【 TiDB 使用环境】
生产环境 /测试/ Poc
【 TiDB 版本】
1.TiDB集群版本v5.4.0
2.TiCDC版本为v5.3.0 (v5.4.0 暂不支持写s3,故用回老版本v5.3.0)
/cdc version
Release Version: v5.3.0
Git Commit Hash: 8b816c9717a6d18430f93a6b212f3685c88d4607
Git Branch: HEAD
UTC Build Time: 2022-08-10 04:27:19
Go Version: go version go1.16.13 linux/amd64
Failpoint Build: false
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
1.在一个集群里先是部署了主从集群同步,前期经过TiCDC的调优把sink TiDB的QPS从5k优化到最高支持45k左右,TiDB集群主从同步不存在瓶颈。
2.接着在相同的集群上,再开启一个新changefeed实现增量备份到S3,以满足不同场景的备份需求。
新创建一个TiCDC到S3的增量同步任务,该任务的同步QPS只有4.5k左右,而相同库表的主从同步能达到27k。
从配置任务来看,上游是完全相同的表,这两个任务的前面的puller、sorter、mouter都相同,有差异的地方是在cdc sink。
https://docs.pingcap.com/zh/tidb/stable/ticdc-sink-to-cloud-storage
官方这里说到从 TiDB v6.5.0 开始TiCDC 支持将行变更事件保存至存储服务 S3。
根据实践使用TiCDC在v5.4.0版本不支持写S3,我们使用V5.3.0旧版本能够支持写,目前实际使用中同步到S3的QPS在 4k-5k之间。
尝试的优化:
1)网络优化,确认在TiCDC节点到S3之间的写延迟大概在100ms以下,应该不存在网络延迟过高的问题。
2)参考【s3://bucket/prefix?worker-count=128&flush-interval=1m30s&file-size=33554432
】,通过调整worker-count等参数并未能提高同步到S3的速度。
3)扩容TiCDC节点,同步速度没有明显提升。

运行过程中集群没有内存、CPU或IO的性能瓶颈,想了解一下大佬们有没有其他办法在该版本下提高写S3的效率。
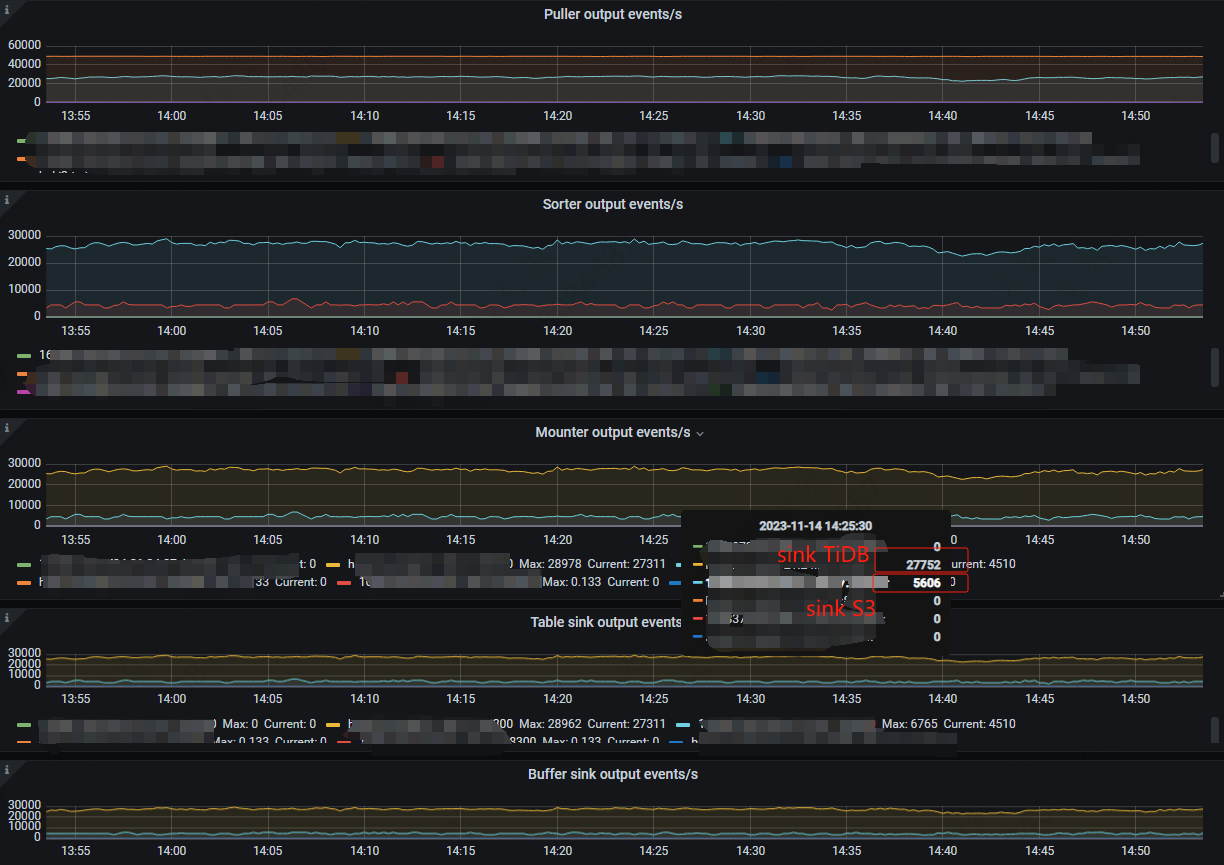
比如在同步落后追数据时,可以看到一组对比数据:
对于主从同步Sink TiDB:puller (xxx:8300-resolved 48k,xxx:8300-kv 25k)->sorter (36k)->mounter (36k)->sink (35k)。
对于增量备份Sink S3:puller (xxx:8300-resolved 48k,xxx:8300-kv 25k)->sorter (4.5k)->mounter (4.5k)->sink (4.5k)
怀疑的地方在在sorter这里比较慢,目前per-table-memory-quota配置了100MB。
【资源配置】
资源配置如下:
CPU:amd64,56 (112 vCore)
内存:512GB
磁盘:2.9TB的NVME
万兆网卡
Linux 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
在使用中TiCDC和PD暂时混部,集群部署了3个TiCDC节点,单机部署2个TiKV,在测试和使用过程中排查机器资源充足,不不存在资源瓶颈。