【 TiDB 使用环境】生产环境
【 TiDB 版本】5.3.3
【复现路径】
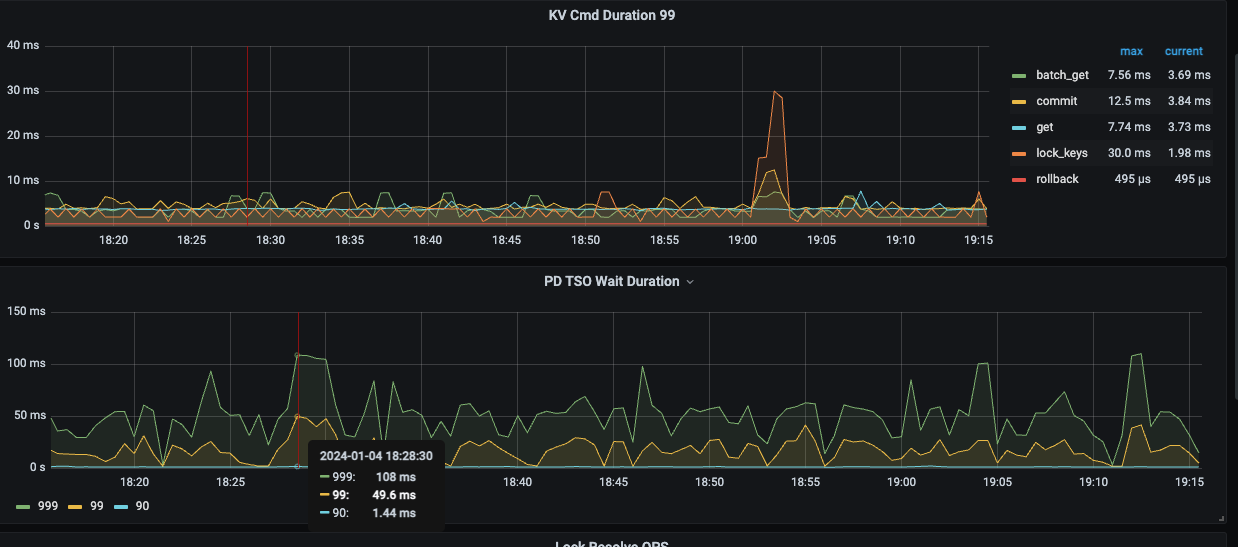
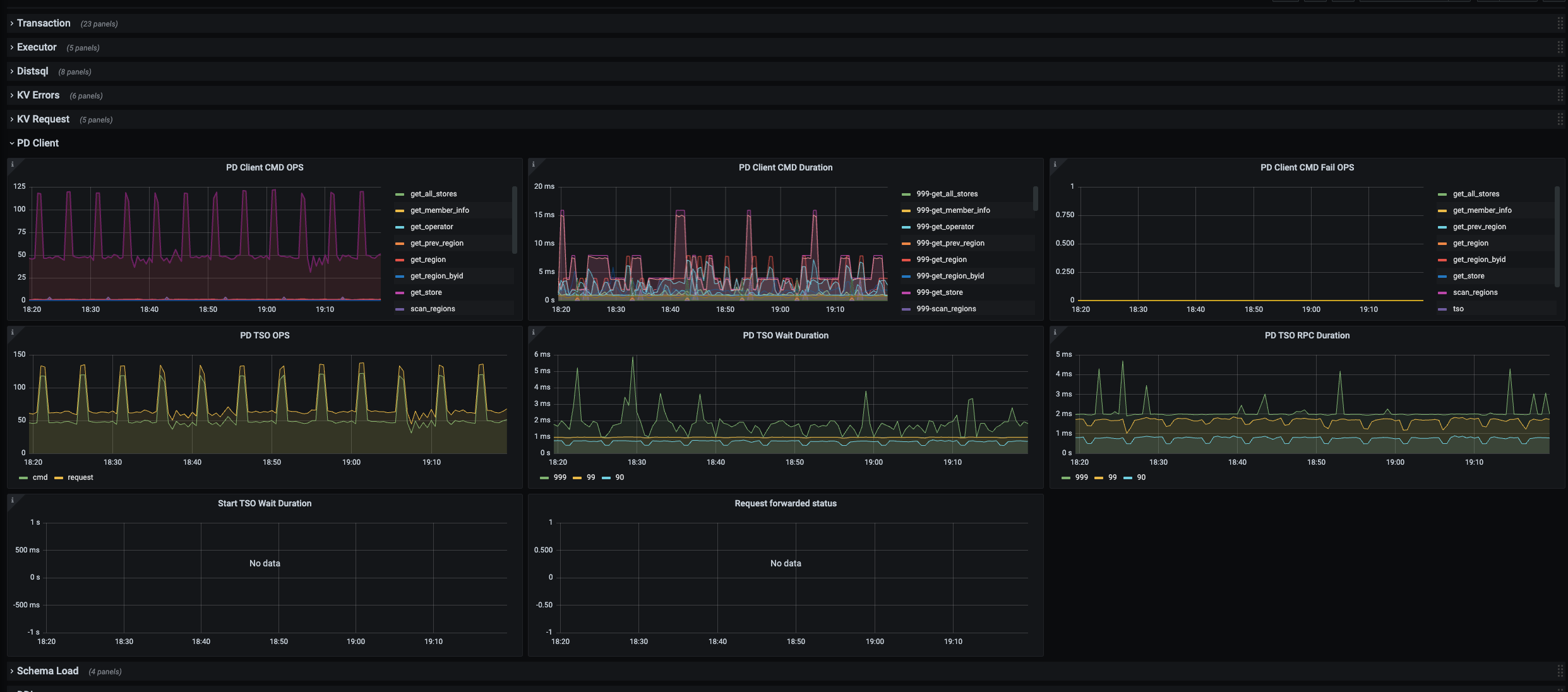
重启tidb-server后,获取tso时间会恢复。但是随着时间的推移,到大概一周以后,获取tso时间99线会从大概1左右毫秒大概升高到30毫秒左右,999线会20毫秒升高到60毫秒,后续还会接着升高。
【影响】会产生慢查询,获取tso的时间升高。
【资源配置】资源配置都是64c 512G nvme盘
最近1个小时tso截图:
最近7天的获取tso截图:
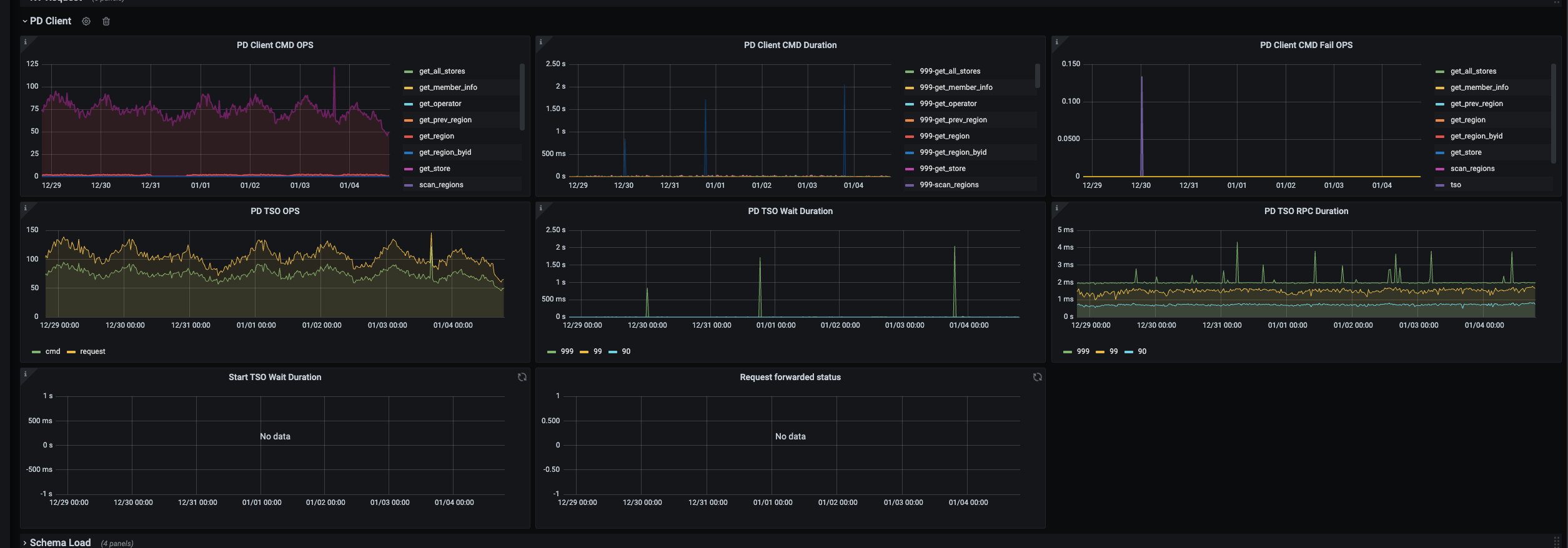
最近1个小时的tidb-pdclient获取tso截图:
最近7天的tidb-pdclient获取tso截图:
确认一下tidb有没有pd client访问的异常日志,另外检查一下网络的延迟情况是否正常
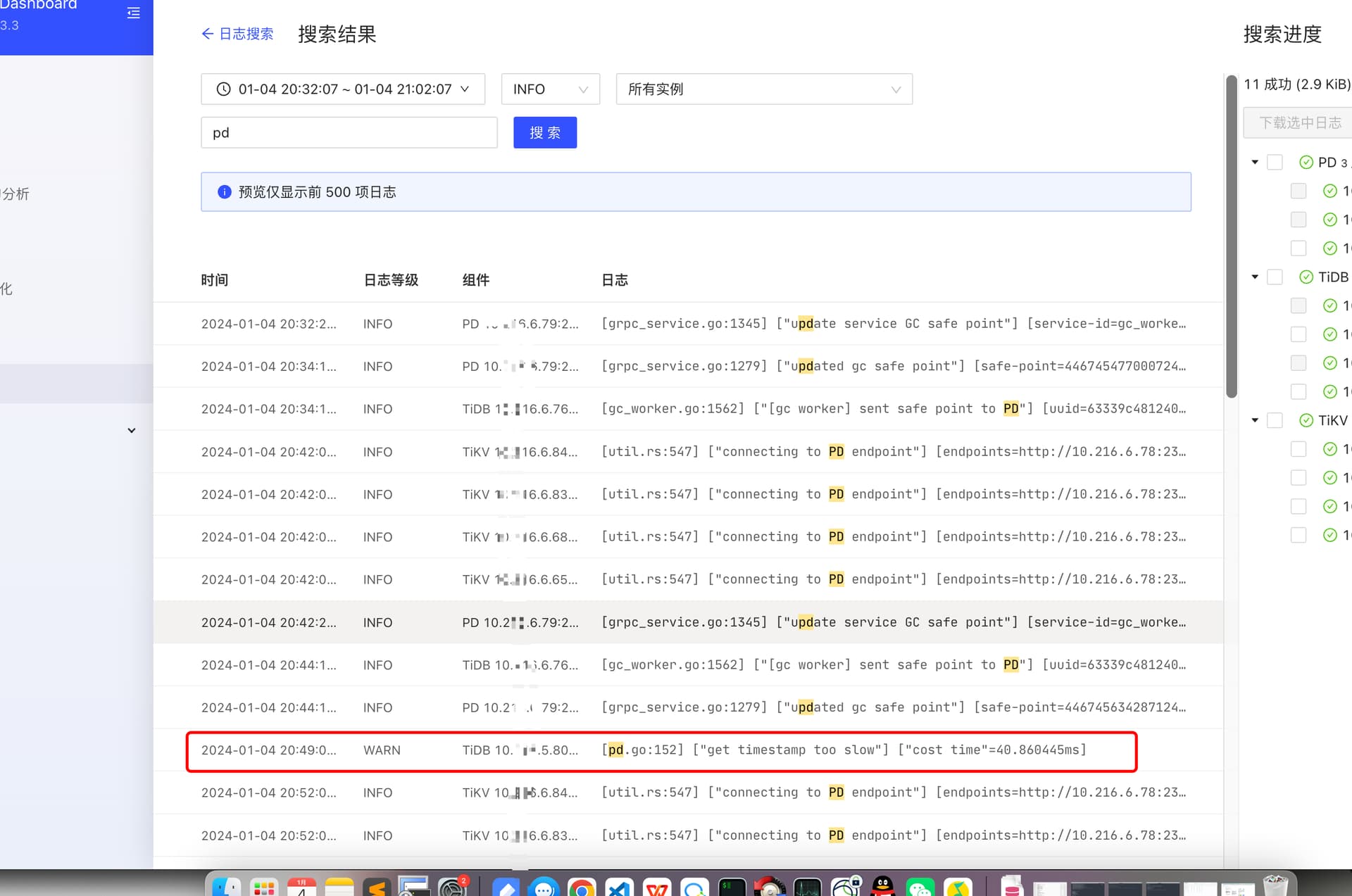
搜索关于pd的日志:
[pd.go:152] [“get timestamp too slow”] [“cost time”=40.860445ms]
网络延迟,ping值都很正常。还有其他tidb集群也在这个机房,都比较正常,就这一个集群不太正常。
确认一下pd leader 节点所在机器的CPU情况
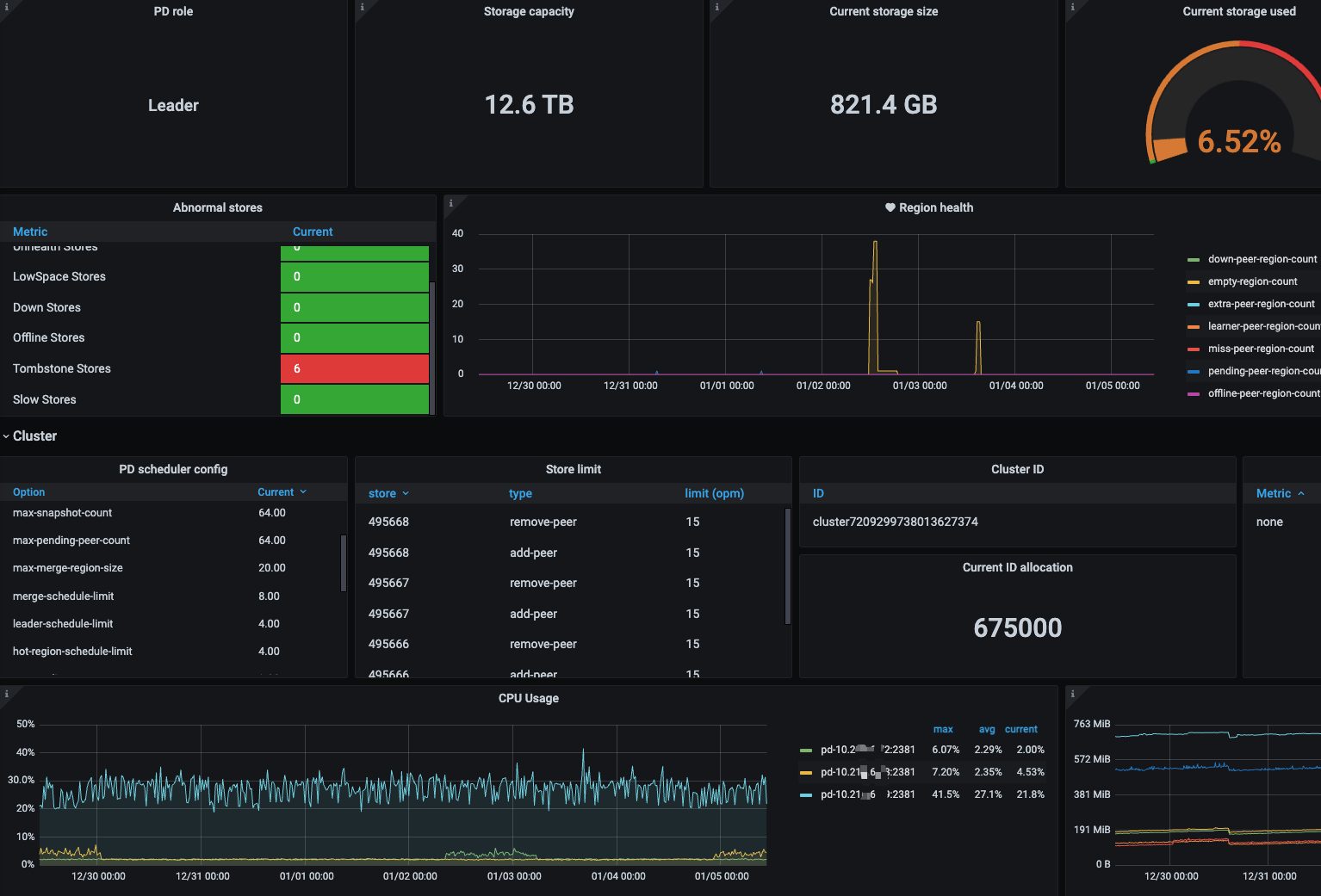
pd和tidb节点的cpu使用率都不高。
pd节点最近7天cpu使用率:
tidb节点最近7天cpu使用率:
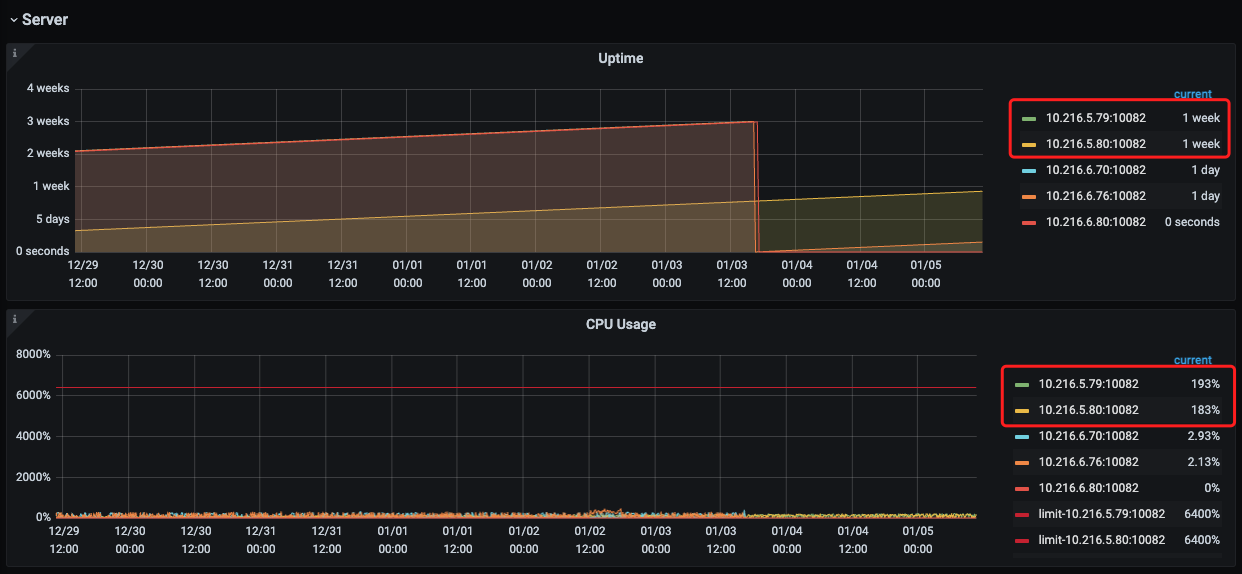
监控中上面2个tidb节点在业务使用的,下面3个tidb-server节点不在业务使用,是为了排查问题,现在临时加上去的。
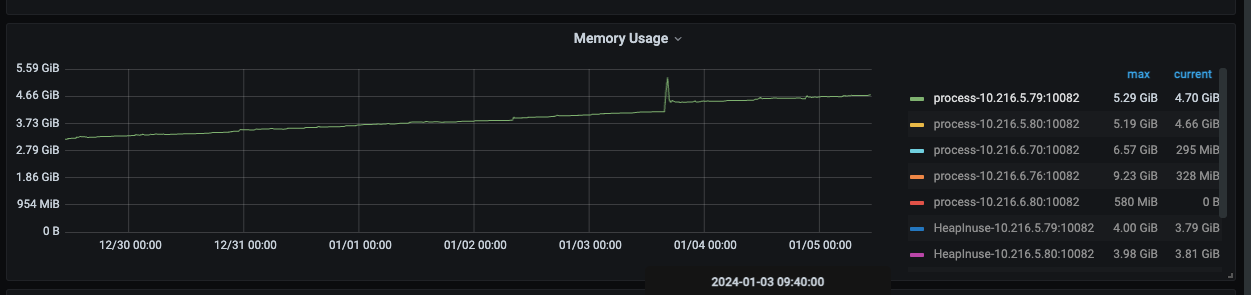
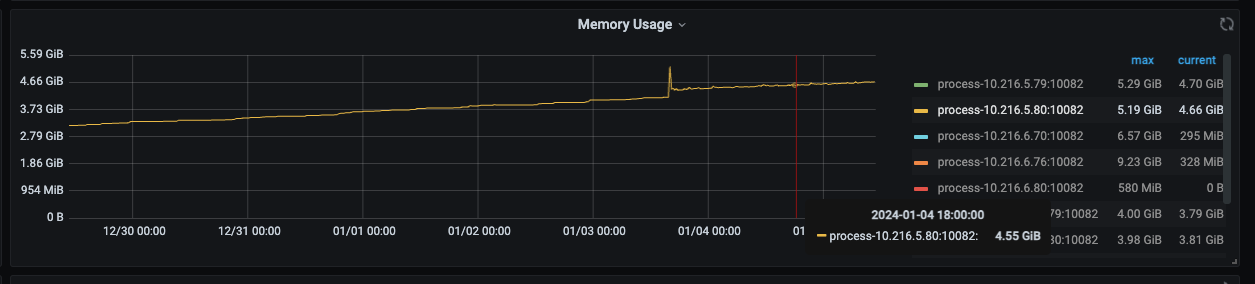
另外,我从监控中发现,tidb-server节点如果cpu 使用率和内存使用率重启以后也会缓慢升高;然而业务并没有变化。
内存7天变化:
cpu 7天变化:
这里有个处理指引,从这三个方向出发,依次排除。上面你已经排查过网络的问题,确认正常,可以重点分析一下 PD 或 TiDB 卡的问题。
网络慢了
首先立马查看 PD TSO RPC Duration,其正常数值范围 80% 差不多在 1ms 以内,99% 在 4ms 内,如果数值比较高,则说明网络和 PD 的处理时间长(包括 Go Runtime 调度和实际 TSO 处理逻辑),此时继续看 PD server TSO handle time + Client revc time 是否慢,如果不慢则说明 PD TSO 处理(和发送)不慢,大概率是网络问题,需要往网络问题方向排查。
PD 卡了
如果 PD server TSO handle time + Client revc time 慢:
- 如果是 v4.0.13 版本及以后,由于这个监控其实只包括了 PD leader 处理 TSO 时间,所以它慢说明 PD TSO 处理的慢,此时应该考察 PD Leader 的 CPU 占用情况是否较高?以及是否存在混布(混合部署)的情况,即同一台机器上有其他的进程或操作扰乱了 PD 的计算,影响了 TSO 的处理速度。
- 如果是 v4.0.13 版本之前(不包括),那么说明 PD leader 处理 TSO 时间慢或回传给客户端的发送时间慢或两者都比较慢,需要同时考虑上述 PD CPU 问题以及 PD 到 TiDB 之间的网络问题。
还有一个情况也会影响到 PD 的 TSO 分配——PD 出现了 leader 切换,不过一般出现 leader 切换,直接会导致 TSO 不可用,并不能是让 TSO 变慢的原因,只在此一提,仅供参考。
TiDB 卡了
如果顺利排除了网络问题和 PD 问题,那么疑点又回到了 TiDB 这边。由于 TSO 的后台处理流程和 TiDB 的 Parser 以及 Complie 生成 Plan 是同时进行的,遇到高强度的 Workload 和一些较为复杂的查询时,可能会消耗大量的资源,影响到 Wait 操作(里面使用了 select 语句以及 channel,涉及到 Go 的调度),此时可以来到 TiDB 的 Execution 监控面板,看看 Parse,Complie 和 Execute 的耗时。
嗯,这篇排查获取tso慢点文章我看了很多遍。目前初步定位是tidb-server的问题,重启能够暂时解决,但是只能维持一个周。所以具体是什么问题,还想要得出具体的排查指引
目前来看确实是tidb-server的问题,重启能够暂时解决。目前感觉像是内存泄漏导致的,内存逐渐升高,导致获取tso变慢。
WalterWj
(王军 - PingCAP)
17
你这个描述。。。。我怎么感觉 tidb-server go routine 溢出了。。。。 你看下 goroutine 线程数是不是一直再涨。监控里面有。
后面根据建议,设置tidb_analyze_version=1;tidb-server内存还是持续增长
抓取了下 tidb-server节点的heap memory.
new_heap.profile (1.1 MB)