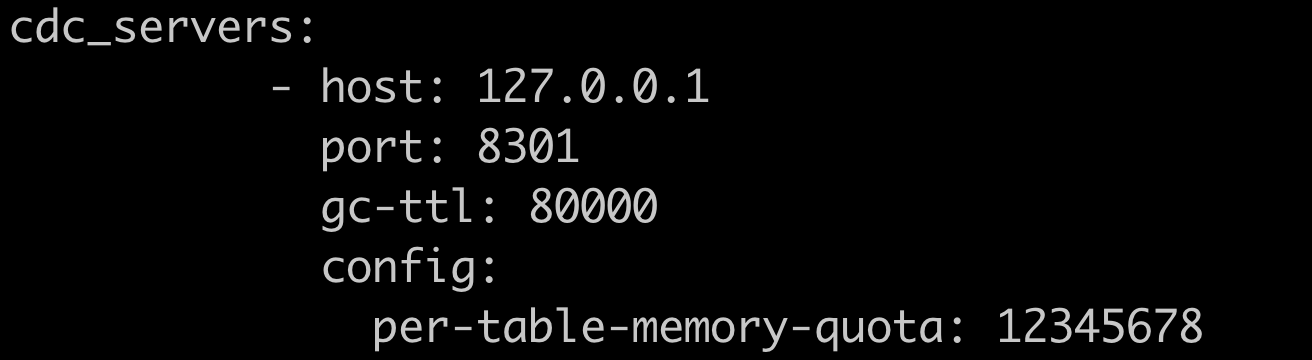
补充下,虽然这个参数失效了,但是依然是可以配置的,这种 server 级的参数在 tiup 中可以配置在 config 里面,类似下面这样:
多谢,我试试
就是这个参数per-table-memory-quota
在v6.5.2不管用了是吧?
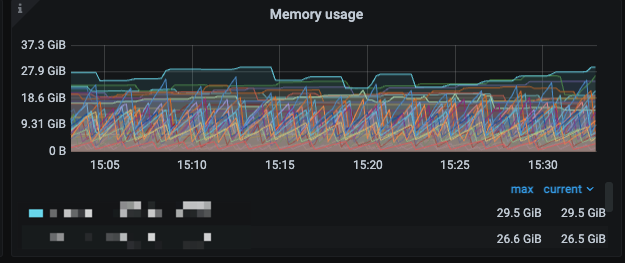
19个cdc_server 在内存比较多的机器上,昨晚部署在tikv server 上,占用很多内存,导致tikv节点被kill,然后又scale-in 了,现在还19个 cdc_server在tidb server上,之前内存会占用80G,然后就被kill 掉了,现在一个小时最大差不多30G,一个cdc_server 处理150个表左右,想用这个参数per-table-memory-quota控制一下总内存
那个参数不管用了,不过你们为啥要部署 19 个 cdc_server 呢?是有很多表,然后想每个 cdc_server 处理不同的表,表同步不相互阻塞吗
不会,现在我又扩了4个cdc_server 现在23 cdc_server个,我们2千多表,上午下游mysql死锁了,6.5.1 我们这个参数max-txn-row 设置的5000没有死锁,升级到6.5.2之后会出现死锁,改成100,现在没有死锁了,cdc_server少了,会占用很大的内存,多个cdc_server分散一下
per-table-memory-quota 这个参数失效了有没有一个参数控制cdc_sever的总内存,防止cdc_server 占用太多内存被oom kill
就是我上面说的参数,可以通过在 changefeed 中配置 memory-quota=104857600,将每个 changefeed 的总内存限制一下。
例如:
memory-quota=104857600
- 暂停 changefeed: cdc cli changefeed pause -c changefeedID
- 更新 changefeed: cdc cli changefeed update -c changefeedID --sink-uri=“xx” --config=changefeed.toml。注意不要更新到其他不想改的参数了
- 恢复 changefeed: cdc cli changefeed resume -c changefeedID
现在worker-count=32 是不是相当于一个cdc_server启动32个进程去同步数据,看到是这样,然后这个memory-quota=104857600 是控制一个链接的内存还是整个changefeed的内存,看我这里这个参数是1G,总共4个changefeed 那cdc_server为什么使用了80G内存
这是每个 ticdc 实例上每个 changefeed 的总额度。
例如:你现在有 4 个 changefeed。 32 个 ticdc server。
那么每个 changefeed 都会分配几张表到每个 server 上。
那么理论上消耗的内存就是: 4 * 32 * 1 G = 128G。但是上面说的这些内存限制都是针对 sink 模块的。你遇到的问题应该是 sroter 模块拉数据和缓存数据到内存造成的。
因为你现在是所有的 ticdc 混布,你需要用 cgroup 正确限制内存资源,否则就会导致 TiCDC 拿 host 的 70% 作为使用额度来在 sorter 模块中缓存数据。
更多细节可以参考这个 issue:https://github.com/pingcap/tiflow/issues/8588
如何使用 tiup 限制内存使用:https://docs.pingcap.com/zh/tidb/stable/tiup-cluster-topology-reference#global 中 resource_control 配置。
是的,sorter阶段 ,拉数据和缓存数据到内存造成的,数据都排序完成,内存就正常了
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。