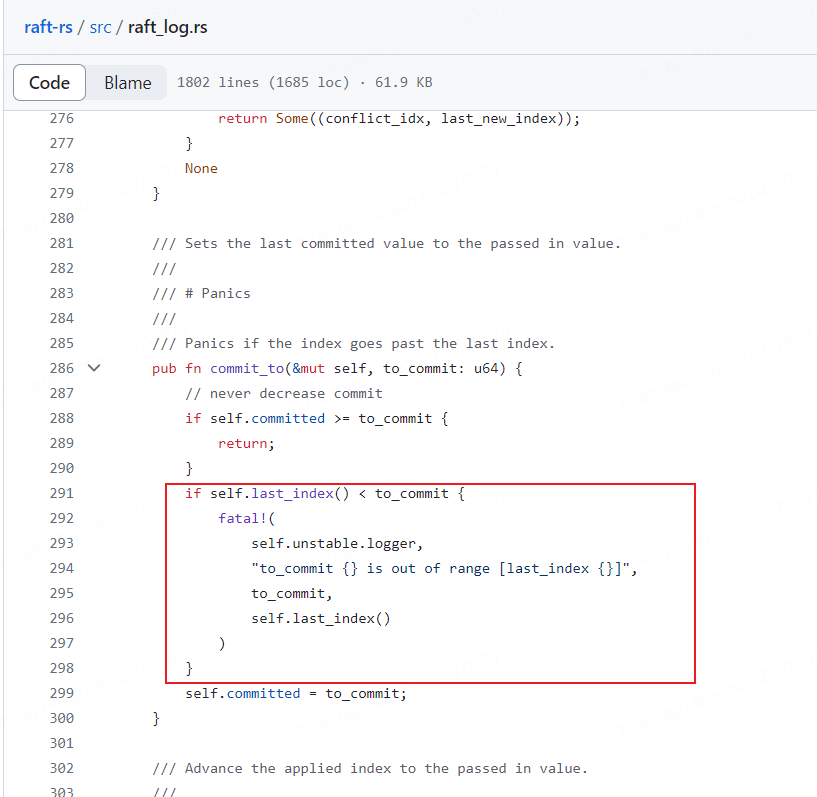
这个意思大概就是:这个节点的日志到了last_index,但是要让提交到commit,这个commit超了本地的日志。就panic了。
这节点都掉了,还能执行缩容吗?是要强制?
尝试删,越删越多,删的速度赶不上增加的。是不是应该要怎么样先停掉节点?如何停?
不止一个region报错?那你直接这个节点删掉吧。物理销毁。
然后在pd那里执行store delete xxx,删掉这个store。等这个store变成tombstone后,把上面的tikv目录删掉,重新拉其一个就行了。
前提是你这个集群只有一个故障的tikv哈,如果大于一个,很可能丢多副本,上面的操作就不适用了。
用这个方式处理恢复了。 设置一个 Region 副本为 tombstone 状态
2 个赞
学习到了
可以强制缩容的
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。