【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
上游tidb版本6.1.1,ticdc也同样6.1.1
下游tidb版本 v7.1.2
【复现路径】做过哪些操作出现的问题
两个tidb集群都是用物理机ssd盘,下游tidb没有任何请求,上游会有业务请求,两个集群ping延迟在50ms
目前想把上游的数据全量迁移到下游tidb,已经使用了dumpling+tidb-light的方式全量同步了,全量完成后大概有一天的增量数据使用ticdc同步。
同步的数据是3个库,使用2个ticdc任务来同步,其中一个大库单独使用一个ticdc进程
【遇到的问题:问题现象及影响】
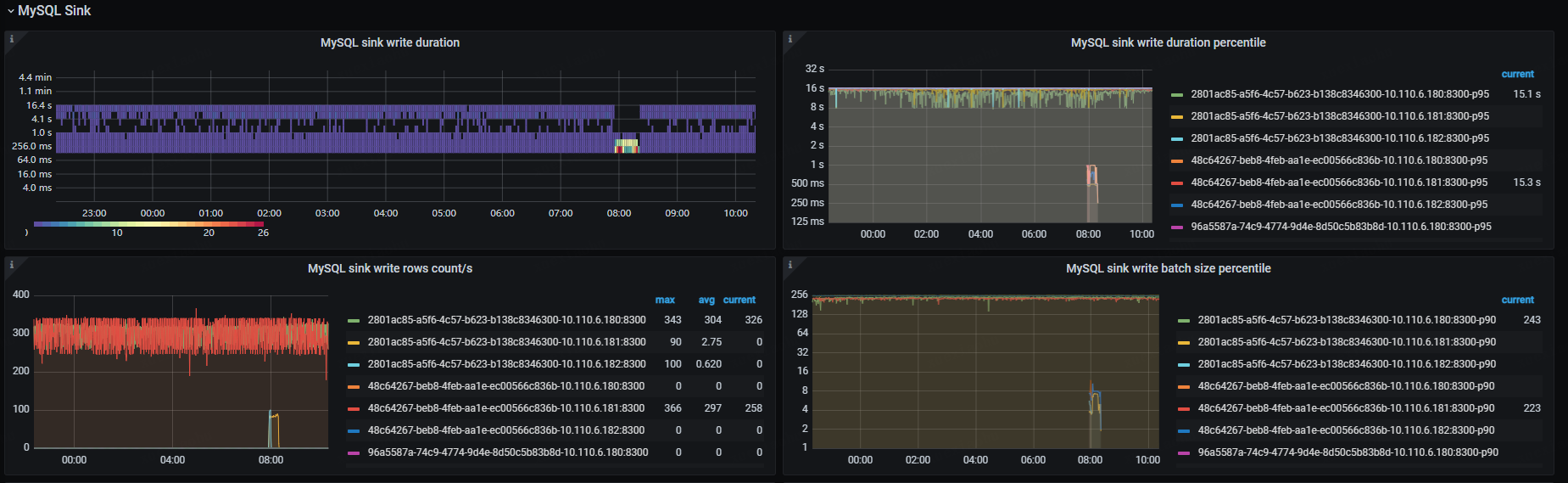
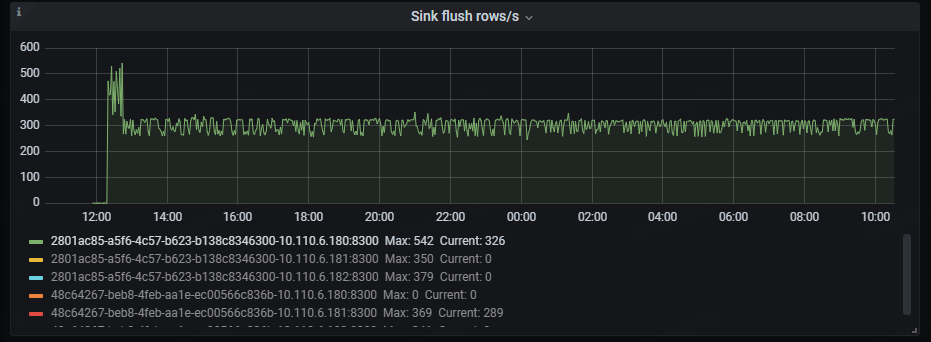
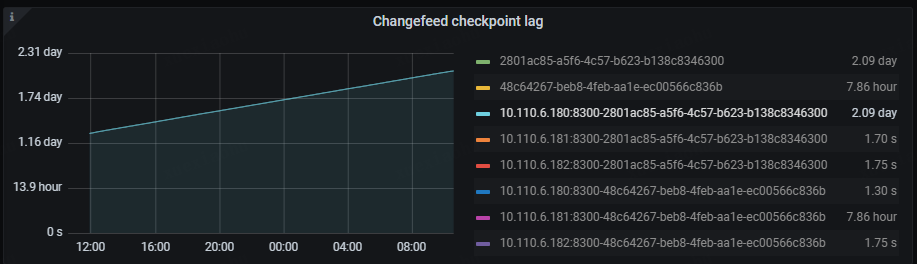
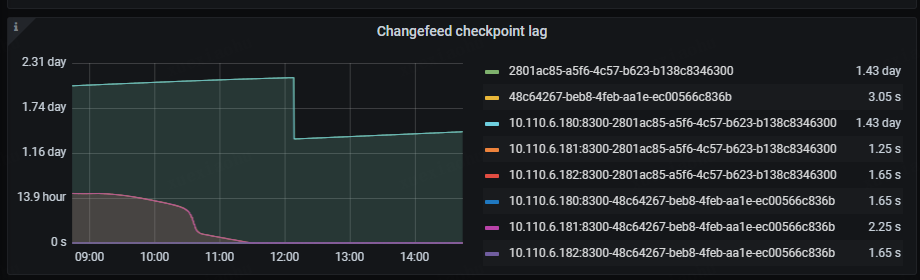
目前的问题是大库的那个ticdc进程同步非常缓慢,完全跟不上上游业务的数据增量,Changefeed checkpoint lag越来越大。
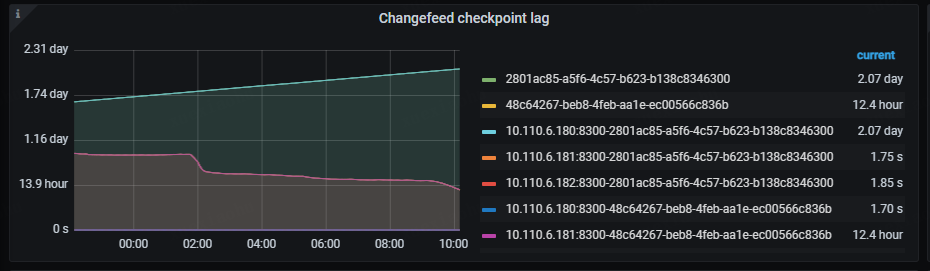
- Changefeed checkpoint lag:这个指标代表上游 TiDB 集群和下游系统之间的数据复制延迟,延迟以时间为单位。该指标反映了 Changefeed 整体的数据同步状况是否健康,通常情况下,lag 越小,说明同步任务状态越好。而当 lag 上升时,通常说明 Changefeed 的同步能力或者下游系统的消费能力无法匹配上游的写入速度。
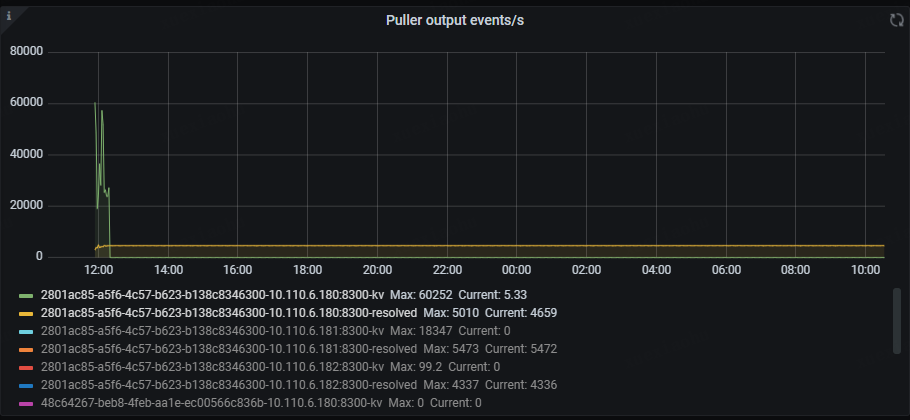
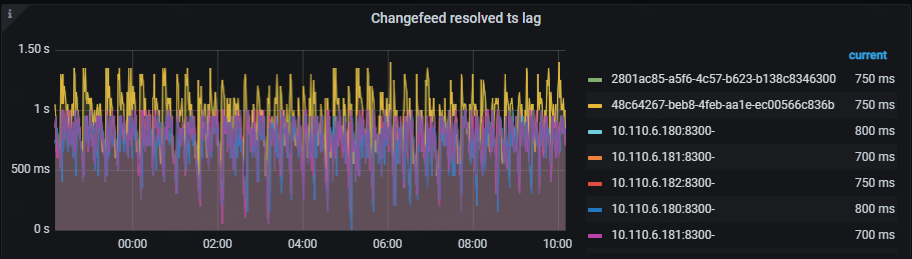
- Changefeed resolved ts lag:这个指标代表了上游 TiDB 集群与 TiCDC 节点之间的数据延迟,延迟以时间为单位。该指标能够反映 Changefeed 拉取上游数据变更的能力,当 lag 上升时,说明 Changefeed 无法及时地拉取上游产生的数据变更。
还有一个点是大库的ticdc进程,其中一个ticdc节点是跟得上的,checkpoint lag保持在2秒,另一个节点则几小时了才同步几分钟
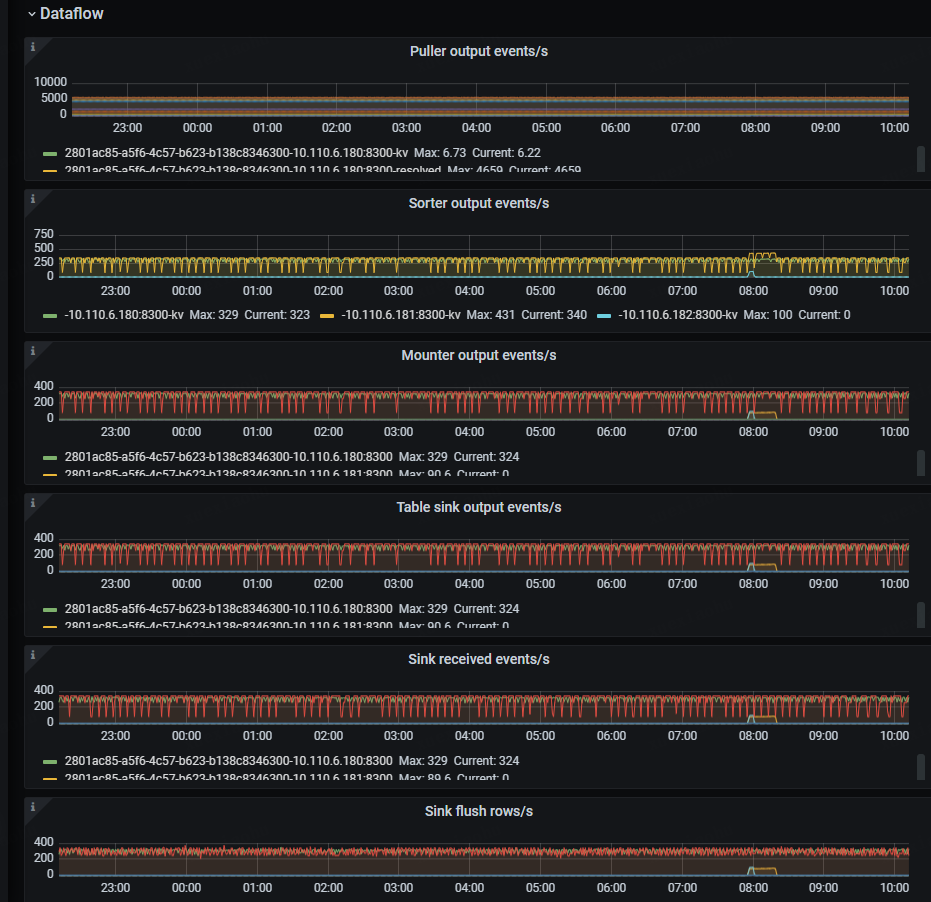
目前看日志没有什么异常,下游的集群负载也很低
ticdc配置如下,其他的都是用默认
force-replicate = true
[mounter]
worker-num = 16
我想知道这是什么原因,有什么可以优化的地方吗
是不是两个集群延迟50ms有关
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】