【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.1.5
【复现路径】一直就是这现象
【遇到的问题:问题现象及影响】
从监控来看,tikv 节点的 inbound 网络流量最大能达到 20.91MB/s,最小 4.74MB/s,一天有近 300G+。但实际该 tikv 的存储只增加了 16G,流量异常的大。看调度任务也没看出有什么异常,有大佬知道再怎么进一步排查呢
[dmall_rdp_voucher-PD - Grafana (2023_11_15 16_03_34).html|attachment]
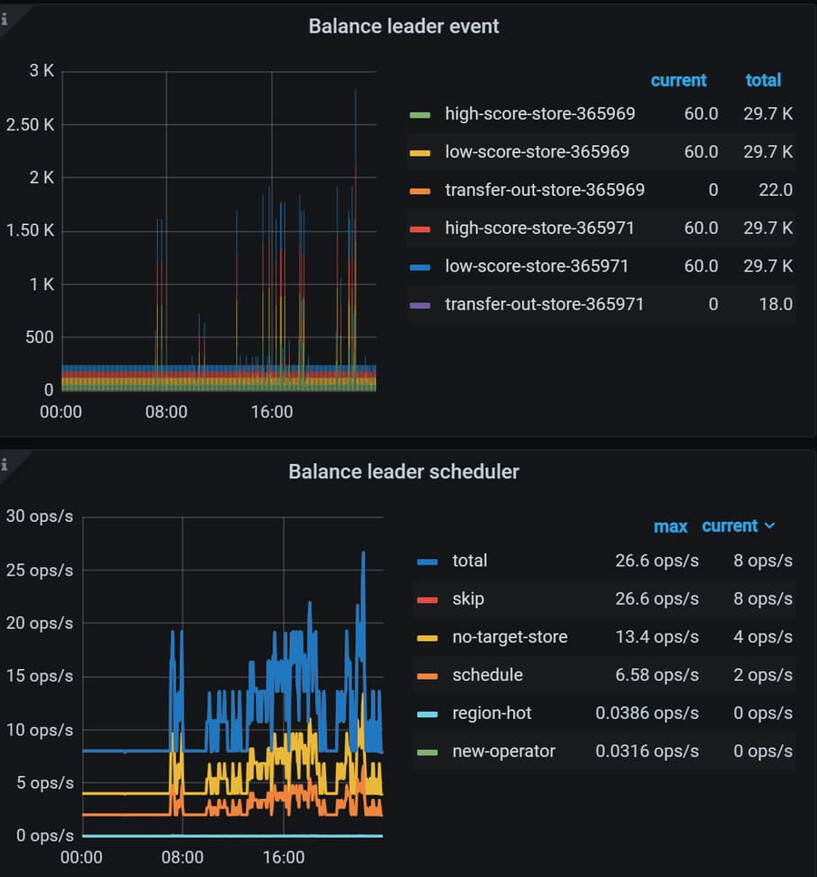
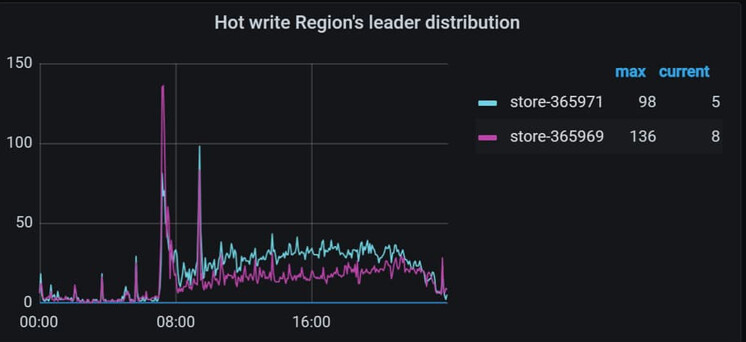
看看region的调度情况,有没有大批量region迁移
h5n1
(H5n1)
3
看下overview或tikv-detail页面的coprocessor executor count 再那个时间有对应增高不,如果有那就是有大数据量传输的SQL执行
业务访问QPS怎么样?大SQL、大查询呢?
如果有大查询,也会从tikv读取大量数据的,这种情况需要结合业务的读写访问一起查看。
附件 html 文件就是 region 调度相关监控页面,感觉不高的,大佬再给看看呢
如果是业务访问的流量,那应该是 tidb 跟 tikv 之间的吧,tikv 也是出的流量大。可监控显示是 tikv 的进流量大,有点没想通
h5n1
(H5n1)
10
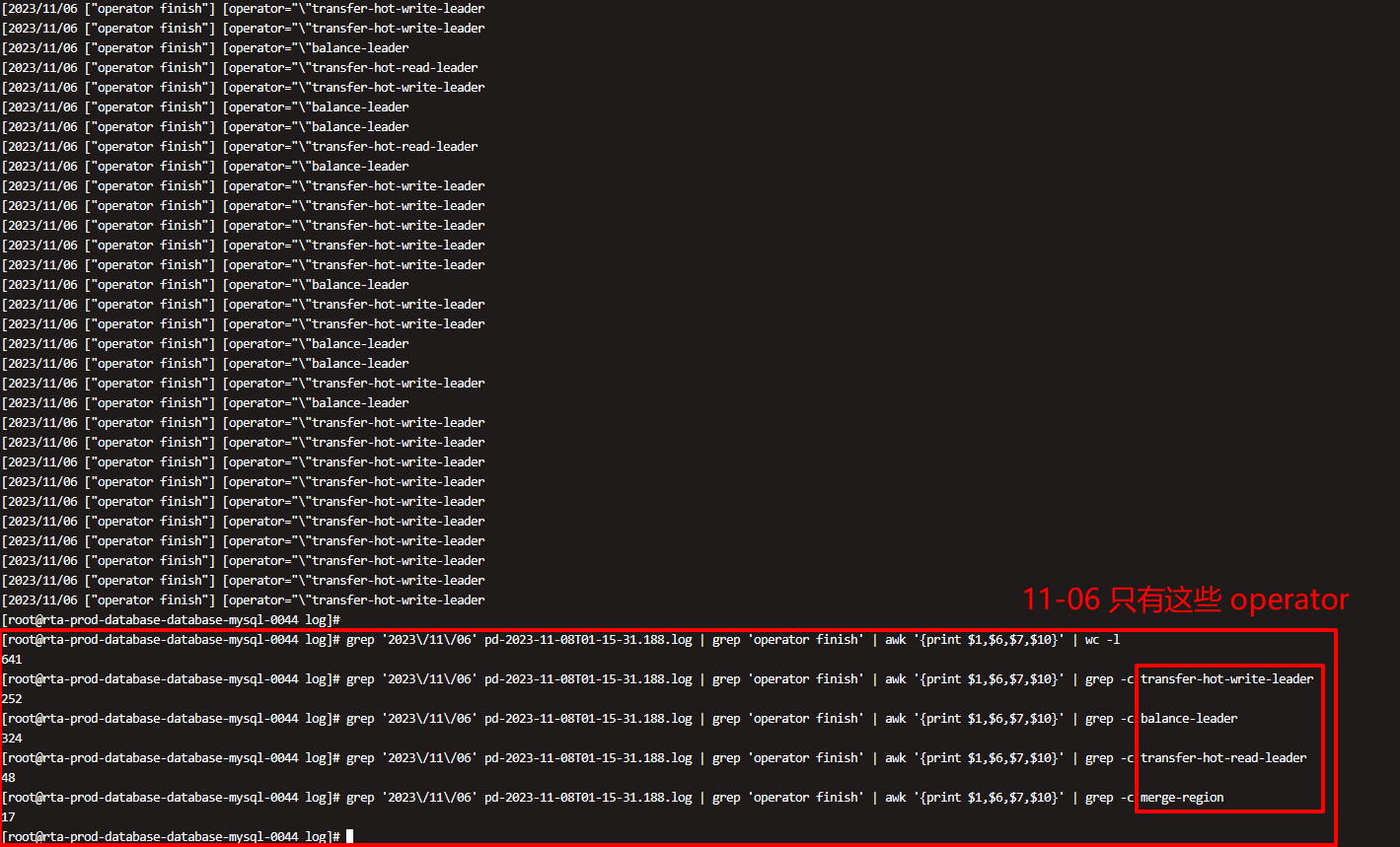
再pd leader看下pd.log 按时间和store找下每个store add peer的量 ,大概如下
grep ‘operator finish’ pd.log|grep ‘add peer’|awk ‘{print $1,$2,$14}’|sed -e ‘s/:[0-9][0-9].[0-9][0-9][0-9]//g’|sort|uniq -c
看了下,没有 add peer 相关操作,11-06 这天只有这些
同时看了下 11-06 这天所有的 operator=xxx 类型,只有这些。grep ‘2023/11/06’ pd-2023-11-08T01-15-31.188.log | egrep ‘operator=“\”[a-z-]{1,}’ |awk ‘{print $6,$7,$9,$10}’ | sed ‘s/[takes=.*s]//g’ | sort | uniq
h5n1
(H5n1)
12
你的流量大 是指的这一天比平时都大吗? 如果是这样的话那还是Leader 均衡导致的
你这4-20M的流量也不算大吧
1 个赞
舞动梦灵
(Ti D Ber Nckmz Hmh)
13
可以参考一下我之前遇到的:但是你这个干那感觉不大,参考一下平常的最近7天1个月的这个日常使用量。
阿里云监控告警,平常流量很少只有几兆。经常告警400M -700M之间,让系统运维查了一下。是哪几台机器之间互相传输,发现是pd发送tiv几K几M到kv。kv到pd是百兆。。我猜测就是sql问题,去看了一下dashboard里面监控的sql慢查询和sql流量分析 都有一个sql再查。show processlists grep一下只看query的,发现这个sql一直存在。就让找这个sql是谁负责的开发,让他停了,结果是因为他的sql因为某个表多了一个数据,导致频繁循环查询陷入死循环。
1 个赞
一直这样大,这套 tidb 只有 replace into / select 操作,没其它的业务操作了。 tikv 存储节点一天也就涨 15G 左右,但流量就这么大,感觉不太正常
sql 查询的话,正常都是走 leader tikv 节点的吧,tikv 节点间会有大量的数据交互吗
h5n1
(H5n1)
17
通过存储增长分析网络异常有点不合理吧,tikv有compact会释放空间的
tikv建的流量就是region/laeder转移是发送region的snapshot时比较多
1 个赞
8 点前看监控操作很少的,但流量还基本有 5M/s 左右
根据存储增长来分析网络流量是不大合理,但可以参考下的吧,现在两者能差 20 倍左右呢,有点离谱。或者有什么其它的方法来更加合理的分析下呢
h5n1
(H5n1)
20
你这就是8点后业务量开始起来,region做均衡调度