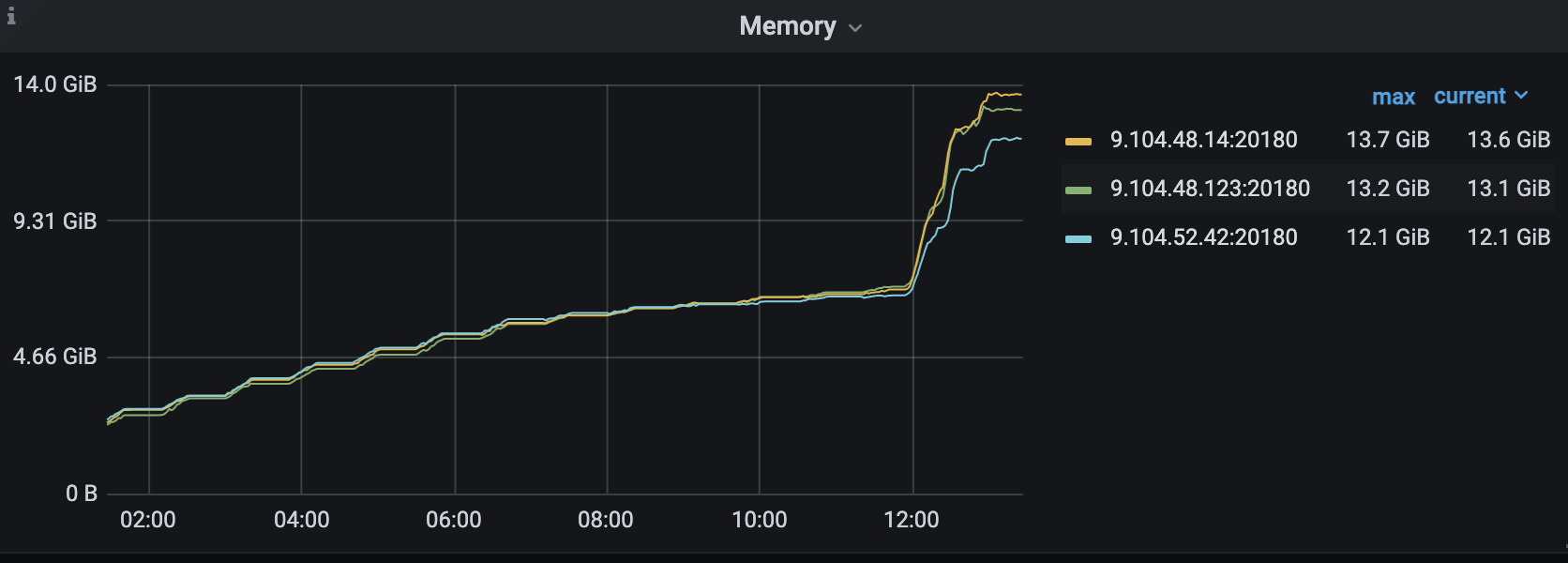
能看到监控的内存,我都看了,加起来根本到不了那么高,反而我现在compact write cf,内存在疯狂的飙涨,所以在怀疑是不是rocksdb的compaction 导致的内存飙涨。
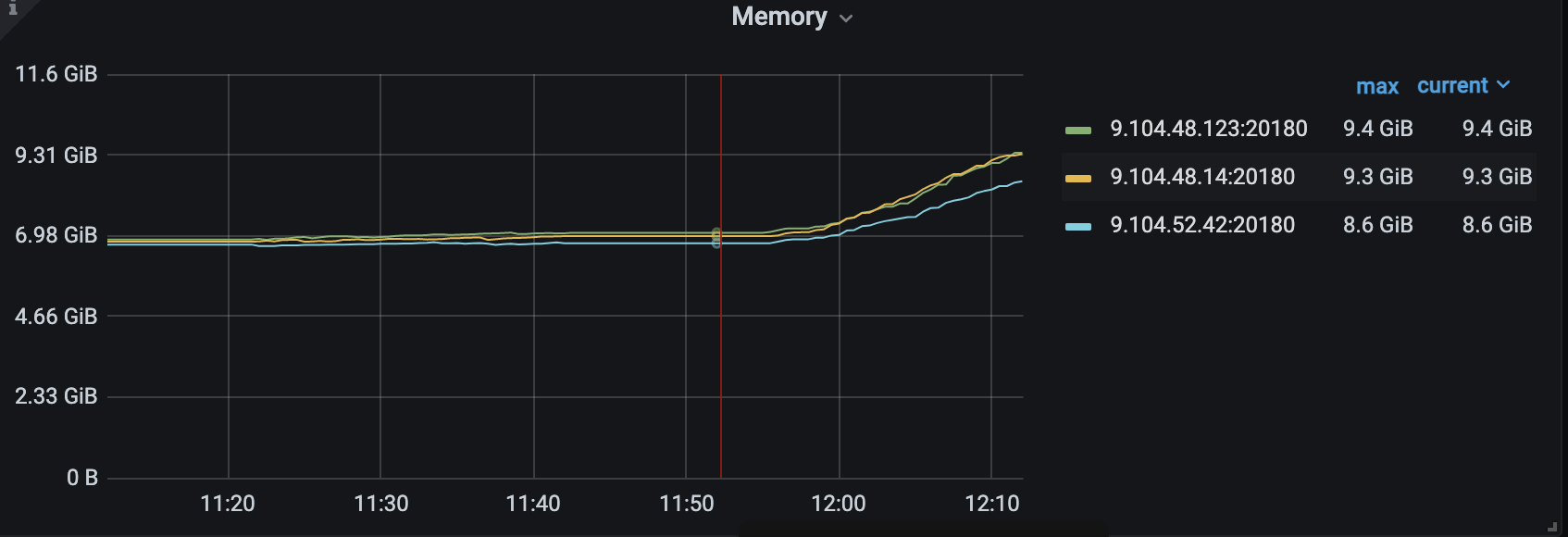
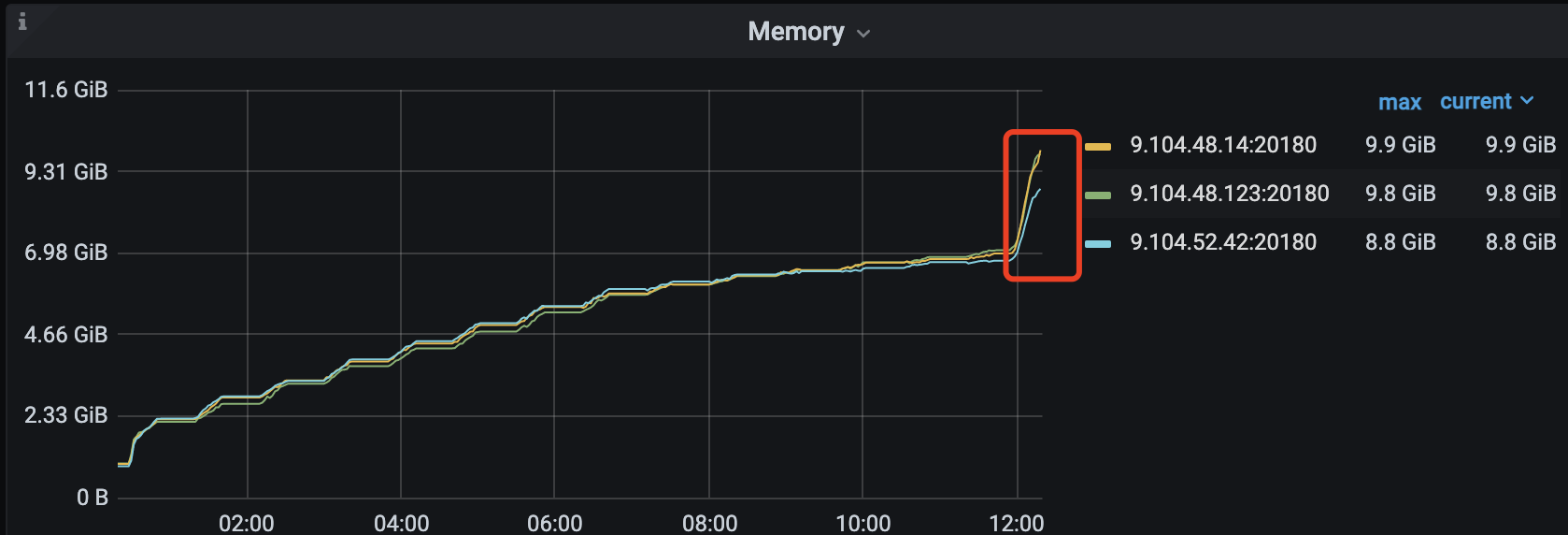
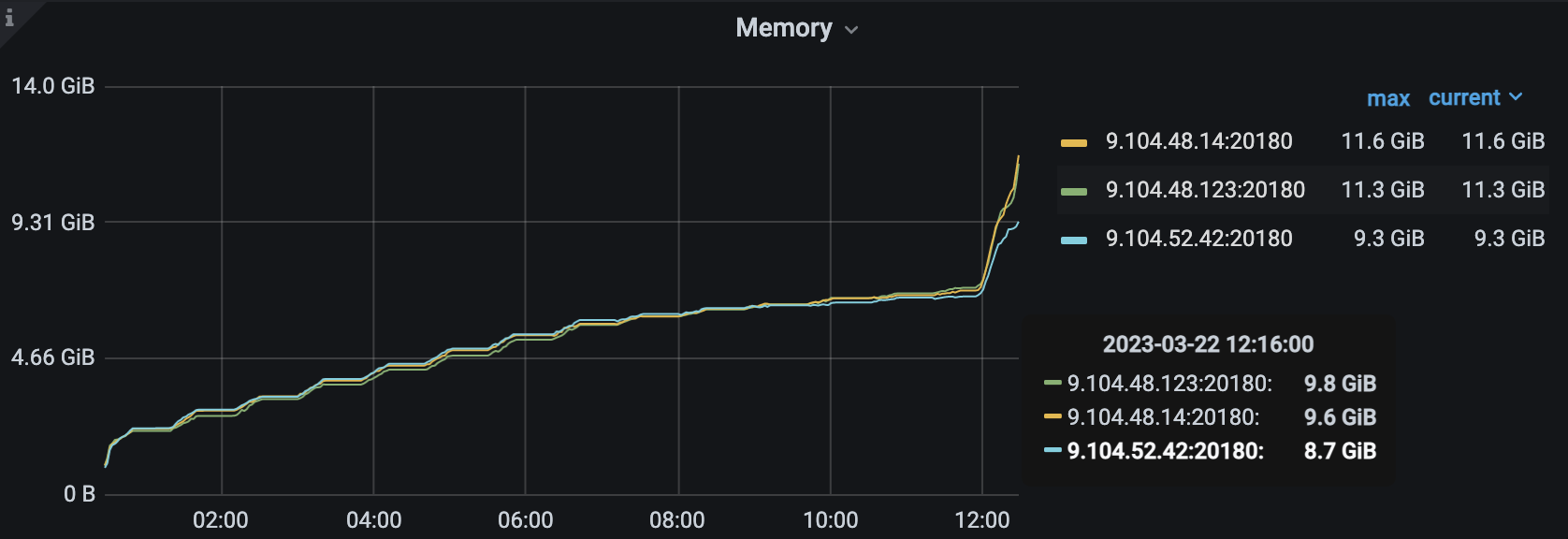
hello, 从现象来看,是相反的,触发compact 反而会导致内存飙涨,不会释放内存,具体来看是tikv 自己封装的rocksdb 肯能有内存泄漏,rocksdb 社区版我们经常用不会有问题
top看看,是不是真占用那么多。还是tikv自己统计错了。
别的我也不知道还有什么了 ![]()
top 已经确认过了,确实有那么多,刚刚已经oom了,我正在重新编译tikv 打开profile 看看
不知道你是什么类型的应用场景,混布的方式本身就存在资源竞争…
可以看看 PD 的服务实例 是否正常…
OOM 日志上描述的是什么问题导致的?
我加了resoure_limit 只给他分配14GB 内存,看/var/log/messages 就是因为超过14GB 被kill 了,pd 都是正常的,现在在做dump 看看为啥内存上来,降不下来,场景的话,我们用tikv 做文件系统的元数据
juiceFS ? ![]()
不是,我们纯自研,juiceFS 满足不了我们的场景
region 数量是否均衡? 其中一台特别容易 OOM ?还是 3个节点都容易…

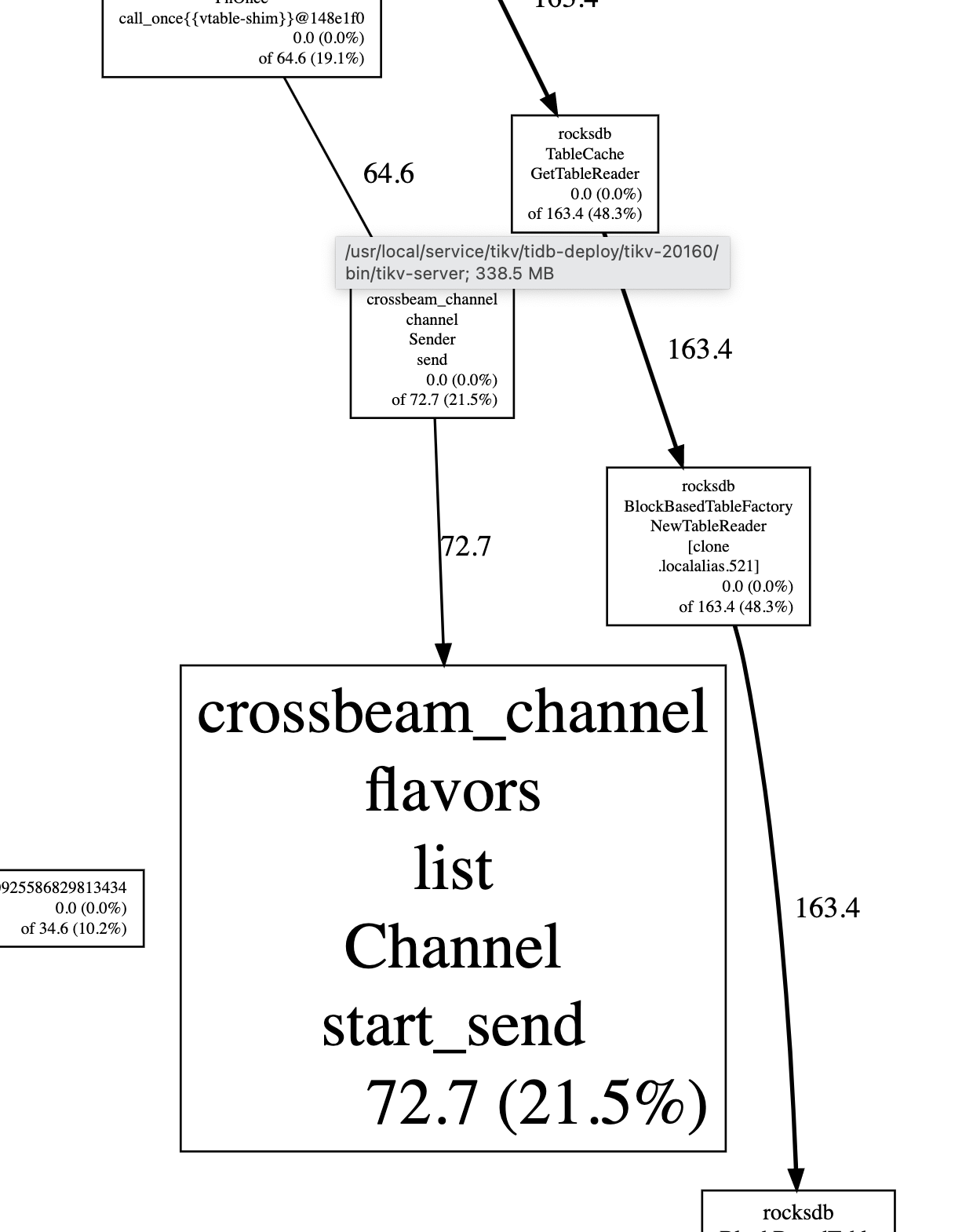
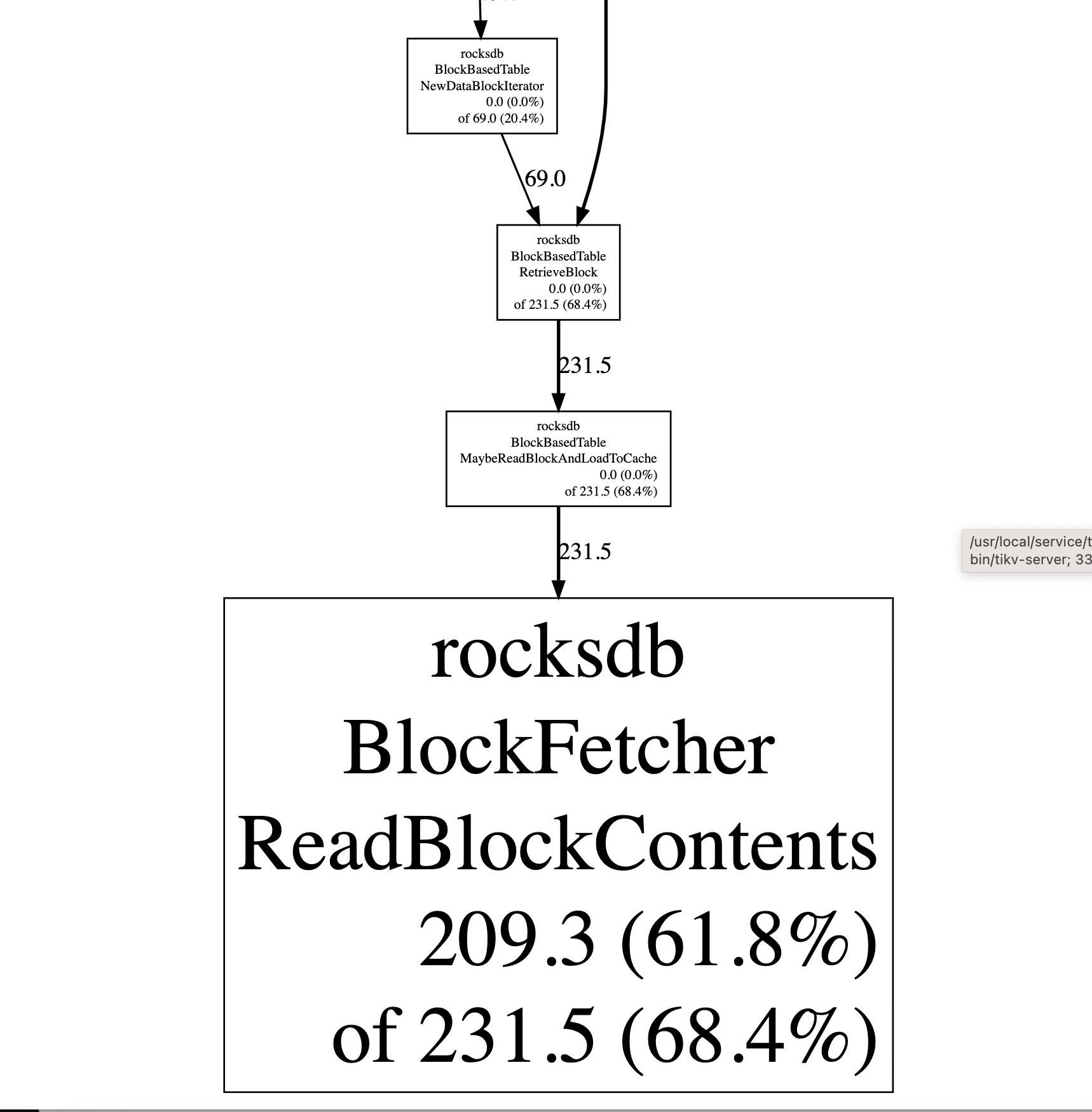
没有读写持续增长?那估计多半是内存泄露了
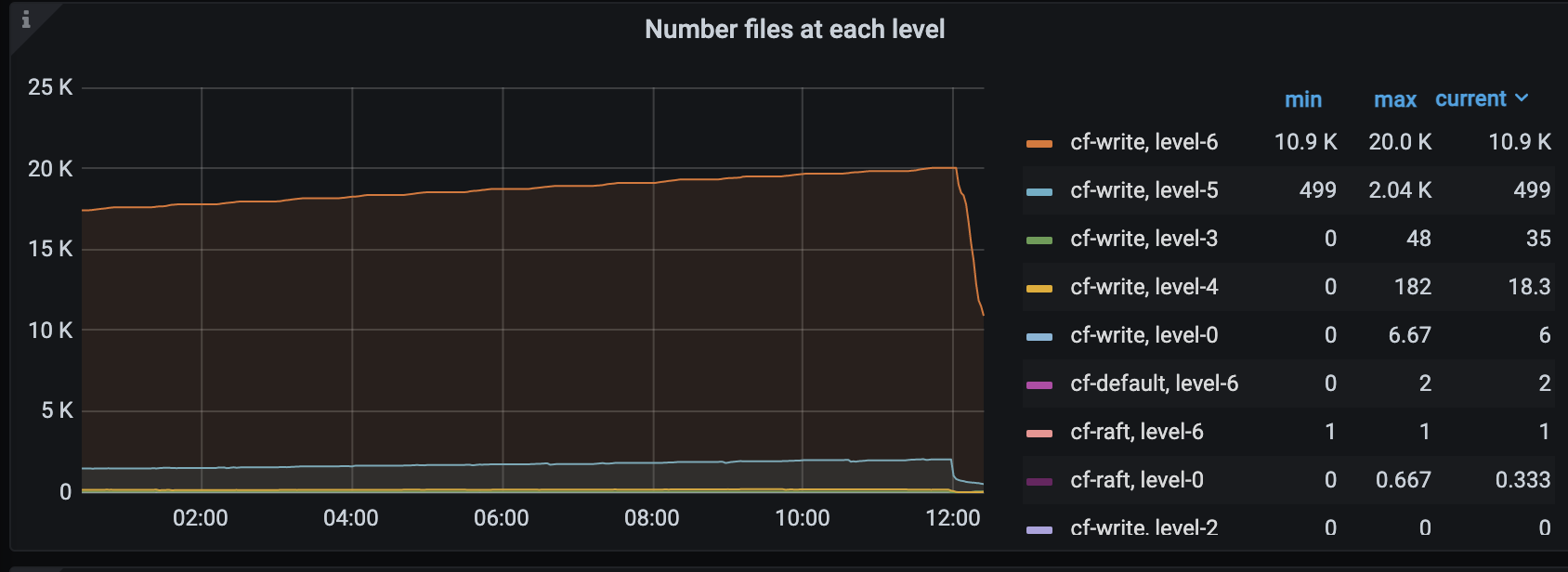
我dump 分析出来每次都会缓慢增长一点crossbeam_channel 下的start_send ,这里会持续增长
https://github.com/tikv/tikv/issues/14114
感觉你的问题和他的描述类似,
With tablet flow control enabled, the issue is mitigated.
The root cause is that the memory flush cannot catch up the write speed and data are queued in memtable. So the memtable grows above the quota. With flow control enabled, the pending L0 files will slow down the region’s speed automatically and thus reduce the memtable’s write volume. Now it can run tpcc 25K for 6hours with memory stable
简单说就是 从内存刷盘太慢了,赶不上写入的速度,导致内存异常的大…
你要开启流控才行了~ ![]()
我尝试看看开启流控看看