【 TiDB 使用环境】生产环境
【 TiDB 版本】
v6.5.2
【复现路径】做过哪些操作出现的问题
从 v6.5.1 升级到v6.5.2
【遇到的问题:问题现象及影响】
cdc 占用内存很大,总是oom被kill掉,v6.5.1没有这个问题,占用内存没有这个版本大
【资源配置】
【附件:截图/日志/监控】
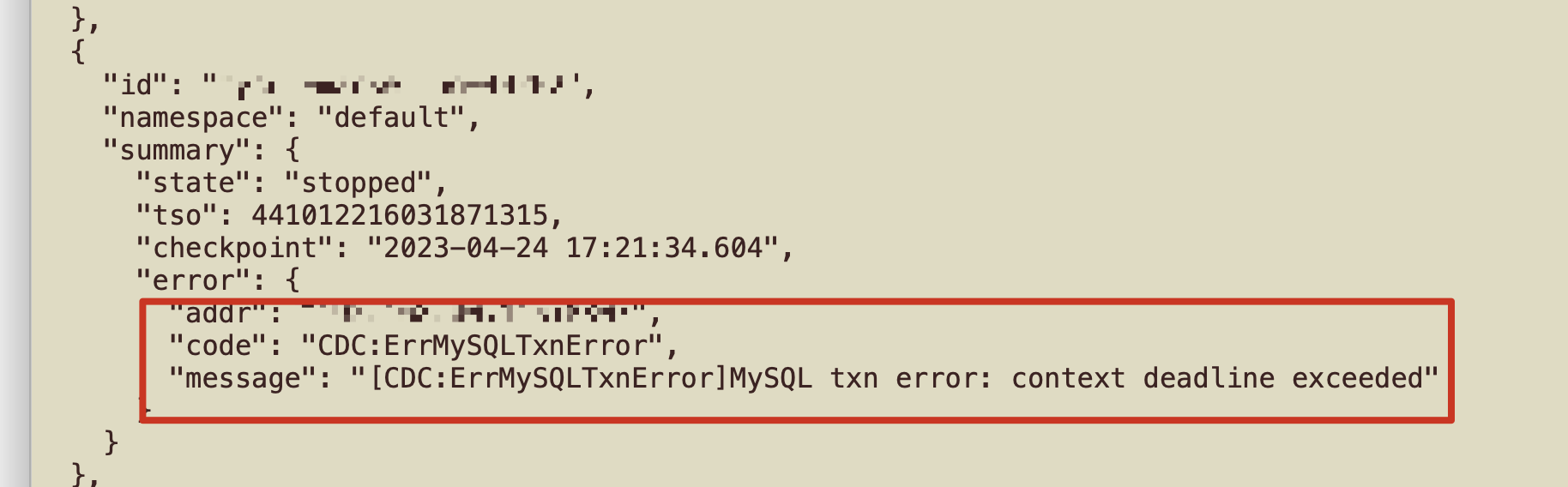
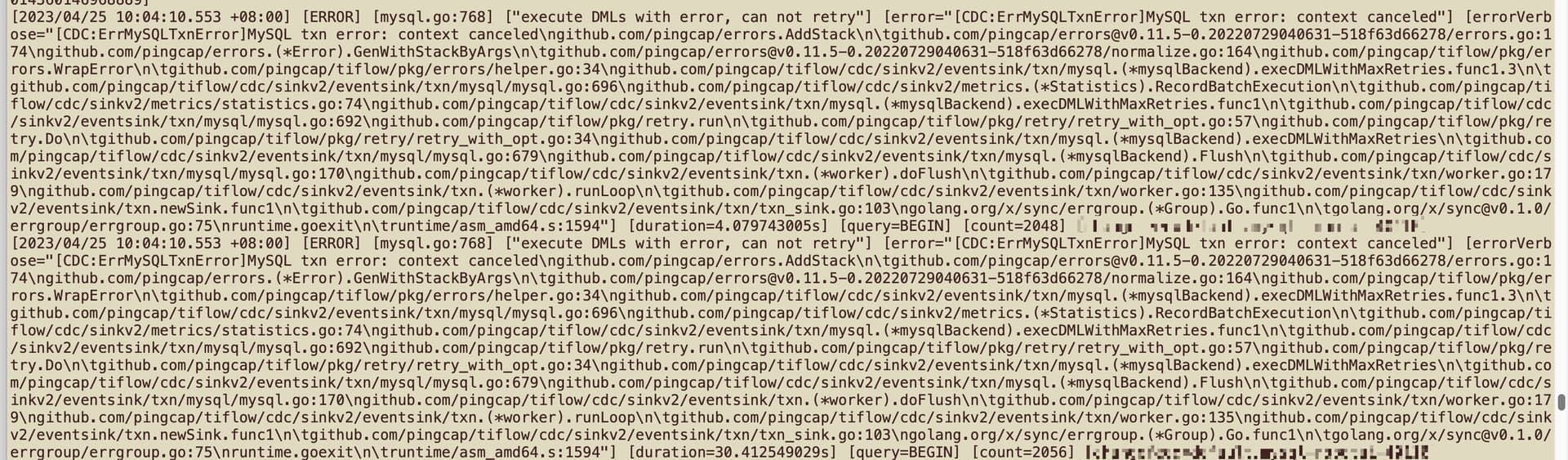
–cdc 日志报这个错
【 TiDB 使用环境】生产环境
【 TiDB 版本】
v6.5.2
【复现路径】做过哪些操作出现的问题
从 v6.5.1 升级到v6.5.2
【遇到的问题:问题现象及影响】
cdc 占用内存很大,总是oom被kill掉,v6.5.1没有这个问题,占用内存没有这个版本大
【资源配置】
【附件:截图/日志/监控】
这个错误貌似是下游的场景不支持导致的吧
tidb 的大事务有没有做拆分设置? 以此来保证mysql 在接收时,不会因为事务过大…
查下下游,mysql 是否正常,看看日志,对比下时间发生的情况是否一致
顺带查下 mysql 这边有什么错误
恭喜~ ![]()
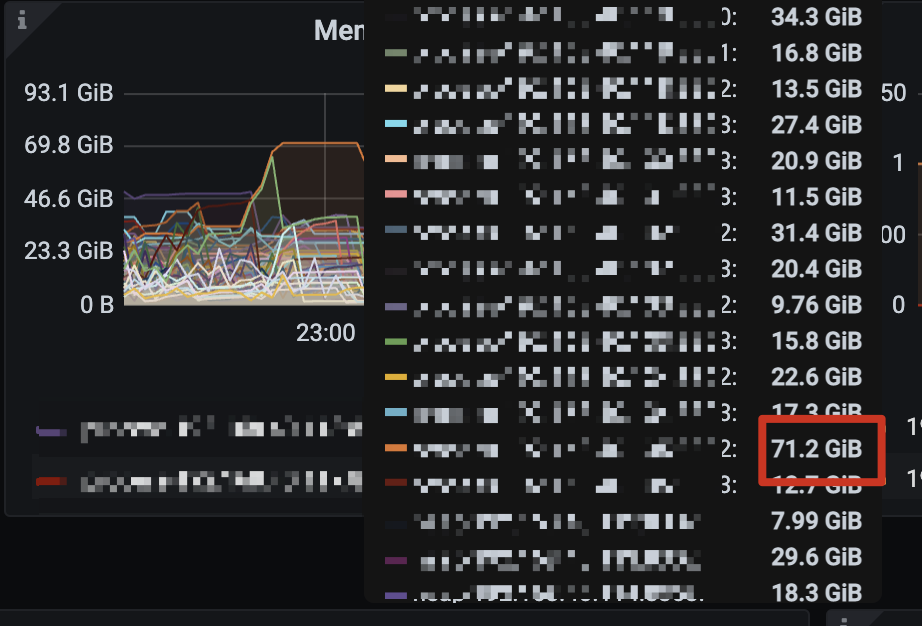
但是每个cdc server 内存使用量还是很高,容易OOM,哪个参数可以控制cdc server的内存使用
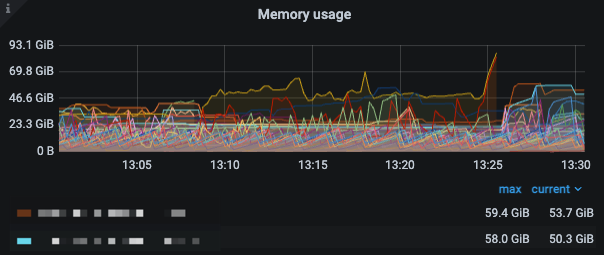
那要分析下,changefeed 和 资源之间的匹配是否足够?
查询是否有较大的同步延迟,导致数据在内存中堆积?
https://docs.pingcap.com/zh/tidb/stable/monitor-ticdc#changefeed-面板
查询那些任务会导致堆积异常
https://docs.pingcap.com/zh/tidb/stable/monitor-ticdc#events-面板
如果资源确实不够,那只能考虑扩容了
现在确实有延迟,延迟一天多了,但是我记得上个版本v.6.5.1内存使用量没这么高,之前也是延迟一天多恢复的
那解决延迟问题,内存问题就解决了 ![]()
per-table-memory-quota = 10485760 # 10 MiB
https://docs.pingcap.com/zh/tidb/stable/ticdc-server-config
这个参数放在yaml文件里面报错
6.5.2 控制内存的参数是:在 changefeed 的 config 设置 memory-quota=xxx。它的默认值现在是 1G。
你们是几个 changefeed?可以把它调小点。
4个changefeed,那也不应该占用80多G
用我上面发的那个参数,changefeed 的配置,不是 server 的配置:memory-quota=xxx。
升级之后 lag 很大吗?
内存使用量比6.5.1大很多,之前没到80多个G,等追上再看看延时吧,应该差不多
对我知道,但是现在cdc_server 出了一个这个参数 per-table-memory-quota,不知道怎么用
6.5.2 这个参数现在没生效了。不好意思,文档滞后了,我改改。
你们一台机器配置多少,部署了几个节点啊?