wakaka
(Wakaka)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.6
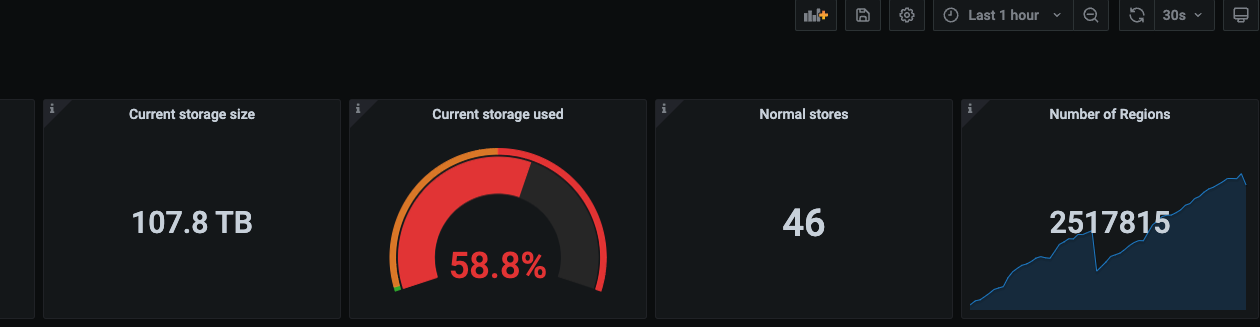
【复现路径】 pd监控和数据字典查出来差距较大,并且出现null的库名占用
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
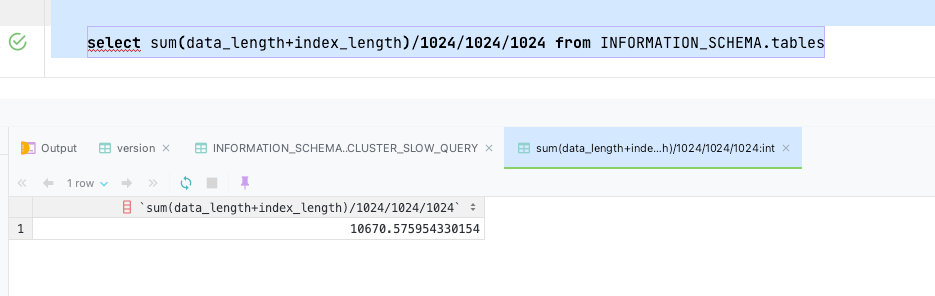
1、查tables,不到10T
select sum(data_length+index_length)/1024/1024/1024 from INFORMATION_SCHEMA.tables;
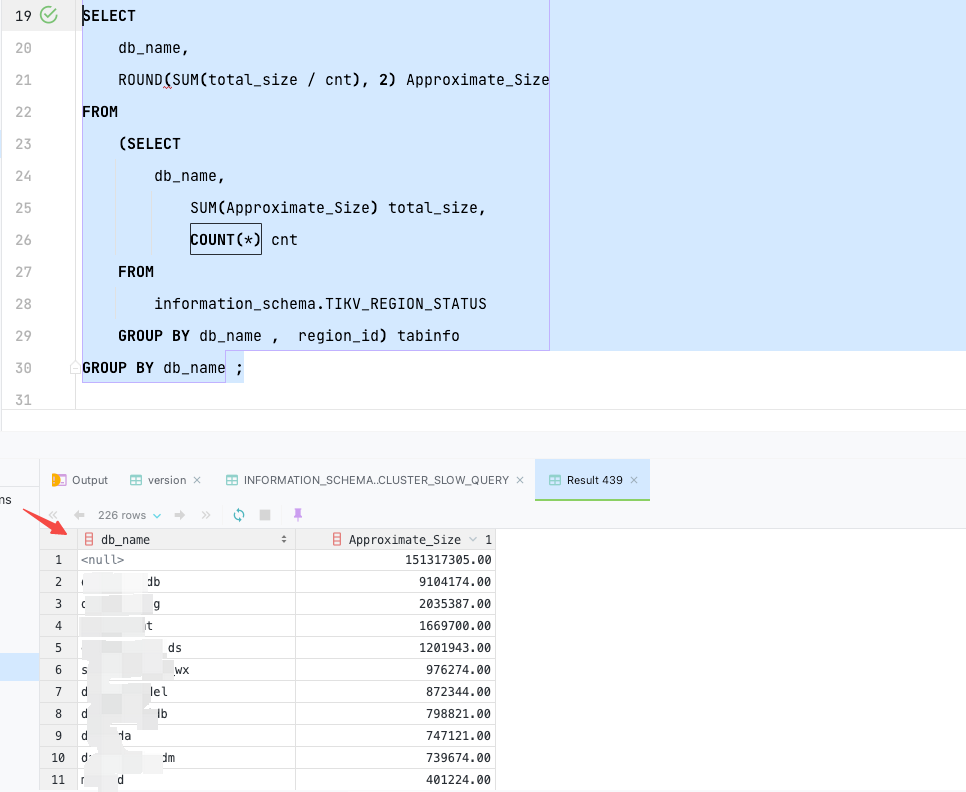
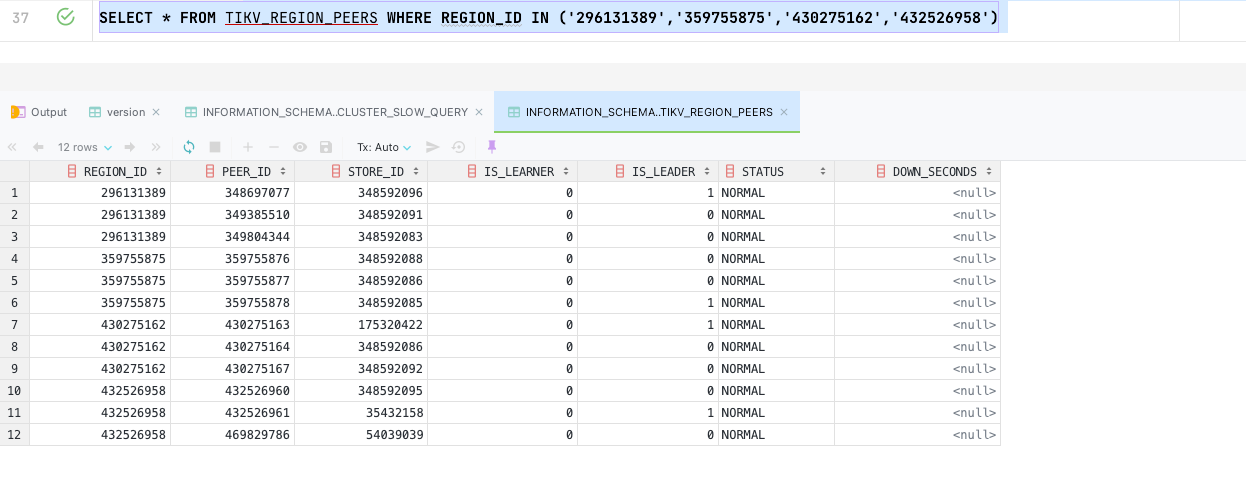
2、查TIKV_REGION_STATUS,除去NULL,加起来不到30T
问题有两个:
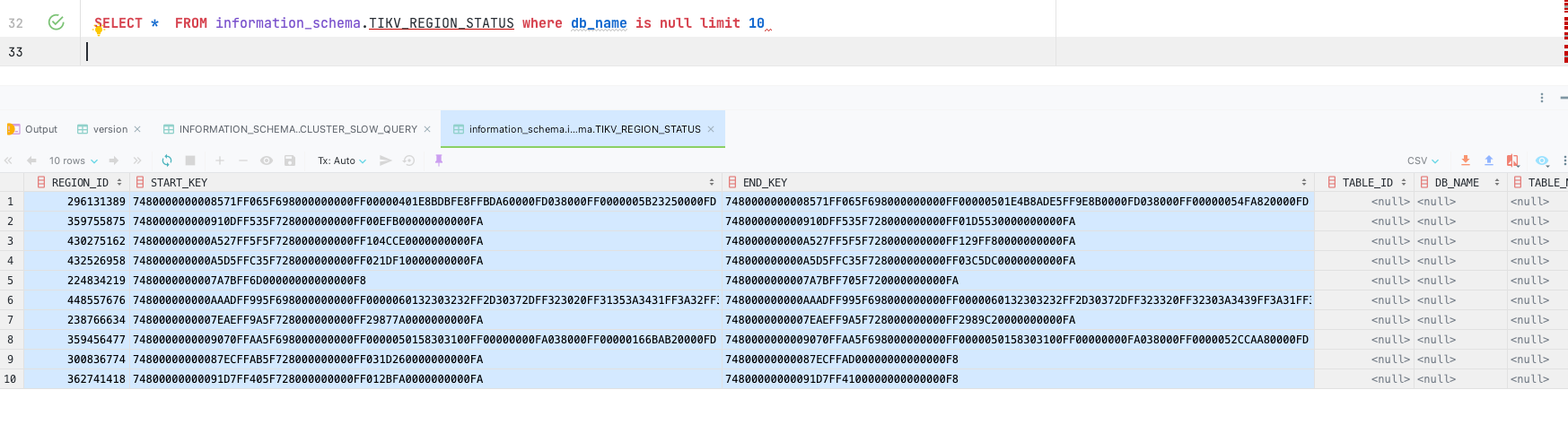
1、db_name是null的是什么导致的?
2、pd的100多T和数据字典的差距太大是什么导致的,如何解决?
wakaka
(Wakaka)
3
这个就是我发的帖子,但是管理员可能觉得时间太长了帮我设置最佳答案了。感觉不太对。差距太大了,30T和100多T
Kongdom
(Kongdom)
5
对,检查一下空region,我这边有个集群就出现实际空间还有,但grafana里显示空间不足,就是空region太多,导致grafana中的数值,和centos里看到的数值差异太大导致的
wakaka
(Wakaka)
6
空region问题之前也发过帖子,空region不合并
wakaka
(Wakaka)
7
空region问题之前也发过帖子,空region不合并
Grafana的统计也包含了tiflash的数据量
WalterWj
(王军 - PingCAP)
10
去 data 盘 du -sh -d 1 一下。物理存储使用统计最准。
Kongdom
(Kongdom)
11
我之前遇到的就是,物理存储比如是30G,但是grafana里是300G,结果硬盘是1T,三副本判断是已用900G,就显示节点空间不足,leader副本都被移走了,但实际看物理存储就是30G。
最后我通过备份还原重建集群,grafana就显示正常了。
wakaka
(Wakaka)
12
物理使用是100多T ,但是业务觉得不合理,不应该这么大。 想查占用高的库表,这一查就差这么多,而且删了大表空间等了一天也没释放
WalterWj
(王军 - PingCAP)
14
感觉不合理的话 看看 gc 是不是卡主了,比如 compact 关闭了,gc 调整不合理都有可能导致空间变大。
之前社区都遇到过。
wakaka
(Wakaka)
15
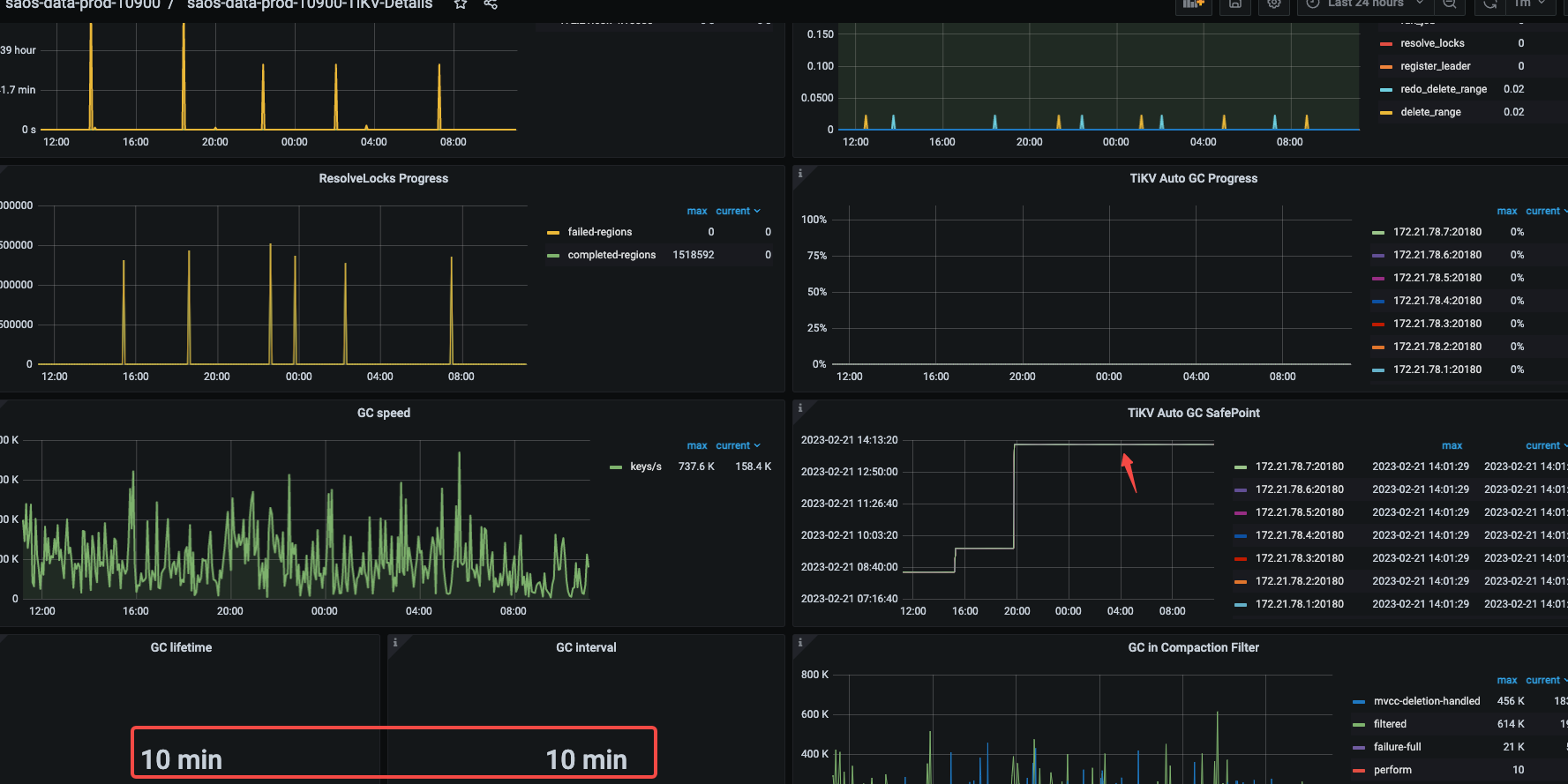
GC参数就是10分钟,compact没关闭 ,看着是昨天下午卡住了,那会进行了一些大表的drop操作
wakaka
(Wakaka)
17
嗯嗯,暂时先等这个GC完成,但是量差距过大这个一直问题都存在,不知道是不是GC回收的慢长久以来积压导致。 每次如果回收的速度太小感觉一直都会有回收不完的情况。有能提升GC的方法么
WalterWj
(王军 - PingCAP)
18
可以试试新版本,我记得有 compact filter 等优化。
wakaka
(Wakaka)
19
业务有大量的DDL,官方文档说升级期间不能执行DDL,这块还不好避免,除了升级还有别的办法吗?
胡杨树旁
20