【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】持续读写,没有任何操作
【遇到的问题:问题现象及影响】
tikv-server 内存持续增长,组件触发oom
【资源配置】
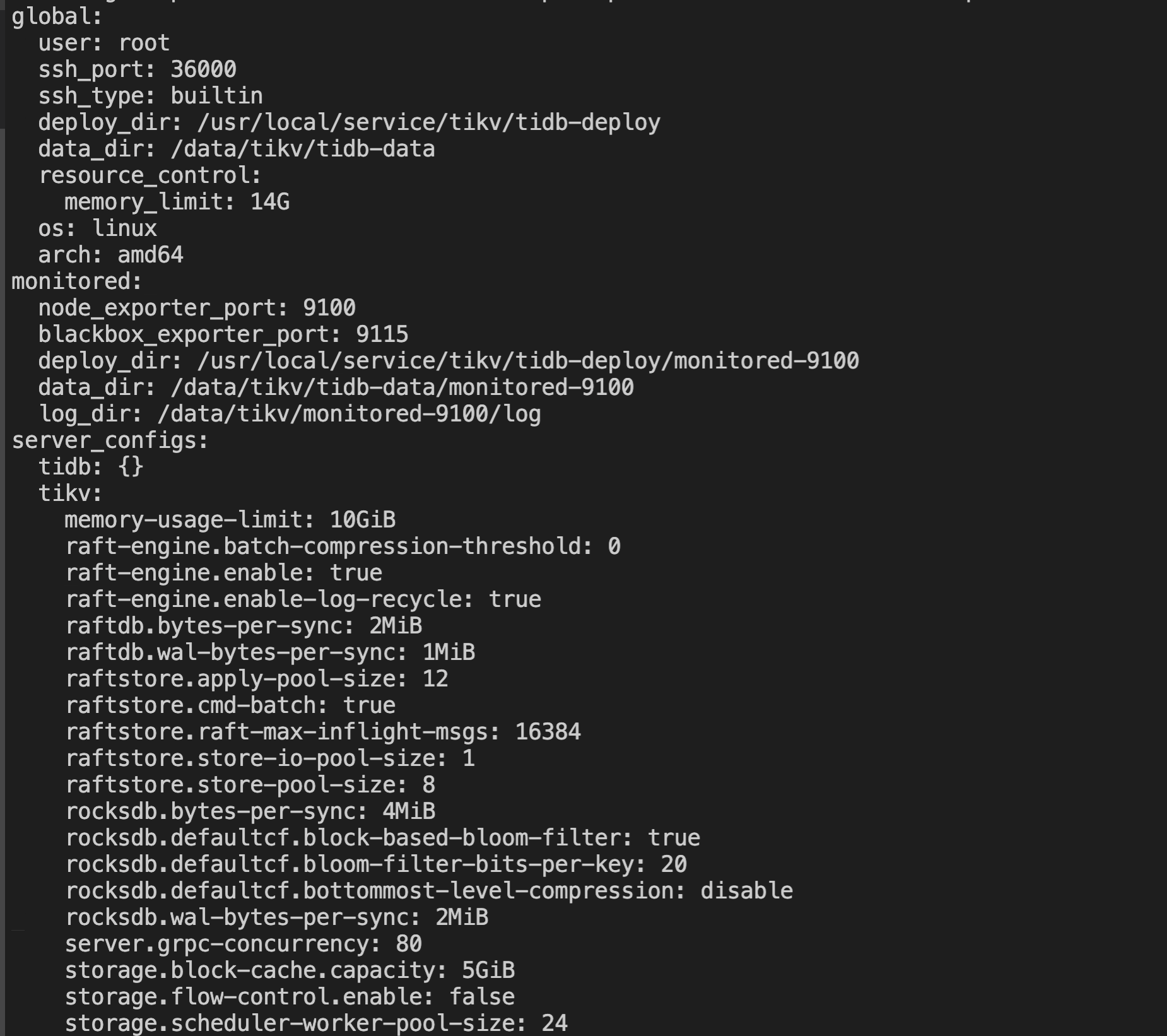
pd、tikv server 混部,3*[48 core 128GB 内存 3.75TB *1]
【附件:截图/日志/监控】
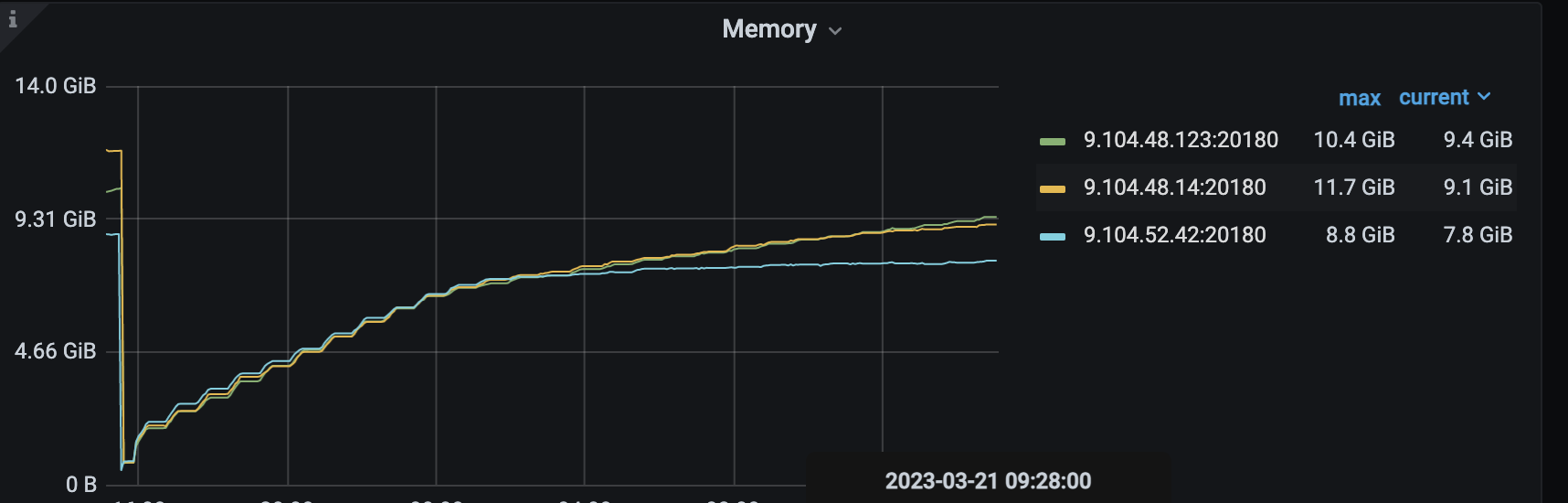

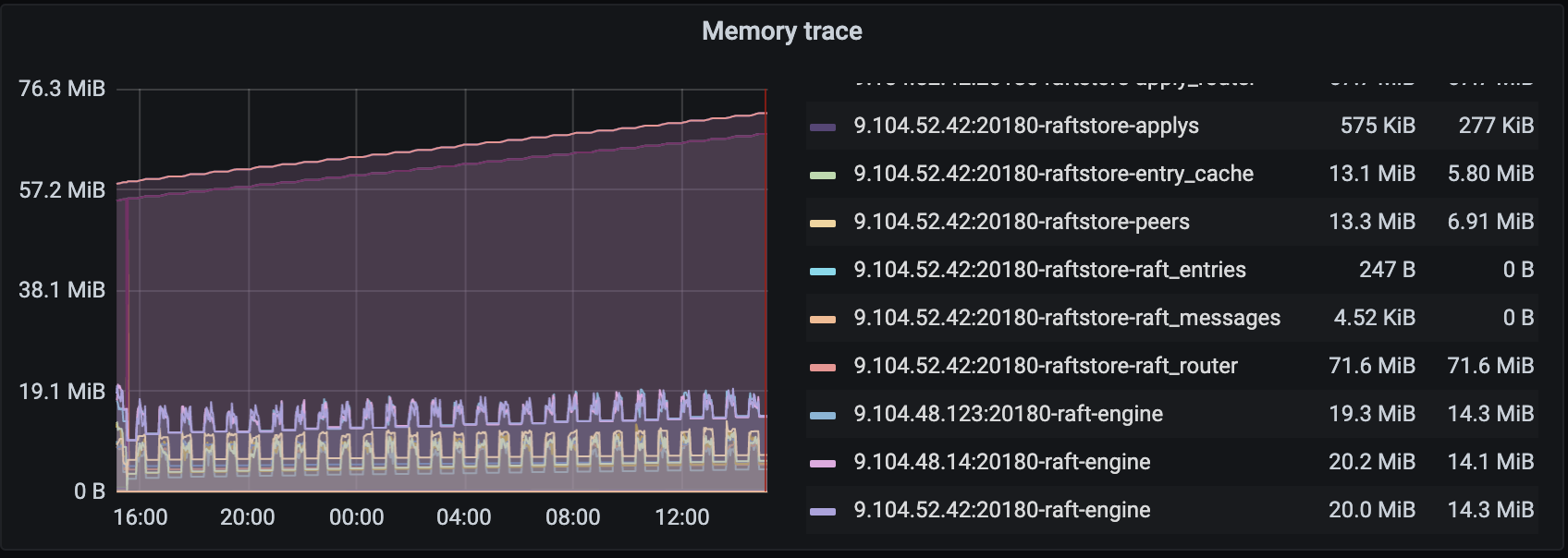
目前tikv 6.5.0 性能较好,其他方面比较稳定,只有内存在持续增加,希望尽快能够得到专业的研发同学一起排查和解决
混布? 怎么混法?
pd 和 tikv-server 混部:三台机器,每个机器 一个pd,一个tikv-server
不知道有没有内存泄漏的可能,限制了memory_usage_limit 都没用,而且看memory_trace + block cache 也没到监控内存那么高,三台机器都关闭了THP. 还是不行,有内存在持续增长。
补充一下没有巨型region 【tp99 -200多MB】,多数region 是hibernate 的,每台server 活跃的region 只有50 到 60个,这与我们的预期相当,我们做了hash 分路限制,所以心跳也不是影响内存的因素。读写符合潮汐流量,有高峰低谷

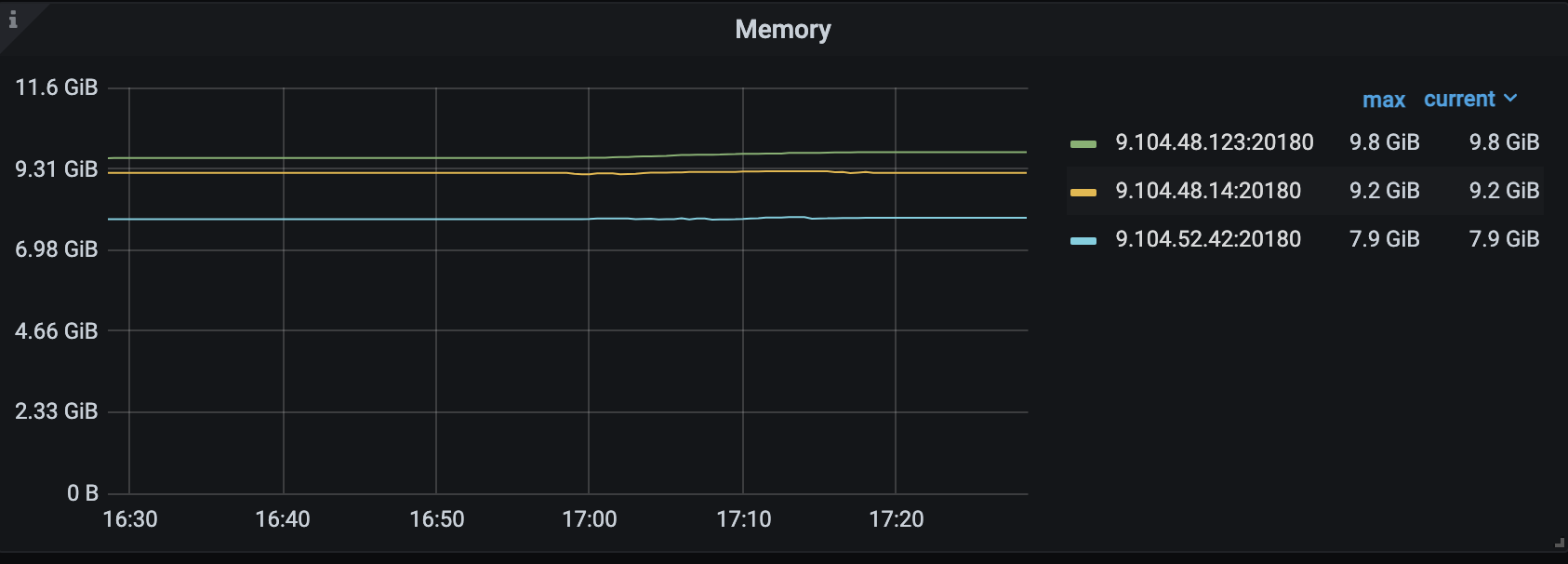
没 tidb 节点么?
估计是没 GC 导致的,弄个 tidb 节点的实例就好了… ![]()
你指的是MVCC的gc吗,这个在哪里会导致内存飙升呢?我们用tikv 不用tidb的,搭tidb 有成本问题

请问这个gc 是指哪里?我去看看代码,看看是否有没触发内存回收的风险
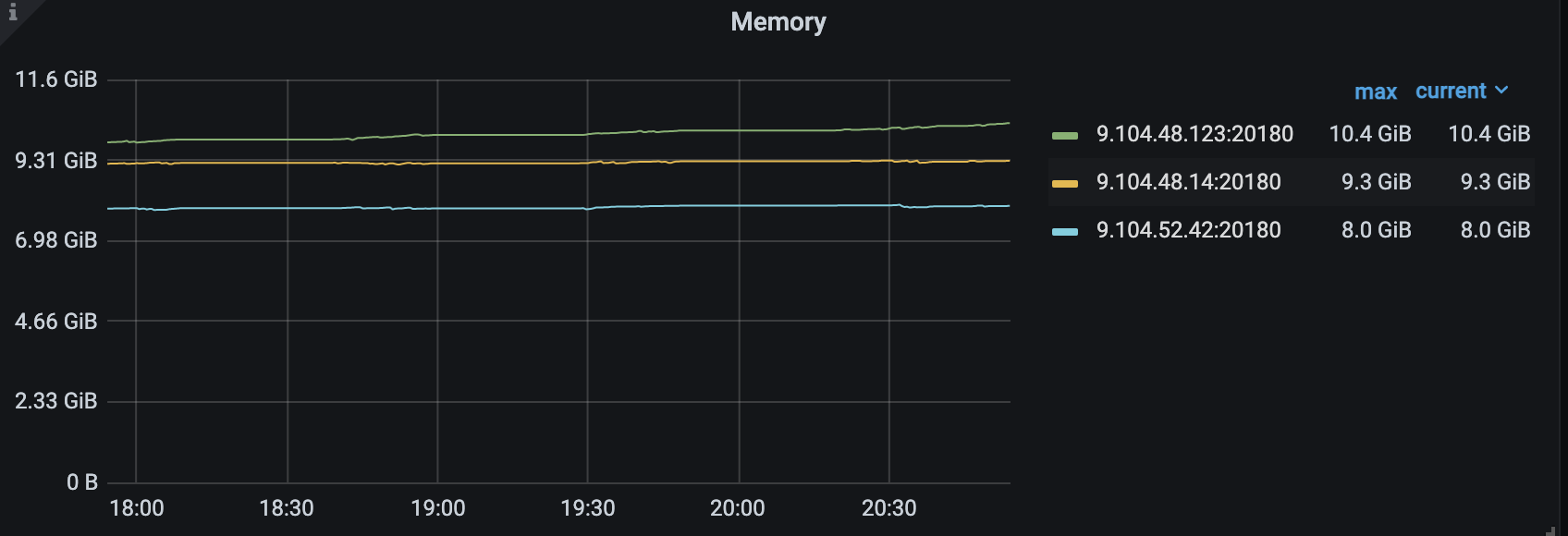

哦,我们搞过rocksdb,现网有很多rocksdb 的产品,TiKV 的mvcc 是基于rocksdb 做的吧,default 、write、lock 和 raft cf,而rocksdb 内部一个key 写多个,和内存没啥关系吧
补充限制,限制了raft_engine.memory_limit = 1GB,server.grpc-memory-pool-quota= 2G, block_cache_capacity = 4G, memory_usage_limit = 8G, 理论来说 1+2+8 最大内存应该是11GB,如果超过集群静默情况下超过这个值,而且随着写入仍然内存仍然疯涨的话,就可以确认出现内存泄漏了。


不太清楚6.5的 memory-usage-limit 是怎么实现的,你看看rocksdb的memtable有没有设置?memtable也占不少内存。rocksdb-raft rocksdb-kv 两套rocksdb,都设置了吗?
rocksdb占内存比较多的2块:blockcache、memtable
你看看这俩有用么。
